MM-Lego: Modular Biomedical Multimodal Models with Minimal Fine-Tuning

0

Sign in to get full access
Overview
- Introduces a modular biomedical multimodal model called "MM-Lego" that can be easily adapted to various tasks with minimal fine-tuning.
- Aims to simplify the complexity of multimodal models by leveraging a unimodal approach.
- Emphasizes data efficiency and parameter-efficiency in model fine-tuning.
Plain English Explanation
The paper presents a new approach to building biomedical multimodal models, called "MM-Lego," that is designed to be more flexible and easier to adapt to different tasks. Typically, multimodal models that combine different types of data (e.g., text, images, and tabular data) can be quite complex and challenging to fine-tune for specific applications.
The researchers behind MM-Lego argue that a more modular, unimodal approach can simplify this process. Their idea is to create a base model that can handle various types of data, and then customize it for particular tasks by making only minor adjustments, rather than having to retrain the entire model from scratch.
This focus on data and parameter efficiency is important because it can make these powerful multimodal models more accessible and practical for real-world use cases, where resources and time may be limited. By reducing the amount of fine-tuning required, the researchers aim to make it easier for researchers and developers to adapt these models to their specific needs.
Technical Explanation
The paper introduces the MM-Lego framework, which is designed to be a modular and data-efficient multimodal fusion approach. The core idea is to create a base multimodal model that can handle a variety of data types, and then fine-tune it for specific tasks with minimal updates to the model parameters.
This is in contrast to the more common approach of training separate unimodal models and then fusing them together, which can be computationally expensive and require extensive fine-tuning.
The MM-Lego framework uses a parameter-efficient fine-tuning strategy to adapt the base model to new tasks. This involves freezing most of the model's parameters and only updating a small subset, which helps to preserve the model's multimodal capabilities while still allowing for task-specific customization.
The researchers demonstrate the effectiveness of their approach on several biomedical tasks, showing that MM-Lego can achieve competitive performance with significantly less fine-tuning effort compared to traditional multimodal models.
Critical Analysis
The paper presents a promising approach to simplifying the complexity of multimodal models, but it is important to consider some potential limitations and areas for further research:
- The evaluation is primarily focused on biomedical tasks, so it remains to be seen how well the MM-Lego framework would generalize to other domains.
- The paper does not provide a detailed comparison of the computational costs and training time for MM-Lego versus other multimodal approaches, which could be an important consideration for real-world deployments.
- The authors mention that further research is needed to explore the limits of parameter-efficient fine-tuning and understand the trade-offs between model flexibility and performance.
Overall, the MM-Lego approach represents an interesting step towards more efficient and adaptable multimodal models, but additional research and validation will be important to fully assess its potential impact on the field.
Conclusion
The MM-Lego paper presents a novel modular approach to building biomedical multimodal models that aims to simplify the complexity of these systems and make them more adaptable to various tasks. By leveraging a unimodal base model and a parameter-efficient fine-tuning strategy, the researchers demonstrate a path towards developing data-efficient and flexible multimodal models that can be more readily deployed in real-world applications. This work represents an important step in the ongoing efforts to make powerful multimodal AI systems more accessible and practical for a wider range of users and use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MM-Lego: Modular Biomedical Multimodal Models with Minimal Fine-Tuning
Konstantin Hemker, Nikola Simidjievski, Mateja Jamnik
Learning holistic computational representations in physical, chemical or biological systems requires the ability to process information from different distributions and modalities within the same model. Thus, the demand for multimodal machine learning models has sharply risen for modalities that go beyond vision and language, such as sequences, graphs, time series, or tabular data. While there are many available multimodal fusion and alignment approaches, most of them require end-to-end training, scale quadratically with the number of modalities, cannot handle cases of high modality imbalance in the training set, or are highly topology-specific, making them too restrictive for many biomedical learning tasks. This paper presents Multimodal Lego (MM-Lego), a modular and general-purpose fusion and model merging framework to turn any set of encoders into a competitive multimodal model with no or minimal fine-tuning. We achieve this by introducing a wrapper for unimodal encoders that enforces lightweight dimensionality assumptions between modalities and harmonises their representations by learning features in the frequency domain to enable model merging with little signal interference. We show that MM-Lego 1) can be used as a model merging method which achieves competitive performance with end-to-end fusion models without any fine-tuning, 2) can operate on any unimodal encoder, and 3) is a model fusion method that, with minimal fine-tuning, achieves state-of-the-art results on six benchmarked multimodal biomedical tasks.
Read more5/31/2024

0
From Efficient Multimodal Models to World Models: A Survey
Xinji Mai, Zeng Tao, Junxiong Lin, Haoran Wang, Yang Chang, Yanlan Kang, Yan Wang, Wenqiang Zhang
Multimodal Large Models (MLMs) are becoming a significant research focus, combining powerful large language models with multimodal learning to perform complex tasks across different data modalities. This review explores the latest developments and challenges in MLMs, emphasizing their potential in achieving artificial general intelligence and as a pathway to world models. We provide an overview of key techniques such as Multimodal Chain of Thought (M-COT), Multimodal Instruction Tuning (M-IT), and Multimodal In-Context Learning (M-ICL). Additionally, we discuss both the fundamental and specific technologies of multimodal models, highlighting their applications, input/output modalities, and design characteristics. Despite significant advancements, the development of a unified multimodal model remains elusive. We discuss the integration of 3D generation and embodied intelligence to enhance world simulation capabilities and propose incorporating external rule systems for improved reasoning and decision-making. Finally, we outline future research directions to address these challenges and advance the field.
Read more7/2/2024

0
Simplifying Multimodality: Unimodal Approach to Multimodal Challenges in Radiology with General-Domain Large Language Model
Seonhee Cho, Choonghan Kim, Jiho Lee, Chetan Chilkunda, Sujin Choi, Joo Heung Yoon
Recent advancements in Large Multimodal Models (LMMs) have attracted interest in their generalization capability with only a few samples in the prompt. This progress is particularly relevant to the medical domain, where the quality and sensitivity of data pose unique challenges for model training and application. However, the dependency on high-quality data for effective in-context learning raises questions about the feasibility of these models when encountering with the inevitable variations and errors inherent in real-world medical data. In this paper, we introduce MID-M, a novel framework that leverages the in-context learning capabilities of a general-domain Large Language Model (LLM) to process multimodal data via image descriptions. MID-M achieves a comparable or superior performance to task-specific fine-tuned LMMs and other general-domain ones, without the extensive domain-specific training or pre-training on multimodal data, with significantly fewer parameters. This highlights the potential of leveraging general-domain LLMs for domain-specific tasks and offers a sustainable and cost-effective alternative to traditional LMM developments. Moreover, the robustness of MID-M against data quality issues demonstrates its practical utility in real-world medical domain applications.
Read more5/6/2024
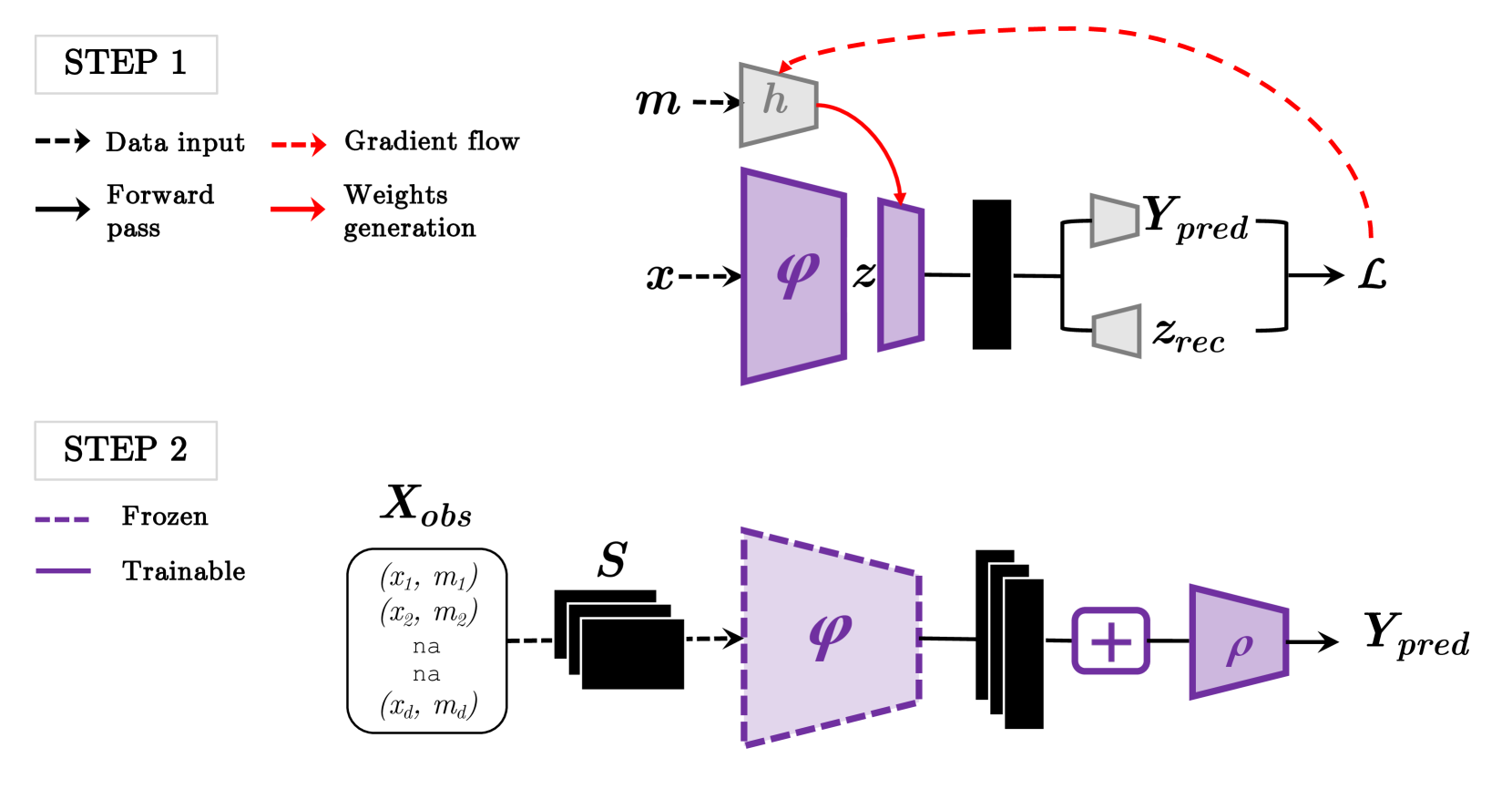
0
HyperMM : Robust Multimodal Learning with Varying-sized Inputs
Hava Chaptoukaev, Vincenzo Marcian'o, Francesco Galati, Maria A. Zuluaga
Combining multiple modalities carrying complementary information through multimodal learning (MML) has shown considerable benefits for diagnosing multiple pathologies. However, the robustness of multimodal models to missing modalities is often overlooked. Most works assume modality completeness in the input data, while in clinical practice, it is common to have incomplete modalities. Existing solutions that address this issue rely on modality imputation strategies before using supervised learning models. These strategies, however, are complex, computationally costly and can strongly impact subsequent prediction models. Hence, they should be used with parsimony in sensitive applications such as healthcare. We propose HyperMM, an end-to-end framework designed for learning with varying-sized inputs. Specifically, we focus on the task of supervised MML with missing imaging modalities without using imputation before training. We introduce a novel strategy for training a universal feature extractor using a conditional hypernetwork, and propose a permutation-invariant neural network that can handle inputs of varying dimensions to process the extracted features, in a two-phase task-agnostic framework. We experimentally demonstrate the advantages of our method in two tasks: Alzheimer's disease detection and breast cancer classification. We demonstrate that our strategy is robust to high rates of missing data and that its flexibility allows it to handle varying-sized datasets beyond the scenario of missing modalities.
Read more7/31/2024