Uni-Med: A Unified Medical Generalist Foundation Model For Multi-Task Learning Via Connector-MoE

0
📈
Sign in to get full access
Overview
- Multi-modal large language models (MLLMs) have shown impressive capabilities for various visual and linguistic tasks.
- Building a unified MLLM for multi-task learning in the medical field remains a challenge.
- Recent advances focus on improving the LLM components, while neglecting the connector between modalities.
Plain English Explanation
Large language models that can handle both text and images (MLLMs) have demonstrated powerful capabilities across a range of applications. However, creating a single MLLM that can effectively perform multiple medical tasks is a significant challenge. Recent research has primarily focused on enhancing the individual language model components, but has overlooked the crucial role of the "connector" that bridges the gap between the text and visual modalities.
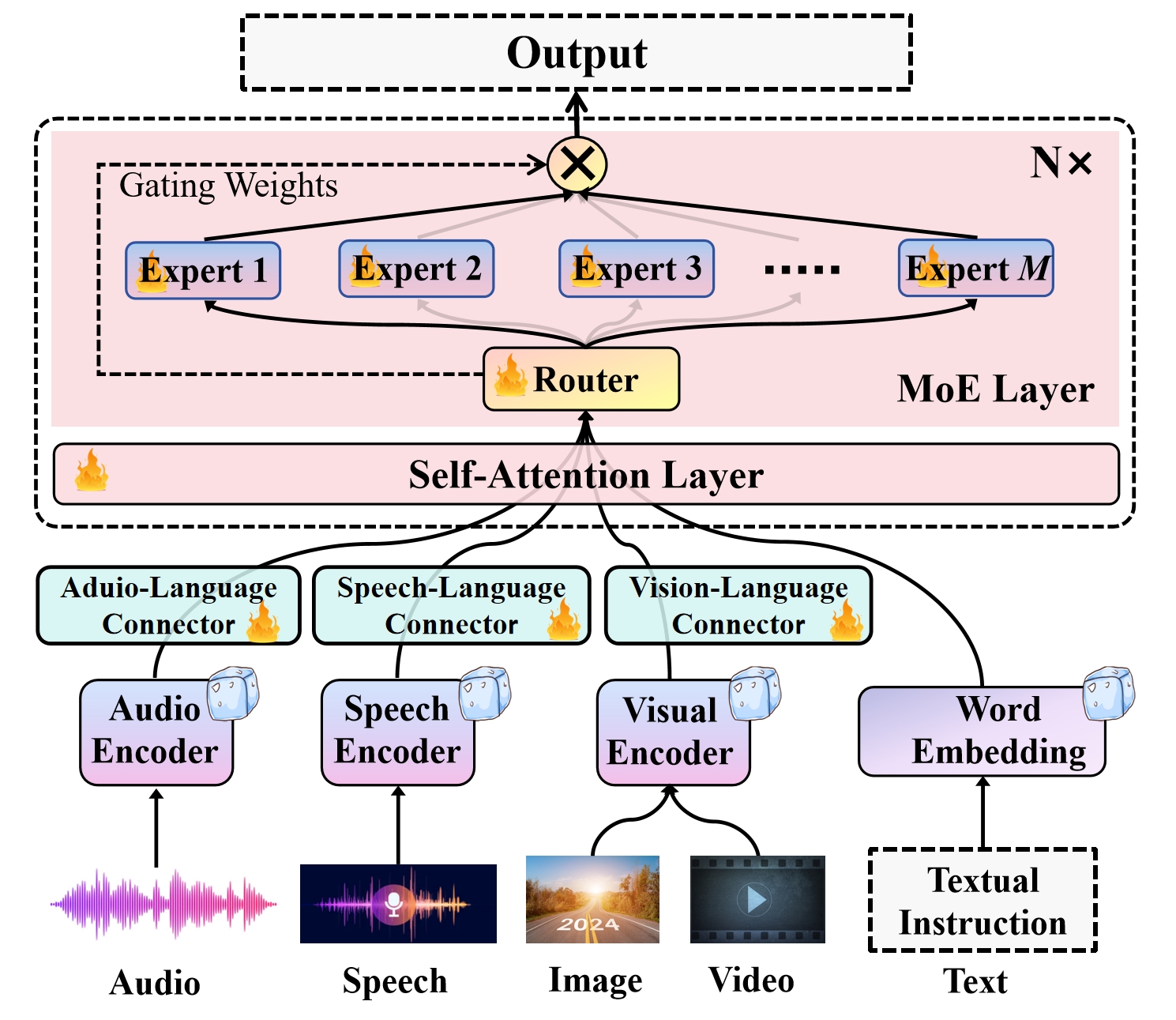
To address this issue, the paper introduces a novel medical foundation model called Uni-Med. Uni-Med consists of three key parts: a universal visual feature extraction module, a connector mixture-of-experts (CMoE) module, and a large language model. The innovative CMoE module is designed to efficiently solve the "tug-of-war" problem that can occur when optimizing for multiple tasks simultaneously. By leveraging a well-designed router and a mixture of projection experts, Uni-Med can perform a diverse set of six medical tasks, including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation, and image classification.
Technical Explanation
The paper presents Uni-Med, a novel medical generalist foundation model that addresses the challenges of multi-modal multi-task learning. Uni-Med is composed of three key components:
-
Universal Visual Feature Extraction Module: This module extracts visual features from input images, providing a consistent representation for the downstream tasks.
-
Connector Mixture-of-Experts (CMoE) Module: This is the core innovation of Uni-Med. The CMoE module leverages a well-designed router and a mixture of projection experts to efficiently solve the "tug-of-war" problem that can occur during multi-task optimization. By allowing the different tasks to specialize their own projection experts, the CMoE module enables Uni-Med to perform a diverse set of medical tasks.
-
Large Language Model (LLM): The LLM component processes the textual inputs and generates the final outputs for the various tasks.
The authors conduct extensive ablation experiments to validate the effectiveness of the CMoE module, demonstrating up to an 8% average performance gain across the evaluated tasks. They also provide an interpretation analysis of the "tug-of-war" problem from the perspective of gradient optimization and parameter statistics.
Compared to previous state-of-the-art medical MLLMs, Uni-Med achieves competitive or superior evaluation metrics on a diverse set of six medical tasks, including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation, and image classification.
Critical Analysis
The paper presents a compelling solution to the challenge of building a unified MLLM for multi-task learning in the medical domain. The introduction of the CMoE module is a significant innovation that addresses the "tug-of-war" problem, a critical issue in multi-task optimization.
However, the paper does not provide a detailed exploration of the limitations of the proposed approach. It would be helpful to understand the specific scenarios or tasks where Uni-Med may struggle, as well as any potential biases or shortcomings that could arise from the model's design or the dataset used for training.
Additionally, the paper could benefit from a more in-depth discussion of the broader implications and potential applications of Uni-Med in the medical field. Exploring how this foundation model could be adapted or fine-tuned for specific clinical use cases would further highlight the significance of the research.
Conclusion
The Uni-Med paper introduces a novel medical generalist foundation model that effectively addresses the challenges of multi-modal multi-task learning. By incorporating a innovative Connector Mixture-of-Experts (CMoE) module, Uni-Med is able to perform a diverse set of medical tasks, including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation, and image classification.
The paper's experiments demonstrate the effectiveness of the CMoE module, with significant performance gains compared to previous state-of-the-art medical MLLMs. This research represents an important step forward in developing unified models that can leverage both visual and linguistic information to tackle complex medical problems.
While the paper could benefit from a more thorough exploration of the model's limitations and broader implications, Uni-Med's capabilities and the novel CMoE module make it a promising foundation for future advancements in the field of medical AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Uni-Med: A Unified Medical Generalist Foundation Model For Multi-Task Learning Via Connector-MoE
Xun Zhu, Ying Hu, Fanbin Mo, Miao Li, Ji Wu
Multi-modal large language models (MLLMs) have shown impressive capabilities as a general-purpose interface for various visual and linguistic tasks. However, building a unified MLLM for multi-task learning in the medical field remains a thorny challenge. To mitigate the tug-of-war problem of multi-modal multi-task optimization, recent advances primarily focus on improving the LLM components, while neglecting the connector that bridges the gap between modalities. In this paper, we introduce Uni-Med, a novel medical generalist foundation model which consists of a universal visual feature extraction module, a connector mixture-of-experts (CMoE) module, and an LLM. Benefiting from the proposed CMoE that leverages a well-designed router with a mixture of projection experts at the connector, Uni-Med achieves efficient solution to the tug-of-war problem and can perform six different medical tasks including question answering, visual question answering, report generation, referring expression comprehension, referring expression generation and image classification. To the best of our knowledge, Uni-Med is the first effort to tackle multi-task interference at the connector. Extensive ablation experiments validate the effectiveness of introducing CMoE under any configuration, with up to an average 8% performance gains. We further provide interpretation analysis of the tug-of-war problem from the perspective of gradient optimization and parameter statistics. Compared to previous state-of-the-art medical MLLMs, Uni-Med achieves competitive or superior evaluation metrics on diverse tasks. Code, data and model will be soon available at GitHub.
Read more9/27/2024
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024

0
MM-Lego: Modular Biomedical Multimodal Models with Minimal Fine-Tuning
Konstantin Hemker, Nikola Simidjievski, Mateja Jamnik
Learning holistic computational representations in physical, chemical or biological systems requires the ability to process information from different distributions and modalities within the same model. Thus, the demand for multimodal machine learning models has sharply risen for modalities that go beyond vision and language, such as sequences, graphs, time series, or tabular data. While there are many available multimodal fusion and alignment approaches, most of them require end-to-end training, scale quadratically with the number of modalities, cannot handle cases of high modality imbalance in the training set, or are highly topology-specific, making them too restrictive for many biomedical learning tasks. This paper presents Multimodal Lego (MM-Lego), a modular and general-purpose fusion and model merging framework to turn any set of encoders into a competitive multimodal model with no or minimal fine-tuning. We achieve this by introducing a wrapper for unimodal encoders that enforces lightweight dimensionality assumptions between modalities and harmonises their representations by learning features in the frequency domain to enable model merging with little signal interference. We show that MM-Lego 1) can be used as a model merging method which achieves competitive performance with end-to-end fusion models without any fine-tuning, 2) can operate on any unimodal encoder, and 3) is a model fusion method that, with minimal fine-tuning, achieves state-of-the-art results on six benchmarked multimodal biomedical tasks.
Read more5/31/2024
👨🏫
0
Unified Modeling Enhanced Multimodal Learning for Precision Neuro-Oncology
Huahui Yi, Xiaofei Wang, Kang Li, Chao Li
Multimodal learning, integrating histology images and genomics, promises to enhance precision oncology with comprehensive views at microscopic and molecular levels. However, existing methods may not sufficiently model the shared or complementary information for more effective integration. In this study, we introduce a Unified Modeling Enhanced Multimodal Learning (UMEML) framework that employs a hierarchical attention structure to effectively leverage shared and complementary features of both modalities of histology and genomics. Specifically, to mitigate unimodal bias from modality imbalance, we utilize a query-based cross-attention mechanism for prototype clustering in the pathology encoder. Our prototype assignment and modularity strategy are designed to align shared features and minimizes modality gaps. An additional registration mechanism with learnable tokens is introduced to enhance cross-modal feature integration and robustness in multimodal unified modeling. Our experiments demonstrate that our method surpasses previous state-of-the-art approaches in glioma diagnosis and prognosis tasks, underscoring its superiority in precision neuro-Oncology.
Read more6/12/2024