Understanding Optimal Feature Transfer via a Fine-Grained Bias-Variance Analysis

0

Sign in to get full access
Overview
- This paper presents a fine-grained bias-variance analysis to understand optimal feature transfer in machine learning models.
- The authors investigate how the trade-off between bias and variance affects the performance of transferred features from a pre-trained model.
- They provide insights into the optimal depth at which to transfer features and how various factors, such as dataset size and model architecture, influence this trade-off.
Plain English Explanation
When training a machine learning model, there is always a balance to strike between bias and variance. Bias refers to the model's tendency to make consistent errors, while variance refers to the model's sensitivity to the specific training data. The authors of this paper wanted to better understand this bias-variance trade-off in the context of feature transfer.
Feature transfer is a common technique in machine learning where a model trained on a large, general dataset is used as a starting point for a model on a smaller, more specific dataset. The idea is that the features learned by the pre-trained model will be useful for the new task, saving time and data compared to training a model from scratch.
The authors conducted a detailed analysis to see how the depth at which features are transferred affects the bias and variance of the final model. They found that there is an optimal depth where the trade-off between bias and variance is best, and that this optimal depth depends on factors like the size of the dataset and the complexity of the model architecture.
This research provides valuable insights for data-driven prior learning and leveraging intra-layer representations in machine learning, helping practitioners make more informed decisions about how to effectively transfer features between models.
Technical Explanation
The authors begin by formulating the feature transfer problem as a bias-variance trade-off. They show that the optimal depth at which to transfer features depends on the balance between the bias introduced by the transferred features and the variance reduced by leveraging the learned representations.
To analyze this trade-off, the authors propose a fine-grained bias-variance decomposition that allows them to study the impact of transferring features at different depths. They apply this analysis to various datasets and model architectures, and find that the optimal depth for feature transfer depends on factors such as dataset size and model complexity.
The key insights from their analysis include:
- There exists an optimal depth for feature transfer that balances bias and variance.
- The optimal depth is lower for smaller datasets and more complex model architectures.
- Transferring features from the middle layers of a pre-trained model often yields the best performance.
These findings have important implications for practitioners, who can use this analysis to make more informed decisions about how to effectively leverage pre-trained models for their specific tasks and datasets.
Critical Analysis
The authors provide a thorough and rigorous analysis of the bias-variance trade-off in feature transfer, which is a valuable contribution to the field. However, there are a few potential limitations and areas for further research:
- The analysis is primarily focused on computer vision tasks, and it's unclear how well the insights would generalize to other domains, such as natural language processing or speech recognition.
- The study only considers a limited set of model architectures and dataset sizes. It would be interesting to see how the findings scale to a wider range of settings.
- The paper does not explore the impact of the specific pre-training task or dataset on the optimal feature transfer depth. This could be an interesting avenue for future research.
Overall, this paper provides a compelling and nuanced understanding of a fundamental challenge in transfer learning. The authors' fine-grained analysis offers practical guidance for practitioners, while also highlighting opportunities for further research in this important area of machine learning.
Conclusion
This paper presents a detailed bias-variance analysis of feature transfer in machine learning models. The authors show that there is an optimal depth at which to transfer features, and that this optimal depth depends on factors such as dataset size and model complexity.
These insights can help practitioners make more informed decisions about how to effectively leverage pre-trained models for their specific tasks and datasets. The research also opens up new avenues for exploring strong yet lightweight vision models and improving zero-shot classification through optimal feature transfer.
By providing a deeper understanding of the bias-variance trade-off in transfer learning, this paper contributes valuable insights that can help advance the state of the art in a wide range of machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding Optimal Feature Transfer via a Fine-Grained Bias-Variance Analysis
Yufan Li, Subhabrata Sen, Ben Adlam
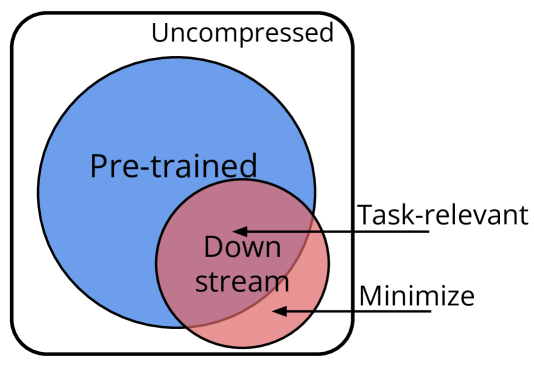
In the transfer learning paradigm models learn useful representations (or features) during a data-rich pretraining stage, and then use the pretrained representation to improve model performance on data-scarce downstream tasks. In this work, we explore transfer learning with the goal of optimizing downstream performance. We introduce a simple linear model that takes as input an arbitrary pretrained feature transform. We derive exact asymptotics of the downstream risk and its fine-grained bias-variance decomposition. Our finding suggests that using the ground-truth featurization can result in double-divergence of the asymptotic risk, indicating that it is not necessarily optimal for downstream performance. We then identify the optimal pretrained representation by minimizing the asymptotic downstream risk averaged over an ensemble of downstream tasks. Our analysis reveals the relative importance of learning the task-relevant features and structures in the data covariates and characterizes how each contributes to controlling the downstream risk from a bias-variance perspective. Moreover, we uncover a phase transition phenomenon where the optimal pretrained representation transitions from hard to soft selection of relevant features and discuss its connection to principal component regression.
Read more4/22/2024
0
Transferring Knowledge from Large Foundation Models to Small Downstream Models
Shikai Qiu, Boran Han, Danielle C. Maddix, Shuai Zhang, Yuyang Wang, Andrew Gordon Wilson
How do we transfer the relevant knowledge from ever larger foundation models into small, task-specific downstream models that can run at much lower costs? Standard transfer learning using pre-trained weights as the initialization transfers limited information and commits us to often massive pre-trained architectures. This procedure also precludes combining multiple pre-trained models that learn complementary information. To address these shortcomings, we introduce Adaptive Feature Transfer (AFT). Instead of transferring weights, AFT operates purely on features, thereby decoupling the choice of the pre-trained model from the smaller downstream model. Rather than indiscriminately compressing all pre-trained features, AFT adaptively transfers pre-trained features that are most useful for performing the downstream task, using a simple regularization that adds minimal overhead. Across multiple vision, language, and multi-modal datasets, AFT achieves significantly better downstream performance compared to alternatives with a similar computational cost. Furthermore, AFT reliably translates improvement in pre-trained models into improvement in downstream performance, even if the downstream model is over $50times$ smaller, and can effectively transfer complementary information learned by multiple pre-trained models.
Read more6/12/2024

0
An Empirical Study of Scaling Laws for Transfer
Matthew Barnett
We present a limited empirical study of scaling laws for transfer learning in transformer models. More specifically, we examine a scaling law that incorporates a transfer gap term, indicating the effectiveness of pre-training on one distribution when optimizing for downstream performance on another distribution. When the transfer gap is low, pre-training is a cost-effective strategy for improving downstream performance. Conversely, when the gap is high, collecting high-quality fine-tuning data becomes relatively more cost effective. Fitting the scaling law to experiments from diverse datasets reveals significant variations in the transfer gap across distributions. In theory, the scaling law can inform optimal data allocation strategies and highlights how the scarcity of downstream data can bottleneck performance. Our findings contribute to a principled way to measure transfer learning efficiency and understand how data availability affects capabilities.
Read more9/2/2024

0
Unsupervised Generative Feature Transformation via Graph Contrastive Pre-training and Multi-objective Fine-tuning
Wangyang Ying, Dongjie Wang, Xuanming Hu, Yuanchun Zhou, Charu C. Aggarwal, Yanjie Fu
Feature transformation is to derive a new feature set from original features to augment the AI power of data. In many science domains such as material performance screening, while feature transformation can model material formula interactions and compositions and discover performance drivers, supervised labels are collected from expensive and lengthy experiments. This issue motivates an Unsupervised Feature Transformation Learning (UFTL) problem. Prior literature, such as manual transformation, supervised feedback guided search, and PCA, either relies on domain knowledge or expensive supervised feedback, or suffers from large search space, or overlooks non-linear feature-feature interactions. UFTL imposes a major challenge on existing methods: how to design a new unsupervised paradigm that captures complex feature interactions and avoids large search space? To fill this gap, we connect graph, contrastive, and generative learning to develop a measurement-pretrain-finetune paradigm for UFTL. For unsupervised feature set utility measurement, we propose a feature value consistency preservation perspective and develop a mean discounted cumulative gain like unsupervised metric to evaluate feature set utility. For unsupervised feature set representation pretraining, we regard a feature set as a feature-feature interaction graph, and develop an unsupervised graph contrastive learning encoder to embed feature sets into vectors. For generative transformation finetuning, we regard a feature set as a feature cross sequence and feature transformation as sequential generation. We develop a deep generative feature transformation model that coordinates the pretrained feature set encoder and the gradient information extracted from a feature set utility evaluator to optimize a transformed feature generator.
Read more5/28/2024