Understanding Information Storage and Transfer in Multi-modal Large Language Models

0
Sign in to get full access
Overview
- Examines how multi-modal large language models (LLMs) store and transfer information across different modalities (e.g., text, images, audio)
- Explores the inner workings of these complex AI systems to better understand their capabilities and limitations
- Provides insights that can inform the development of more robust and interpretable multi-modal LLMs
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. But many modern LLMs are multi-modal, meaning they can also process and generate other types of data, like images and audio. Understanding Information Storage and Transfer in Multi-modal Large Language Models explores how these multi-modal LLMs store and share information across different data formats.
The researchers wanted to better understand the inner workings of these AI systems. By examining how they handle information from various sources, the team hoped to shed light on the models' capabilities and limitations. This could help guide the development of future multi-modal LLMs that are more robust and easier to interpret.
Technical Explanation
The paper presents a series of experiments that probe the information storage and transfer mechanisms in several state-of-the-art multi-modal LLMs, including CLIP, VL-T5, and DALL-E 2.
The researchers examined how these models encode and store information from different modalities, such as text and images. They also investigated how the models transfer knowledge between modalities, allowing them to perform cross-modal reasoning and generation tasks.
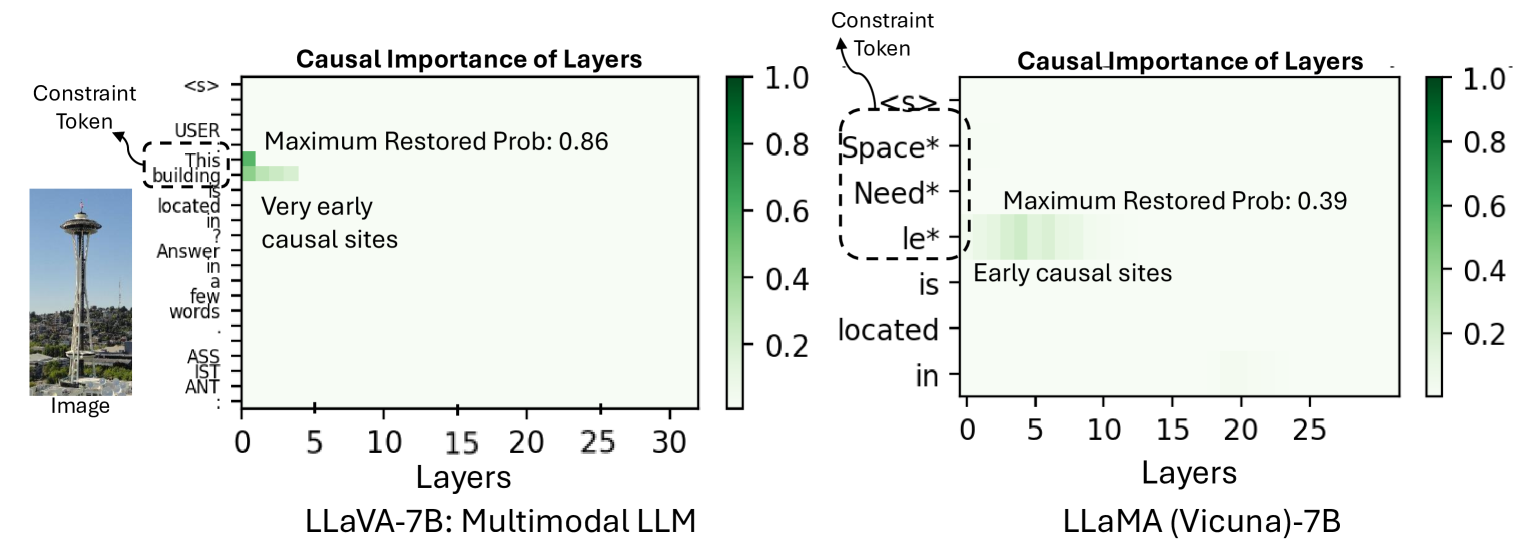
The experiments revealed insights into the internal representations and decision-making processes of the multi-modal LLMs. For example, the findings suggest that these models develop specialized subnetworks for processing different data types, which can lead to unimodal biases and challenges in achieving true cross-modal understanding.
Critical Analysis
The paper provides a valuable contribution to the understanding of multi-modal LLMs, but it also acknowledges several limitations and areas for further research. For instance, the experiments were conducted on a relatively small set of models and tasks, and the researchers note that the findings may not generalize to all multi-modal LLMs or real-world applications.
Additionally, the paper does not delve deeply into the ethical implications of these powerful AI systems, such as the potential for biases or the challenges in explaining their decision-making processes. Future research could explore these important considerations in more detail.
Conclusion
This paper offers a detailed examination of how multi-modal large language models store and transfer information across different data modalities. The findings provide valuable insights into the inner workings of these complex AI systems, which can inform the development of more robust and interpretable multi-modal LLMs capable of true cross-modal understanding and reasoning. As these models become increasingly influential, continued research and critical analysis will be crucial for ensuring they are designed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding Information Storage and Transfer in Multi-modal Large Language Models
Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, Daniela Massiceti
Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by the director in this photo has won a Golden Globe?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) VQA-Constraints, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit, a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks.
Read more6/7/2024

0
From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
Xiaofeng Zhang, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, Jieping Ye
Recently, multimodal large language models have exploded with an endless variety, most of the popular Large Vision Language Models (LVLMs) depend on sequential visual representation, where images are converted into hundreds or thousands of tokens before being input into the Large Language Model (LLM) along with language prompts. The black-box design hinders the interpretability of visual-language models, especially regarding more complex reasoning tasks. To explore the interaction process between image and text in complex reasoning tasks, we introduce the information flow method to visualize the interaction mechanism. By analyzing the dynamic flow of the information flow, we find that the information flow appears to converge in the shallow layer. Further investigation revealed a redundancy of the image token in the shallow layer. Consequently, a truncation strategy was introduced to aggregate image tokens within these shallow layers. This approach has been validated through experiments across multiple models, yielding consistent improvements.
Read more6/14/2024

0
A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
Read more4/3/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024