A Unified Confidence Sequence for Generalized Linear Models, with Applications to Bandits

0
Sign in to get full access
Overview
- The paper presents a unified confidence sequence for generalized linear models, which can be applied to various bandit problems.
- The authors develop a confidence sequence that provides tighter bounds compared to existing methods, leading to improved performance in bandit applications.
- The paper covers both theoretical and empirical aspects, demonstrating the effectiveness of the proposed approach.
Plain English Explanation
The paper focuses on a mathematical concept called "generalized linear models," which are used to analyze data with different types of variables, such as binary or count data. The authors develop a new way to quantify the uncertainty or "confidence" in the estimates from these models, which is important for making decisions under uncertainty, like in bandit problems.
Bandit problems are a type of decision-making challenge where you have to choose between different options (like which ad to show or which product to recommend) without knowing the exact payoffs or outcomes of each option. The authors show that their new confidence sequence can lead to better decision-making in these types of problems, helping to maximize the rewards or minimize the regret (the difference between the optimal outcome and the actual outcome).
The key idea is that the authors' confidence sequence provides tighter or more precise estimates of the uncertainty, which allows the decision-maker to make better-informed choices. This can lead to more efficient and effective algorithms for these types of problems compared to existing methods.
Technical Explanation
The paper introduces a unified confidence sequence for generalized linear models, which can be applied to a variety of bandit problems. The authors develop a novel confidence sequence that provides tighter bounds compared to existing approaches, leading to improved performance in these applications.
The technical approach involves deriving a confidence sequence that holds uniformly over time and across the entire parameter space of the generalized linear model. This is achieved by carefully analyzing the martingale properties of the log-likelihood ratio process and leveraging concentration inequalities. The authors establish theoretical guarantees on the coverage and width of the confidence sequence, demonstrating its advantages over prior methods.
Empirically, the authors evaluate the proposed confidence sequence in the context of linear and logistic bandits, showing that it leads to lower regret and faster convergence compared to existing algorithms. The improvements are particularly pronounced in settings with heterogeneous or non-Gaussian noise distributions.
Critical Analysis
The paper provides a solid theoretical foundation for the proposed confidence sequence and demonstrates its practical benefits through extensive experiments. However, a few potential limitations and areas for further research are worth considering:
-
The analysis is primarily focused on generalized linear models, and it would be interesting to see if the confidence sequence can be extended to other model classes, such as non-linear or robust models.
-
The paper does not explicitly address the computational complexity of the proposed method, which could be an important consideration in real-world applications with large-scale or high-dimensional data.
-
The empirical evaluation is limited to linear and logistic bandits, and it would be valuable to explore the performance of the confidence sequence in other bandit settings, such as contextual or combinatorial bandits.
-
The paper does not discuss the potential fairness or ethical implications of the proposed approach, which is an important consideration for real-world applications involving decision-making under uncertainty.
Conclusion
This paper presents a unified confidence sequence for generalized linear models that can be effectively applied to a variety of bandit problems. The authors' approach provides tighter confidence bounds compared to existing methods, leading to improved performance in terms of regret minimization and faster convergence. The theoretical and empirical contributions of this work have the potential to advance the state-of-the-art in decision-making under uncertainty, with applications in areas such as online advertising, recommender systems, and adaptive clinical trials.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Confidence Sequence for Generalized Linear Models, with Applications to Bandits
Junghyun Lee, Se-Young Yun, Kwang-Sung Jun
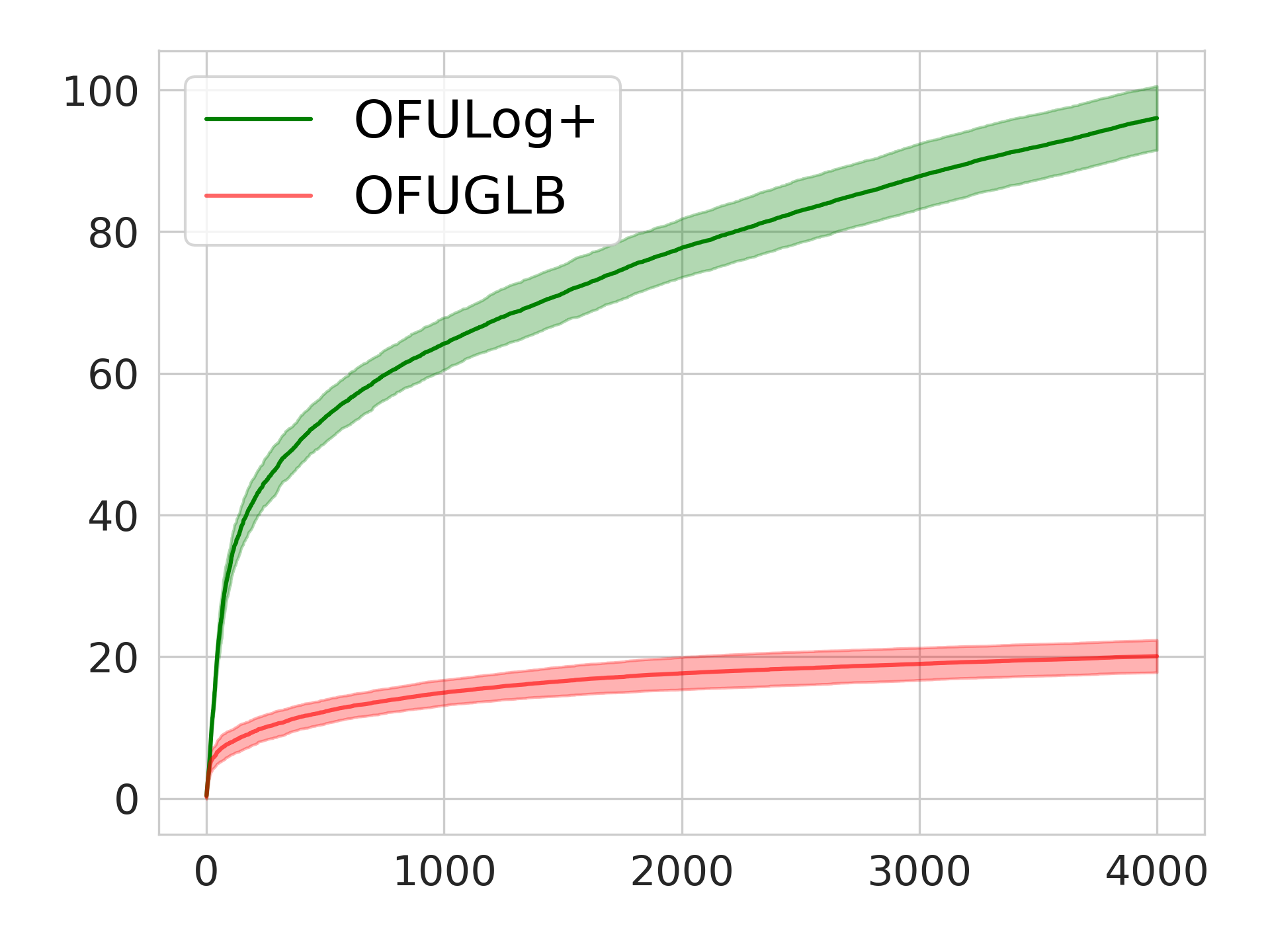
We present a unified likelihood ratio-based confidence sequence (CS) for any (self-concordant) generalized linear models (GLMs) that is guaranteed to be convex and numerically tight. We show that this is on par or improves upon known CSs for various GLMs, including Gaussian, Bernoulli, and Poisson. In particular, for the first time, our CS for Bernoulli has a poly(S)-free radius where S is the norm of the unknown parameter. Our first technical novelty is its derivation, which utilizes a time-uniform PAC-Bayesian bound with a uniform prior/posterior, despite the latter being a rather unpopular choice for deriving CSs. As a direct application of our new CS, we propose a simple and natural optimistic algorithm called OFUGLB applicable to any generalized linear bandits (GLB; Filippi et al. (2010)). Our analysis shows that the celebrated optimistic approach simultaneously attains state-of-the-art regrets for various self-concordant (not necessarily bounded) GLBs, and even poly(S)-free for bounded GLBs, including logistic bandits. The regret analysis, our second technical novelty, follows from combining our new CS with a new proof technique that completely avoids the previously widely used self-concordant control lemma (Faury et al., 2020, Lemma 9). Finally, we verify numerically that OFUGLB significantly outperforms the prior state-of-the-art (Lee et al., 2024) for logistic bandits.
Read more7/22/2024
🛠️
0
Noise-Adaptive Confidence Sets for Linear Bandits and Application to Bayesian Optimization
Kwang-Sung Jun, Jungtaek Kim
Adapting to a priori unknown noise level is a very important but challenging problem in sequential decision-making as efficient exploration typically requires knowledge of the noise level, which is often loosely specified. We report significant progress in addressing this issue for linear bandits in two respects. First, we propose a novel confidence set that is `semi-adaptive' to the unknown sub-Gaussian parameter $sigma_*^2$ in the sense that the (normalized) confidence width scales with $sqrt{dsigma_*^2 + sigma_0^2}$ where $d$ is the dimension and $sigma_0^2$ is the specified sub-Gaussian parameter (known) that can be much larger than $sigma_*^2$. This is a significant improvement over $sqrt{dsigma_0^2}$ of the standard confidence set of Abbasi-Yadkori et al. (2011), especially when $d$ is large or $sigma_*^2=0$. We show that this leads to an improved regret bound in linear bandits. Second, for bounded rewards, we propose a novel variance-adaptive confidence set that has much improved numerical performance upon prior art. We then apply this confidence set to develop, as we claim, the first practical variance-adaptive linear bandit algorithm via an optimistic approach, which is enabled by our novel regret analysis technique. Both of our confidence sets rely critically on `regret equality' from online learning. Our empirical evaluation in diverse Bayesian optimization tasks shows that our proposed algorithms demonstrate better or comparable performance compared to existing methods.
Read more6/11/2024
🛸
0
Improved Bound for Robust Causal Bandits with Linear Models
Zirui Yan, Arpan Mukherjee, Burak Var{i}c{i}, Ali Tajer
This paper investigates the robustness of causal bandits (CBs) in the face of temporal model fluctuations. This setting deviates from the existing literature's widely-adopted assumption of constant causal models. The focus is on causal systems with linear structural equation models (SEMs). The SEMs and the time-varying pre- and post-interventional statistical models are all unknown and subject to variations over time. The goal is to design a sequence of interventions that incur the smallest cumulative regret compared to an oracle aware of the entire causal model and its fluctuations. A robust CB algorithm is proposed, and its cumulative regret is analyzed by establishing both upper and lower bounds on the regret. It is shown that in a graph with maximum in-degree $d$, length of the largest causal path $L$, and an aggregate model deviation $C$, the regret is upper bounded by $tilde{mathcal{O}}(d^{L-frac{1}{2}}(sqrt{T} + C))$ and lower bounded by $Omega(d^{frac{L}{2}-2}max{sqrt{T}; ,; d^2C})$. The proposed algorithm achieves nearly optimal $tilde{mathcal{O}}(sqrt{T})$ regret when $C$ is $o(sqrt{T})$, maintaining sub-linear regret for a broad range of $C$.
Read more5/14/2024
📉
0
Towards Efficient and Optimal Covariance-Adaptive Algorithms for Combinatorial Semi-Bandits
Julien Zhou (Thoth, STATIFY), Pierre Gaillard (Thoth), Thibaud Rahier (SODA, PREMEDICAL), Houssam Zenati (SODA, PREMEDICAL), Julyan Arbel (STATIFY)
We address the problem of stochastic combinatorial semi-bandits, where a player selects among $P$ actions from the power set of a set containing $d$ base items. Adaptivity to the problem's structure is essential in order to obtain optimal regret upper bounds. As estimating the coefficients of a covariance matrix can be manageable in practice, leveraging them should improve the regret. We design ``optimistic'' covariance-adaptive algorithms relying on online estimations of the covariance structure, called OLSUCBC and COSV (only the variances for the latter). They both yields improved gap-free regret. Although COSV can be slightly suboptimal, it improves on computational complexity by taking inspiration from Thompson Sampling approaches. It is the first sampling-based algorithm satisfying a $sqrt{T}$ gap-free regret (up to poly-logs). We also show that in some cases, our approach efficiently leverages the semi-bandit feedback and outperforms bandit feedback approaches, not only in exponential regimes where $Pgg d$ but also when $Pleq d$, which is not covered by existing analyses.
Read more7/4/2024