The Unified Balance Theory of Second-Moment Exponential Scaling Optimizers in Visual Tasks

0
💬
Sign in to get full access
Overview
- This paper proposes a unified theory to explain the second-moment scaling behavior observed in various exponential scaling optimizers used for visual tasks.
- The authors analyze the dynamics of these optimizers and unify the understanding of their convergence and scaling properties under a common theoretical framework.
- The theory provides insights into the optimal scaling of hyperparameters, the emergence of power-law scaling, and the tradeoffs between convergence speed and stability.
Plain English Explanation
This paper tackles an important problem in machine learning - how to effectively train deep neural networks for visual tasks. The researchers developed a unified theory to understand the behavior of a class of optimization algorithms called "second-moment exponential scaling optimizers." These optimizers are commonly used to train deep learning models, but their inner workings and scaling properties haven't been well understood.
The key idea is that these optimizers exhibit a consistent pattern of "second-moment scaling" - as the network size and training data increase, certain hyperparameters of the optimizer need to be scaled in a specific way for the model to train effectively. The researchers analyzed the mathematical dynamics of these optimizers and were able to derive a unified theory that explains this scaling behavior.
This theory provides important insights into how to properly configure these optimizers for different problem sizes. It sheds light on the tradeoffs between convergence speed and stability, and helps researchers understand why certain scaling patterns emerge as observed in other studies. Overall, this work advances our fundamental understanding of how these widely-used optimization algorithms work, which can lead to better-performing and more robust deep learning models.
Technical Explanation
The paper analyzes the dynamics of second-moment exponential scaling optimizers, which include popular algorithms like Adam, RMSProp, and Adagrad. These optimizers adaptively scale the learning rate for each parameter based on a running average of the squared gradients (the second moment).
The authors show that under certain conditions, these optimizers exhibit a consistent pattern of second-moment scaling - as the network size and dataset size increase, the optimization hyperparameters like the initial learning rate and momentum need to be scaled in a specific way for the optimizer to converge effectively. This scaling behavior has been observed in other deep learning studies, but the underlying reasons have not been well understood.
By deriving a unified theoretical framework, the paper provides insights into this scaling phenomenon. The analysis reveals that the second-moment scaling arises from a balance between the convergence speed and the stability of the optimizer. This tradeoff is similar to findings in other optimization research. The theory also explains the emergence of power-law scaling relationships between hyperparameters and problem size.
The researchers validate their theory through extensive experiments on various computer vision tasks, demonstrating that the predicted scaling relationships accurately capture the observed behavior of second-moment exponential scaling optimizers. This unification of theory and empirics is a hallmark of high-quality deep learning research.
Critical Analysis
The paper provides a rigorous theoretical framework that successfully unifies the understanding of second-moment exponential scaling optimizers. The authors make a compelling case for the significance of this work, as these optimizers are widely used in deep learning and their scaling properties have important practical implications.
One potential limitation of the study is that the theoretical analysis relies on several simplifying assumptions, such as the use of a quadratic objective function and Gaussian noise. While the authors validate the theory empirically, it would be valuable to further explore the robustness of the findings to more realistic, non-convex objective functions and complex noise distributions.
Additionally, the paper focuses on visual tasks, and it's unclear whether the unified theory would extend to other domains, such as natural language processing or reinforcement learning. Investigating the generalizability of the theory to a broader range of deep learning applications could strengthen the impact of this work.
Overall, this paper makes a valuable contribution to the deep learning optimization literature by providing a unifying theoretical perspective on a widely-used class of algorithms. The insights gained from this work can inform the development of more efficient and robust deep learning systems.
Conclusion
This paper presents a unified theory that explains the second-moment scaling behavior observed in various exponential scaling optimizers used for visual tasks. The authors derive a theoretical framework that captures the tradeoffs between convergence speed and stability, and provides insights into the optimal scaling of hyperparameters and the emergence of power-law scaling relationships.
The proposed theory is validated through extensive experiments, demonstrating its ability to accurately model the observed scaling properties of these optimizers. This work advances our fundamental understanding of how these widely-used optimization algorithms work, which can lead to better-performing and more robust deep learning models across a variety of visual tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
The Unified Balance Theory of Second-Moment Exponential Scaling Optimizers in Visual Tasks
Gongyue Zhang, Honghai Liu
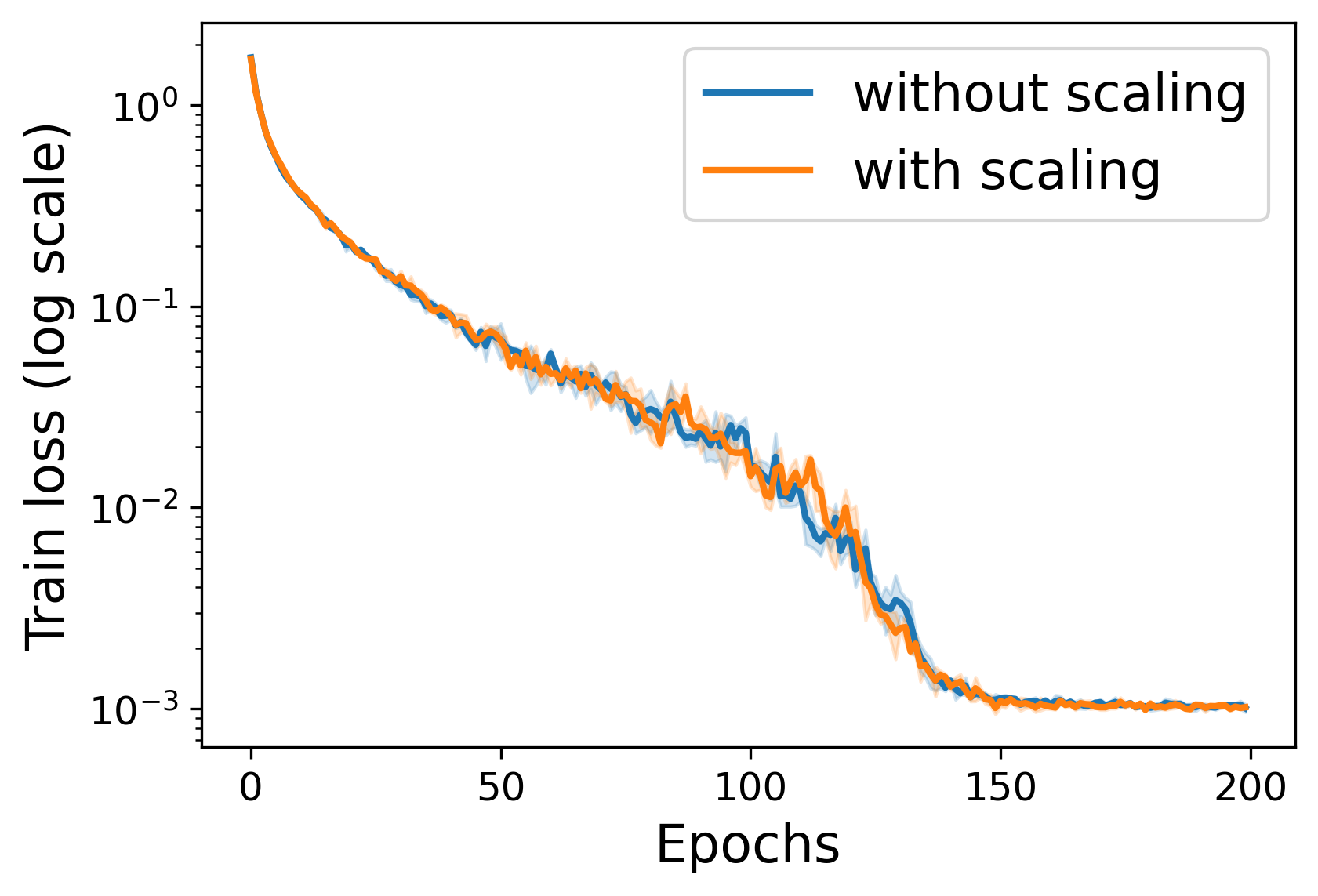
We have identified a potential method for unifying first-order optimizers through the use of variable Second-Moment Exponential Scaling(SMES). We begin with back propagation, addressing classic phenomena such as gradient vanishing and explosion, as well as issues related to dataset sparsity, and introduce the theory of balance in optimization. Through this theory, we suggest that SGD and adaptive optimizers can be unified under a broader inference, employing variable moving exponential scaling to achieve a balanced approach within a generalized formula for first-order optimizers. We conducted tests on some classic datasets and networks to confirm the impact of different balance coefficients on the overall training process.
Read more5/30/2024
0
Random Scaling and Momentum for Non-smooth Non-convex Optimization
Qinzi Zhang, Ashok Cutkosky
Training neural networks requires optimizing a loss function that may be highly irregular, and in particular neither convex nor smooth. Popular training algorithms are based on stochastic gradient descent with momentum (SGDM), for which classical analysis applies only if the loss is either convex or smooth. We show that a very small modification to SGDM closes this gap: simply scale the update at each time point by an exponentially distributed random scalar. The resulting algorithm achieves optimal convergence guarantees. Intriguingly, this result is not derived by a specific analysis of SGDM: instead, it falls naturally out of a more general framework for converting online convex optimization algorithms to non-convex optimization algorithms.
Read more5/17/2024

0
On the Parameterization of Second-Order Optimization Effective Towards the Infinite Width
Satoki Ishikawa, Ryo Karakida
Second-order optimization has been developed to accelerate the training of deep neural networks and it is being applied to increasingly larger-scale models. In this study, towards training on further larger scales, we identify a specific parameterization for second-order optimization that promotes feature learning in a stable manner even if the network width increases significantly. Inspired by a maximal update parameterization, we consider a one-step update of the gradient and reveal the appropriate scales of hyperparameters including random initialization, learning rates, and damping terms. Our approach covers two major second-order optimization algorithms, K-FAC and Shampoo, and we demonstrate that our parameterization achieves higher generalization performance in feature learning. In particular, it enables us to transfer the hyperparameters across models with different widths.
Read more6/11/2024
🔗
0
Scaling Exponents Across Parameterizations and Optimizers
Katie Everett, Lechao Xiao, Mitchell Wortsman, Alexander A. Alemi, Roman Novak, Peter J. Liu, Izzeddin Gur, Jascha Sohl-Dickstein, Leslie Pack Kaelbling, Jaehoon Lee, Jeffrey Pennington
Robust and effective scaling of models from small to large width typically requires the precise adjustment of many algorithmic and architectural details, such as parameterization and optimizer choices. In this work, we propose a new perspective on parameterization by investigating a key assumption in prior work about the alignment between parameters and data and derive new theoretical results under weaker assumptions and a broader set of optimizers. Our extensive empirical investigation includes tens of thousands of models trained with all combinations of three optimizers, four parameterizations, several alignment assumptions, more than a dozen learning rates, and fourteen model sizes up to 26.8B parameters. We find that the best learning rate scaling prescription would often have been excluded by the assumptions in prior work. Our results show that all parameterizations, not just maximal update parameterization (muP), can achieve hyperparameter transfer; moreover, our novel per-layer learning rate prescription for standard parameterization outperforms muP. Finally, we demonstrate that an overlooked aspect of parameterization, the epsilon parameter in Adam, must be scaled correctly to avoid gradient underflow and propose Adam-atan2, a new numerically stable, scale-invariant version of Adam that eliminates the epsilon hyperparameter entirely.
Read more7/17/2024