Transferring Knowledge from Large Foundation Models to Small Downstream Models

0
Sign in to get full access
Overview
- This paper explores techniques for transferring knowledge from large, pre-trained "foundation" models to smaller "downstream" models.
- The goal is to improve the performance of these smaller models while reducing the computational and storage requirements compared to fine-tuning the entire foundation model.
- The authors propose several parameter-efficient fine-tuning methods and evaluate their effectiveness on various natural language processing and computer vision tasks.
Plain English Explanation
Large language models like GPT-3 and computer vision models like CLIP have shown impressive performance on a wide range of tasks. However, these "foundation" models can be computationally expensive and inefficient to deploy, especially on resource-constrained devices.
To address this, the researchers in this paper investigate ways to transfer the knowledge from these large foundation models to smaller "downstream" models that are more practical for real-world applications. The key idea is to fine-tune only a subset of the foundation model's parameters, rather than the entire model, in order to reduce the computational and storage requirements.
The paper explores several parameter-efficient fine-tuning methods, such as Understanding Optimal Feature Transfer via Fine-Grained Analysis, Sparse is Enough in Fine-Tuning Pre-Trained Models, and Parameter-Efficient Fine-Tuning of Large Models: A Comprehensive Study. The authors evaluate these techniques on both natural language processing and computer vision tasks, demonstrating their effectiveness in improving the performance of the smaller downstream models.
Technical Explanation
The paper begins by reviewing related work on knowledge transfer and parameter-efficient fine-tuning approaches, such as Empirical Study of Parameter-Efficient Transfer Learning for Vision Transformers and Supervised Fine-Tuning Turns Improves Visual Foundation Models.
The authors then propose several parameter-efficient fine-tuning methods, including:
- Selective Fine-Tuning: Selectively fine-tuning only a subset of the foundation model's parameters, such as the final layers or specific attention heads.
- Adapter-based Fine-Tuning: Inserting small "adapter" modules into the foundation model's architecture and fine-tuning only the adapter parameters.
- Prompt-based Fine-Tuning: Optimizing a task-specific prompt that guides the foundation model's behavior, rather than fine-tuning the model's parameters.
The researchers evaluate these techniques on a variety of natural language processing and computer vision tasks, comparing their performance and computational efficiency to fine-tuning the entire foundation model. The results demonstrate the effectiveness of these parameter-efficient approaches in improving the downstream model's performance while significantly reducing the computational and storage requirements.
Critical Analysis
The paper provides a comprehensive evaluation of several parameter-efficient fine-tuning methods and their effectiveness in transferring knowledge from large foundation models to smaller downstream models. The authors acknowledge that the performance of these techniques may be task-dependent and that further research is needed to understand the optimal fine-tuning strategies for different types of tasks and model architectures.
One potential limitation of the study is that it focuses primarily on standard benchmark tasks and does not explore the real-world deployment challenges that may arise when using these parameter-efficient fine-tuning methods. Additionally, the paper does not delve into the trade-offs between the different fine-tuning approaches, such as the ease of implementation, the interpretability of the resulting models, or the potential for negative transfer.
Overall, the research presented in this paper contributes valuable insights to the ongoing efforts to make large, powerful AI models more accessible and practical for a wide range of applications. The proposed techniques offer a promising path forward for leveraging the knowledge and capabilities of these foundation models in a more efficient and scalable manner.
Conclusion
This paper addresses an important challenge in the field of deep learning: how to effectively transfer the knowledge and capabilities of large, pre-trained foundation models to smaller, more practical downstream models. The authors explore several parameter-efficient fine-tuning methods and demonstrate their effectiveness in improving the performance of the downstream models while significantly reducing the computational and storage requirements.
The findings of this research have the potential to make large, powerful AI models more accessible and deployable in a wide range of real-world applications, from natural language processing to computer vision. By enabling the efficient transfer of knowledge from these foundation models, the proposed techniques can help bridge the gap between the impressive capabilities of state-of-the-art models and the practical constraints of edge devices and resource-constrained environments.
As the field of deep learning continues to advance, the insights and approaches presented in this paper will likely play an important role in the development of more efficient and scalable AI systems that can be widely deployed and have a tangible impact on our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transferring Knowledge from Large Foundation Models to Small Downstream Models
Shikai Qiu, Boran Han, Danielle C. Maddix, Shuai Zhang, Yuyang Wang, Andrew Gordon Wilson
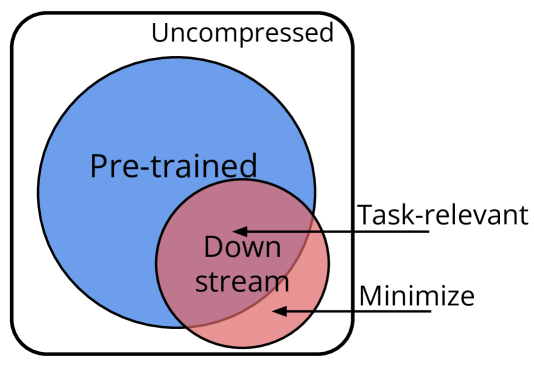
How do we transfer the relevant knowledge from ever larger foundation models into small, task-specific downstream models that can run at much lower costs? Standard transfer learning using pre-trained weights as the initialization transfers limited information and commits us to often massive pre-trained architectures. This procedure also precludes combining multiple pre-trained models that learn complementary information. To address these shortcomings, we introduce Adaptive Feature Transfer (AFT). Instead of transferring weights, AFT operates purely on features, thereby decoupling the choice of the pre-trained model from the smaller downstream model. Rather than indiscriminately compressing all pre-trained features, AFT adaptively transfers pre-trained features that are most useful for performing the downstream task, using a simple regularization that adds minimal overhead. Across multiple vision, language, and multi-modal datasets, AFT achieves significantly better downstream performance compared to alternatives with a similar computational cost. Furthermore, AFT reliably translates improvement in pre-trained models into improvement in downstream performance, even if the downstream model is over $50times$ smaller, and can effectively transfer complementary information learned by multiple pre-trained models.
Read more6/12/2024

0
Understanding Optimal Feature Transfer via a Fine-Grained Bias-Variance Analysis
Yufan Li, Subhabrata Sen, Ben Adlam
In the transfer learning paradigm models learn useful representations (or features) during a data-rich pretraining stage, and then use the pretrained representation to improve model performance on data-scarce downstream tasks. In this work, we explore transfer learning with the goal of optimizing downstream performance. We introduce a simple linear model that takes as input an arbitrary pretrained feature transform. We derive exact asymptotics of the downstream risk and its fine-grained bias-variance decomposition. Our finding suggests that using the ground-truth featurization can result in double-divergence of the asymptotic risk, indicating that it is not necessarily optimal for downstream performance. We then identify the optimal pretrained representation by minimizing the asymptotic downstream risk averaged over an ensemble of downstream tasks. Our analysis reveals the relative importance of learning the task-relevant features and structures in the data covariates and characterizes how each contributes to controlling the downstream risk from a bias-variance perspective. Moreover, we uncover a phase transition phenomenon where the optimal pretrained representation transitions from hard to soft selection of relevant features and discuss its connection to principal component regression.
Read more4/22/2024
🏅
0
Fine-tuning can cripple your foundation model; preserving features may be the solution
Jishnu Mukhoti, Yarin Gal, Philip H. S. Torr, Puneet K. Dokania
Pre-trained foundation models, due to their enormous capacity and exposure to vast amounts of data during pre-training, are known to have learned plenty of real-world concepts. An important step in making these pre-trained models effective on downstream tasks is to fine-tune them on related datasets. While various fine-tuning methods have been devised and have been shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is an undesirable effect of fine-tuning as a substantial amount of resources was used to learn these pre-trained concepts in the first place. We call this phenomenon ''concept forgetting'' and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we propose a simple fix to this problem by designing a new fine-tuning method called $textit{LDIFS}$ (short for $ell_2$ distance in feature space) that, while learning new concepts related to the downstream task, allows a model to preserve its pre-trained knowledge as well. Through extensive experiments on 10 fine-tuning tasks we show that $textit{LDIFS}$ significantly reduces concept forgetting. Additionally, we show that LDIFS is highly effective in performing continual fine-tuning on a sequence of tasks as well, in comparison with both fine-tuning as well as continual learning baselines.
Read more7/2/2024

0
Sparse is Enough in Fine-tuning Pre-trained Large Language Models
Weixi Song, Zuchao Li, Lefei Zhang, Hai Zhao, Bo Du
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation. Although PEFT has demonstrated effectiveness and been widely applied, the underlying principles are still unclear. In this paper, we adopt the PAC-Bayesian generalization error bound, viewing pre-training as a shift of prior distribution which leads to a tighter bound for generalization error. We validate this shift from the perspectives of oscillations in the loss landscape and the quasi-sparsity in gradient distribution. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
Read more6/11/2024