From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models

0

Sign in to get full access
Overview
• This paper explores ways to enhance the explainability of multimodal large language models, which are AI systems that can process and understand different types of media like text, images, and video.
• The researchers aim to address the "redundancy" problem in these models, where the system may generate irrelevant or redundant information when explaining its decision-making process.
• The paper proposes novel techniques to make the models' decision-making more transparent and relevant to the user's needs.
Plain English Explanation
• Multimodal large language models are powerful AI systems that can understand and generate different types of media, like text, images, and video. However, these models can sometimes produce explanations that are overly complex or irrelevant.
• The researchers in this paper want to make these models more "explainable," meaning they can clearly explain how they arrived at their outputs in a way that is helpful and relevant to the user.
• They propose new techniques to reduce the "redundancy" problem, where the models provide too much irrelevant information when explaining their decisions. Instead, the goal is to make the explanations more focused and tailored to the user's specific needs.
• By making these models more transparent and relevant, the researchers hope to build greater trust and understanding between humans and these powerful AI systems.
Technical Explanation
• The paper introduces two main technical innovations:
-
A method to enhance the relevance of model explanations by selectively highlighting the most important visual and textual cues used by the model.
-
An approach to disentangle and separate the different types of information stored and transferred within the model's latent representations.
• The researchers evaluate their techniques on popular multimodal tasks like visual question answering and image-to-text generation. Their results show significant improvements in the quality and relevance of the model's explanations.
• Key insights include the importance of modeling the dependencies between modalities (e.g. text and images) and the need to move beyond simple feature attribution methods towards more sophisticated representation disentanglement.
Critical Analysis
• The paper makes a compelling case for the importance of enhancing explainability in multimodal large language models, which are becoming increasingly powerful and ubiquitous.
• While the technical innovations are promising, the evaluation is limited to a few narrow tasks. Further research is needed to assess the generalizability of these techniques across a wider range of multimodal applications and domains.
• The paper does not address potential issues around fairness, bias, or safety that may arise from overly-confident or misleading model explanations. These are important considerations for real-world deployment of such systems.
• Overall, this work represents a valuable step towards more transparent and trustworthy multimodal AI models, but further research and careful development will be crucial.
Conclusion
This paper presents novel techniques to enhance the explainability of multimodal large language models, addressing the key challenge of providing relevant and transparent explanations for these powerful AI systems.
The researchers' innovations in relevance-focused explanations and representation disentanglement show promise for improving the interpretability of multimodal AI, which could lead to greater trust and understanding between humans and these increasingly sophisticated technologies.
While more work is needed to fully validate and generalize these methods, this research represents an important step forward in the ongoing effort to make complex AI systems more transparent and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
From Redundancy to Relevance: Enhancing Explainability in Multimodal Large Language Models
Xiaofeng Zhang, Chen Shen, Xiaosong Yuan, Shaotian Yan, Liang Xie, Wenxiao Wang, Chaochen Gu, Hao Tang, Jieping Ye
Recently, multimodal large language models have exploded with an endless variety, most of the popular Large Vision Language Models (LVLMs) depend on sequential visual representation, where images are converted into hundreds or thousands of tokens before being input into the Large Language Model (LLM) along with language prompts. The black-box design hinders the interpretability of visual-language models, especially regarding more complex reasoning tasks. To explore the interaction process between image and text in complex reasoning tasks, we introduce the information flow method to visualize the interaction mechanism. By analyzing the dynamic flow of the information flow, we find that the information flow appears to converge in the shallow layer. Further investigation revealed a redundancy of the image token in the shallow layer. Consequently, a truncation strategy was introduced to aggregate image tokens within these shallow layers. This approach has been validated through experiments across multiple models, yielding consistent improvements.
Read more6/14/2024
💬
0
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
Read more5/29/2024

0
A Concept-Based Explainability Framework for Large Multimodal Models
Jayneel Parekh, Pegah Khayatan, Mustafa Shukor, Alasdair Newson, Matthieu Cord
Large multimodal models (LMMs) combine unimodal encoders and large language models (LLMs) to perform multimodal tasks. Despite recent advancements towards the interpretability of these models, understanding internal representations of LMMs remains largely a mystery. In this paper, we present a novel framework for the interpretation of LMMs. We propose a dictionary learning based approach, applied to the representation of tokens. The elements of the learned dictionary correspond to our proposed concepts. We show that these concepts are well semantically grounded in both vision and text. Thus we refer to these as multi-modal concepts. We qualitatively and quantitatively evaluate the results of the learnt concepts. We show that the extracted multimodal concepts are useful to interpret representations of test samples. Finally, we evaluate the disentanglement between different concepts and the quality of grounding concepts visually and textually. We will publicly release our code.
Read more6/13/2024
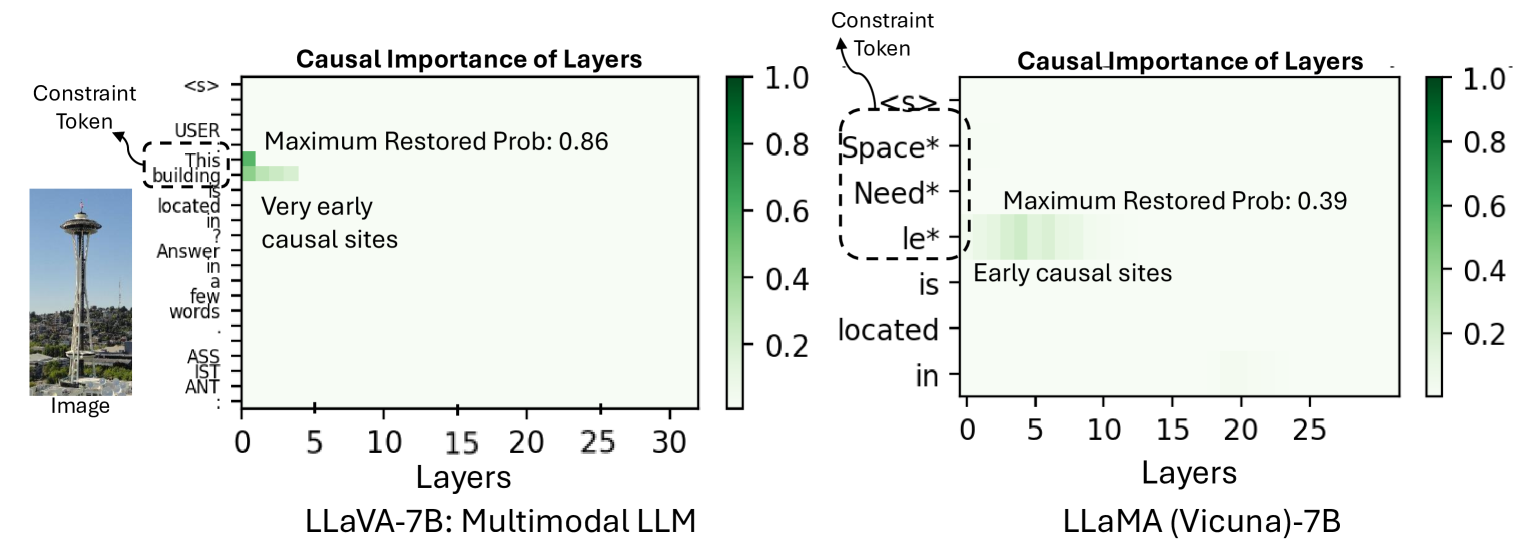
0
Understanding Information Storage and Transfer in Multi-modal Large Language Models
Samyadeep Basu, Martin Grayson, Cecily Morrison, Besmira Nushi, Soheil Feizi, Daniela Massiceti
Understanding the mechanisms of information storage and transfer in Transformer-based models is important for driving model understanding progress. Recent work has studied these mechanisms for Large Language Models (LLMs), revealing insights on how information is stored in a model's parameters and how information flows to and from these parameters in response to specific prompts. However, these studies have not yet been extended to Multi-modal Large Language Models (MLLMs). Given their expanding capabilities and real-world use, we start by studying one aspect of these models -- how MLLMs process information in a factual visual question answering task. We use a constraint-based formulation which views a visual question as having a set of visual or textual constraints that the model's generated answer must satisfy to be correct (e.g. What movie directed by the director in this photo has won a Golden Globe?). Under this setting, we contribute i) a method that extends causal information tracing from pure language to the multi-modal setting, and ii) VQA-Constraints, a test-bed of 9.7K visual questions annotated with constraints. We use these tools to study two open-source MLLMs, LLaVa and multi-modal Phi-2. Our key findings show that these MLLMs rely on MLP and self-attention blocks in much earlier layers for information storage, compared to LLMs whose mid-layer MLPs are more important. We also show that a consistent small subset of visual tokens output by the vision encoder are responsible for transferring information from the image to these causal blocks. We validate these mechanisms by introducing MultEdit, a model-editing algorithm that can correct errors and insert new long-tailed information into MLLMs by targeting these causal blocks.
Read more6/7/2024