Prediction-Powered Ranking of Large Language Models
2402.17826
0
0
💬
Abstract
Large language models are often ranked according to their level of alignment with human preferences -- a model is better than other models if its outputs are more frequently preferred by humans. One of the popular ways to elicit human preferences utilizes pairwise comparisons between the outputs provided by different models to the same inputs. However, since gathering pairwise comparisons by humans is costly and time-consuming, it has become a common practice to gather pairwise comparisons by a strong large language model -- a model strongly aligned with human preferences. Surprisingly, practitioners cannot currently measure the uncertainty that any mismatch between human and model preferences may introduce in the constructed rankings. In this work, we develop a statistical framework to bridge this gap. Given a (small) set of pairwise comparisons by humans and a large set of pairwise comparisons by a model, our framework provides a rank-set -- a set of possible ranking positions -- for each of the models under comparison. Moreover, it guarantees that, with a probability greater than or equal to a user-specified value, the rank-sets cover the true ranking consistent with the distribution of human pairwise preferences asymptotically. Using pairwise comparisons made by humans in the LMSYS Chatbot Arena platform and pairwise comparisons made by three strong large language models, we empirically demonstrate the effectivity of our framework and show that the rank-sets constructed using only pairwise comparisons by the strong large language models are often inconsistent with (the distribution of) human pairwise preferences.
Create account to get full access
Overview
- This paper explores a new approach for ranking large language models (LLMs) under uncertainty, using prediction-powered inference to construct confidence regions around model performance.
- The authors propose a novel technique that leverages the LLM's own predictions to assess its capabilities and uncertainties, providing a more nuanced evaluation compared to traditional benchmark scores.
- The paper demonstrates the effectiveness of this approach on several language tasks, offering insights into the relative strengths and limitations of different LLM architectures.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at tasks like answering questions, generating text, and understanding language. However, it can be challenging to accurately compare the performance of these complex models, especially when there is uncertainty around their abilities.
The researchers in this paper developed a new way to evaluate and rank LLMs that takes this uncertainty into account. Instead of just looking at the models' raw benchmark scores, they use the models' own predictions to estimate how confident they are in their answers. This allows for a more nuanced understanding of the models' strengths and weaknesses.
For example, an LLM might perform very well on a task when it is confident in its responses, but struggle when it is less certain. The prediction-powered approach can identify these patterns and provide a more complete picture of the model's capabilities.
The authors demonstrate the effectiveness of this technique across several common language tasks, showing how it can help shed light on the relative merits of different LLM architectures. This type of in-depth evaluation could be valuable for researchers, developers, and users who need to select the right model for their specific needs.
Technical Explanation
The key innovation in this paper is the use of prediction-powered inference to construct confidence regions around the performance of large language models (LLMs). Rather than relying solely on benchmark scores, the authors leverage the models' own predictions to assess their capabilities and uncertainties.
The approach works as follows:
- The researchers select a set of language tasks and input examples to evaluate the LLMs on.
- For each input, the LLMs generate predictions, along with some measure of their confidence in those predictions (e.g., probability distributions).
- Using the predicted confidence levels, the authors construct confidence regions around the models' performance on each task.
- These confidence regions are then used to rank the LLMs, providing a more nuanced assessment of their relative strengths and weaknesses.
The authors demonstrate the effectiveness of this technique on a variety of language tasks, including question answering, text generation, and semantic similarity. They show how the prediction-powered approach can uncover insights that would be missed by traditional benchmark scores alone.
Critical Analysis
The authors present a compelling approach for evaluating and ranking large language models that takes uncertainty into account. By leveraging the models' own predictions, the technique provides a more nuanced and informative assessment of their capabilities.
One potential limitation of the method, however, is that it relies on the models' self-reported confidence levels, which may not always accurately reflect their true uncertainties. There could be biases or systematic errors in how the models estimate their own confidence that could skew the results.
Additionally, the paper does not delve into the computational complexity and scalability of the proposed approach. Constructing confidence regions for large-scale language models could be computationally intensive, which could limit its practical applicability, especially for real-time or large-scale use cases.
Further research could explore ways to validate the self-reported confidence levels of LLMs, perhaps through comparative human evaluation or other techniques. Investigating more efficient algorithms for constructing confidence regions would also be a valuable area of investigation.
Conclusion
This paper presents a novel approach for ranking and evaluating large language models that takes uncertainty into account. By leveraging the models' own predictions, the authors demonstrate how this prediction-powered inference can provide a more comprehensive and nuanced assessment of LLM capabilities.
The technique offers valuable insights that could inform the development and deployment of these powerful AI systems, helping to ensure they are used responsibly and appropriately. As the field of large language models continues to evolve, approaches like the one described in this paper will become increasingly important for understanding the strengths, limitations, and uncertainties of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
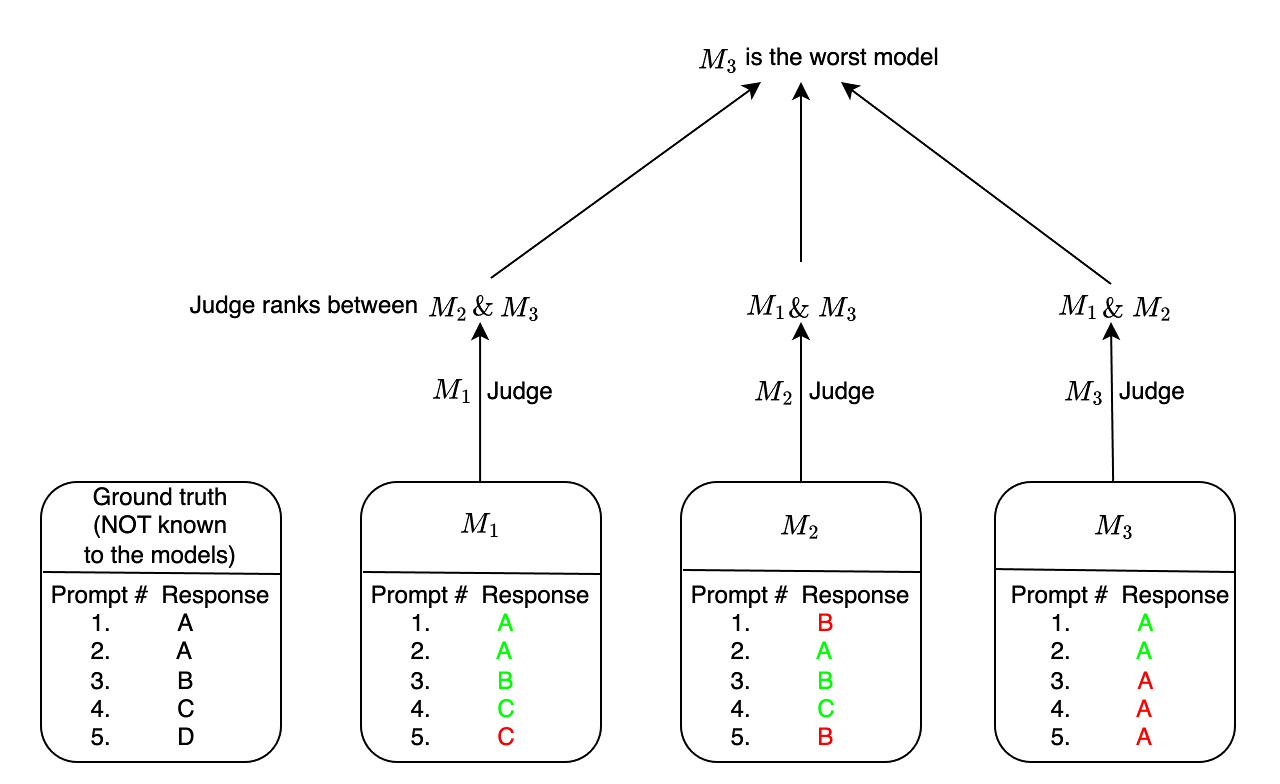
Ranking Large Language Models without Ground Truth
Amit Dhurandhar, Rahul Nair, Moninder Singh, Elizabeth Daly, Karthikeyan Natesan Ramamurthy
0
0
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
6/11/2024
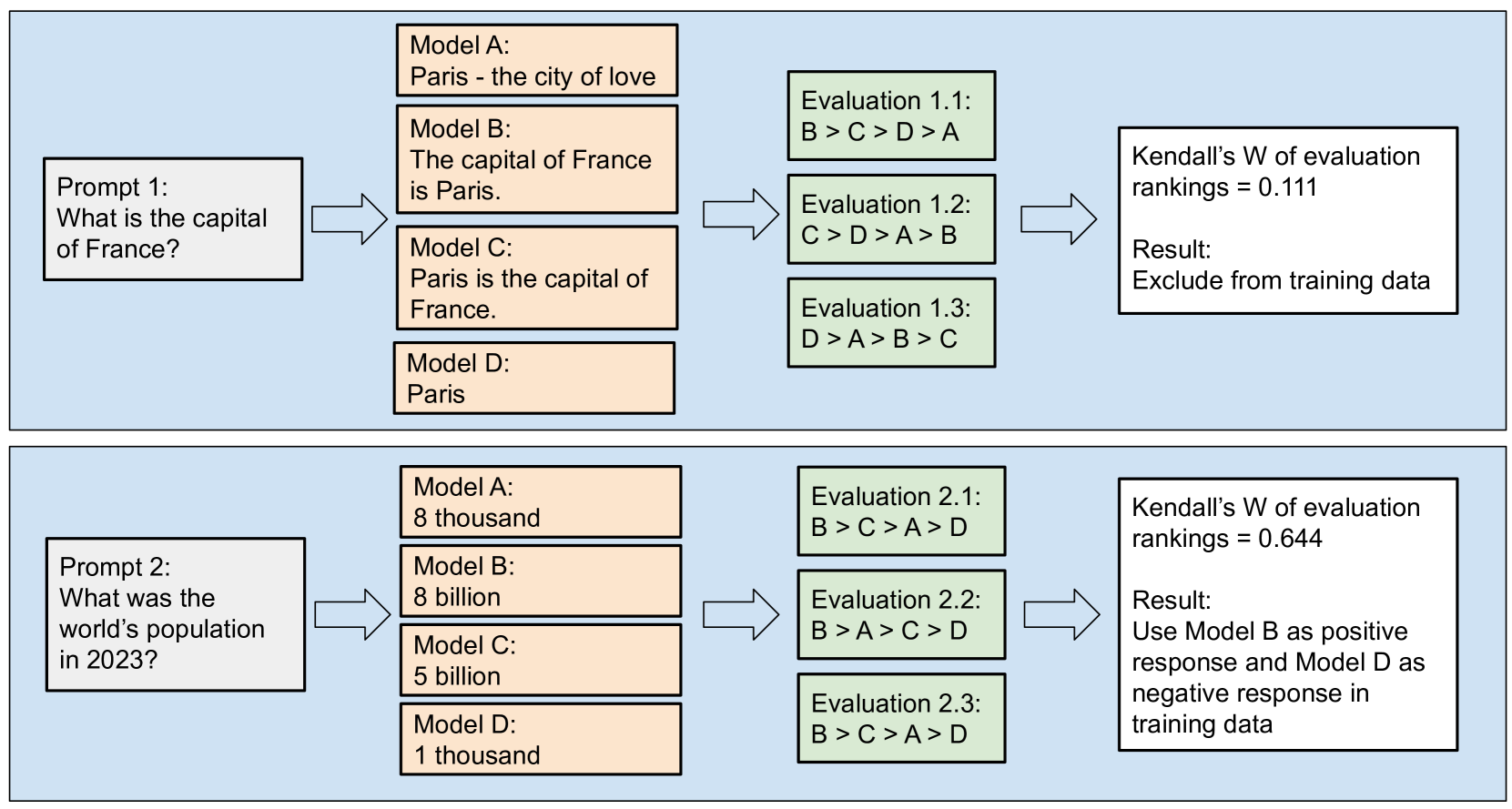
Large language models can accurately predict searcher preferences
Paul Thomas, Seth Spielman, Nick Craswell, Bhaskar Mitra
0
0
Relevance labels, which indicate whether a search result is valuable to a searcher, are key to evaluating and optimising search systems. The best way to capture the true preferences of users is to ask them for their careful feedback on which results would be useful, but this approach does not scale to produce a large number of labels. Getting relevance labels at scale is usually done with third-party labellers, who judge on behalf of the user, but there is a risk of low-quality data if the labeller doesn't understand user needs. To improve quality, one standard approach is to study real users through interviews, user studies and direct feedback, find areas where labels are systematically disagreeing with users, then educate labellers about user needs through judging guidelines, training and monitoring. This paper introduces an alternate approach for improving label quality. It takes careful feedback from real users, which by definition is the highest-quality first-party gold data that can be derived, and develops an large language model prompt that agrees with that data. We present ideas and observations from deploying language models for large-scale relevance labelling at Bing, and illustrate with data from TREC. We have found large language models can be effective, with accuracy as good as human labellers and similar capability to pick the hardest queries, best runs, and best groups. Systematic changes to the prompts make a difference in accuracy, but so too do simple paraphrases. To measure agreement with real searchers needs high-quality gold labels, but with these we find that models produce better labels than third-party workers, for a fraction of the cost, and these labels let us train notably better rankers.
5/20/2024
Make Large Language Model a Better Ranker
Wenshuo Chao, Zhi Zheng, Hengshu Zhu, Hao Liu
0
0
Large Language Models (LLMs) demonstrate robust capabilities across various fields, leading to a paradigm shift in LLM-enhanced Recommender System (RS). Research to date focuses on point-wise and pair-wise recommendation paradigms, which are inefficient for LLM-based recommenders due to high computational costs. However, existing list-wise approaches also fall short in ranking tasks due to misalignment between ranking objectives and next-token prediction. Moreover, these LLM-based methods struggle to effectively address the order relation among candidates, particularly given the scale of ratings. To address these challenges, this paper introduces the large language model framework with Aligned Listwise Ranking Objectives (ALRO). ALRO is designed to bridge the gap between the capabilities of LLMs and the nuanced requirements of ranking tasks. Specifically, ALRO employs explicit feedback in a listwise manner by introducing soft lambda loss, a customized adaptation of lambda loss designed for optimizing order relations. This mechanism provides more accurate optimization goals, enhancing the ranking process. Additionally, ALRO incorporates a permutation-sensitive learning mechanism that addresses position bias, a prevalent issue in generative models, without imposing additional computational burdens during inference. Our evaluative studies reveal that ALRO outperforms both existing embedding-based recommendation methods and LLM-based recommendation baselines.
6/26/2024
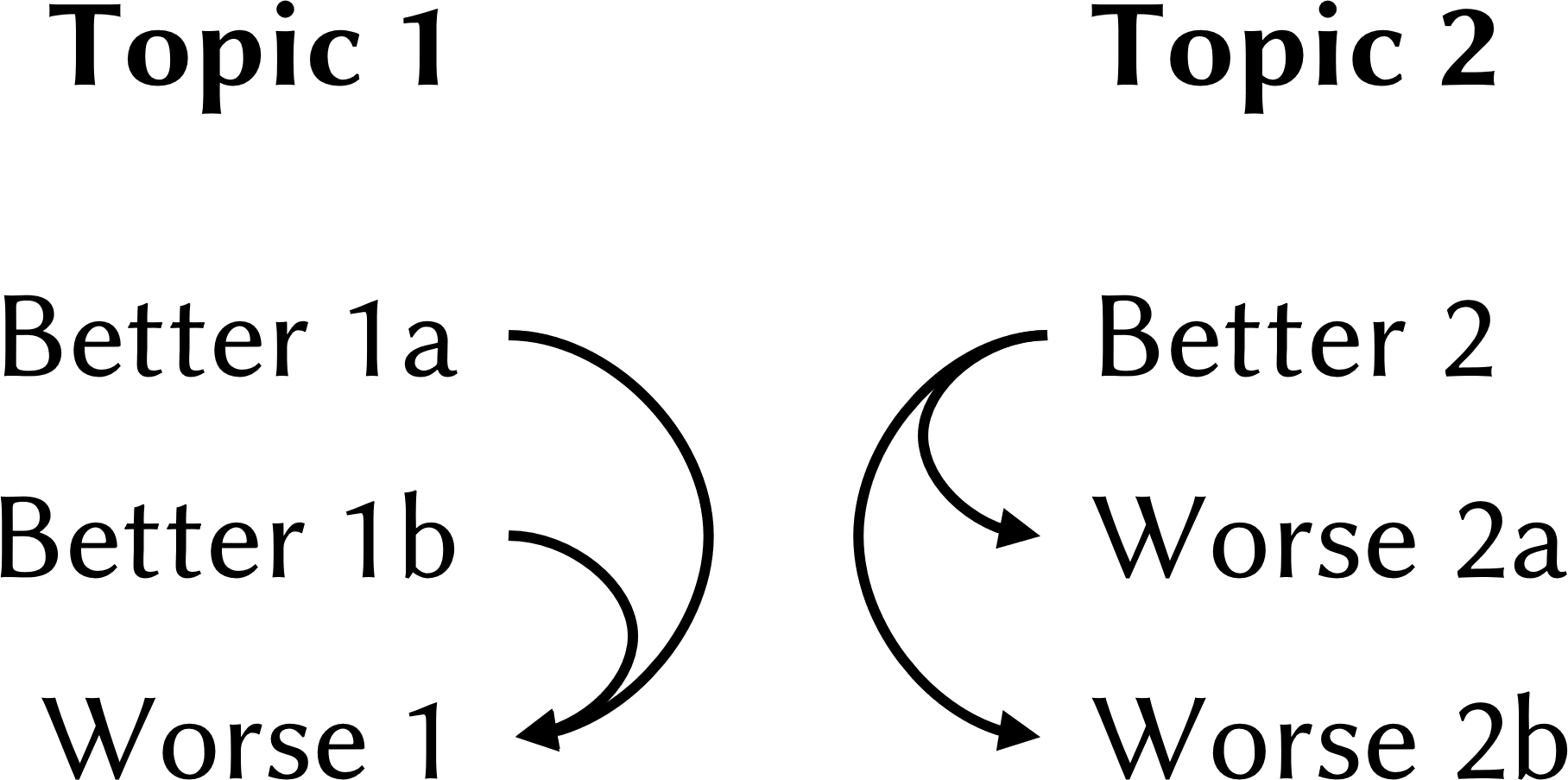
Are You Sure? Rank Them Again: Repeated Ranking For Better Preference Datasets
Peter Devine
0
0
Training Large Language Models (LLMs) with Reinforcement Learning from AI Feedback (RLAIF) aligns model outputs more closely with human preferences. This involves an evaluator model ranking multiple candidate responses to user prompts. However, the rankings from popular evaluator models such as GPT-4 can be inconsistent. We propose the Repeat Ranking method - where we evaluate the same responses multiple times and train only on those responses which are consistently ranked. Using 2,714 prompts in 62 languages, we generated responses from 7 top multilingual LLMs and had GPT-4 rank them five times each. Evaluating on MT-Bench chat benchmarks in six languages, our method outperformed the standard practice of training on all available prompts. Our work highlights the quality versus quantity trade-off in RLAIF dataset generation and offers a stackable strategy for enhancing dataset and thus model quality.
6/4/2024