Unified Neural Network Scaling Laws and Scale-time Equivalence

0

Sign in to get full access
Overview
- This paper proposes a unified theory of neural network scaling laws that can explain and predict how neural network performance scales with model size, compute, and training data.
- The key insight is that neural networks exhibit "scale-time equivalence", where increasing model size, compute, or training data has a similar effect on performance.
- The authors derive a set of theoretical scaling laws that capture this scale-time equivalence and validate them empirically on a range of neural network architectures and tasks.
Plain English Explanation
The paper explores how the performance of neural networks - the powerful AI models behind many of today's most advanced technologies - changes as you increase the size of the model, the amount of computing power used to train it, or the amount of data used for training. The key finding is that these different "scaling" factors - size, compute, and data - have a similar effect on the model's performance.
For example, doubling the size of the neural network might have a similar impact on performance as doubling the amount of computing power used to train it. The authors call this phenomenon "scale-time equivalence" and use it to derive a set of "scaling laws" - mathematical equations that can predict how neural network performance will scale under different conditions.
These scaling laws could be very useful, as they would allow researchers and engineers to anticipate how changes to a neural network will affect its capabilities, without having to conduct expensive and time-consuming experiments every time. This could accelerate the development of more powerful and capable AI systems.
Technical Explanation
The paper starts by observing that neural network performance scales in a predictable way with increases in model size, compute, and training data. The authors propose a unified theory to capture this scaling behavior, centered around the concept of "scale-time equivalence".
Specifically, the authors show that for a wide range of neural network architectures and tasks, doubling any of the three scaling factors (size, compute, data) has a similar multiplicative effect on performance. They derive a set of theoretical scaling laws that formalize this relationship, including power-law dependencies of performance on each scaling factor.
To validate their theory, the authors conduct extensive experiments across computer vision, language modeling, and reinforcement learning domains. They demonstrate that the proposed scaling laws accurately predict neural network performance, even when extrapolating far beyond the training regimes.
The paper also explores the underlying mechanisms behind scale-time equivalence, relating it to the information-theoretic properties of neural networks and drawing connections to other recent work on neural scaling laws.
Critical Analysis
The scaling laws proposed in this paper provide a powerful unifying framework for understanding and predicting the performance of neural networks as they are scaled up in size, compute, and data. The empirical validation across diverse tasks and architectures is impressive and lends strong support to the theory.
That said, the authors acknowledge several limitations and caveats. The scaling laws may break down at extreme scales or for radically different model architectures not represented in the experiments. Additionally, the theory does not address other important factors like architectural changes or training dynamics.
Some open questions remain, such as: What are the precise information-theoretic principles underlying scale-time equivalence? How do these scaling laws interact with other known phenomena like the "lottery ticket hypothesis" or neural network sparsity? Exploring these connections could lead to further insights.
Overall, this paper represents an important step towards a more unified and predictive theory of neural network scaling. The findings could have significant practical implications for the continued rapid progress of AI capabilities. But as with any scientific advance, there is still more work to be done to fully understand the scope and limitations of these scaling laws.
Conclusion
This paper proposes a unified theory of neural network scaling laws that can explain and predict how performance scales with model size, compute, and training data. The key insight is that these different scaling factors exhibit "scale-time equivalence", allowing the derivation of a set of powerful scaling laws.
These scaling laws could dramatically accelerate the development of more capable AI systems, as they would allow researchers to anticipate the effects of scaling without the need for extensive experimentation. While the theory has limitations, it represents an important step towards a more comprehensive understanding of neural network behavior.
Overall, this work highlights the value of theoretical frameworks in the field of deep learning, moving beyond purely empirical observations to uncover deeper principles that govern the capabilities of these powerful AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unified Neural Network Scaling Laws and Scale-time Equivalence
Akhilan Boopathy, Ila Fiete
As neural networks continue to grow in size but datasets might not, it is vital to understand how much performance improvement can be expected: is it more important to scale network size or data volume? Thus, neural network scaling laws, which characterize how test error varies with network size and data volume, have become increasingly important. However, existing scaling laws are often applicable only in limited regimes and often do not incorporate or predict well-known phenomena such as double descent. Here, we present a novel theoretical characterization of how three factors -- model size, training time, and data volume -- interact to determine the performance of deep neural networks. We first establish a theoretical and empirical equivalence between scaling the size of a neural network and increasing its training time proportionally. Scale-time equivalence challenges the current practice, wherein large models are trained for small durations, and suggests that smaller models trained over extended periods could match their efficacy. It also leads to a novel method for predicting the performance of large-scale networks from small-scale networks trained for extended epochs, and vice versa. We next combine scale-time equivalence with a linear model analysis of double descent to obtain a unified theoretical scaling law, which we confirm with experiments across vision benchmarks and network architectures. These laws explain several previously unexplained phenomena: reduced data requirements for generalization in larger models, heightened sensitivity to label noise in overparameterized models, and instances where increasing model scale does not necessarily enhance performance. Our findings hold significant implications for the practical deployment of neural networks, offering a more accessible and efficient path to training and fine-tuning large models.
Read more9/10/2024
0
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
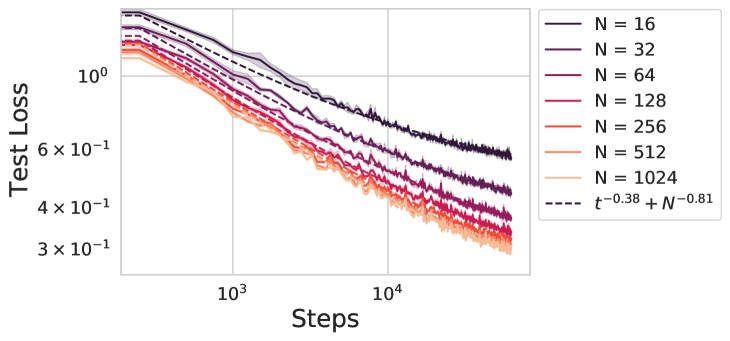
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
Read more6/26/2024

0
Information-Theoretic Foundations for Neural Scaling Laws
Hong Jun Jeon, Benjamin Van Roy
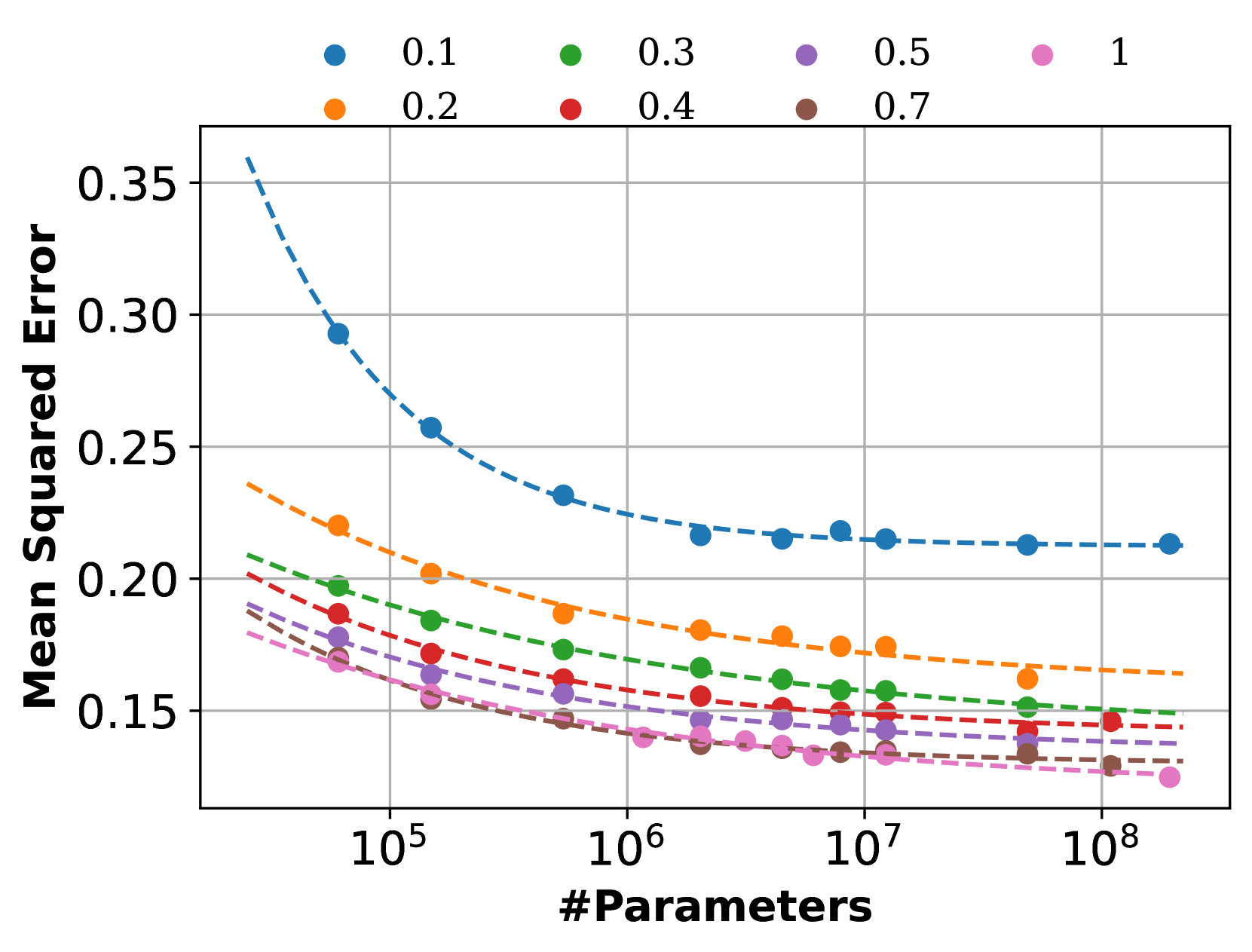
Neural scaling laws aim to characterize how out-of-sample error behaves as a function of model and training dataset size. Such scaling laws guide allocation of a computational resources between model and data processing to minimize error. However, existing theoretical support for neural scaling laws lacks rigor and clarity, entangling the roles of information and optimization. In this work, we develop rigorous information-theoretic foundations for neural scaling laws. This allows us to characterize scaling laws for data generated by a two-layer neural network of infinite width. We observe that the optimal relation between data and model size is linear, up to logarithmic factors, corroborating large-scale empirical investigations. Concise yet general results of the kind we establish may bring clarity to this topic and inform future investigations.
Read more7/2/2024
0
Neural Scaling Laws on Graphs
Jingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, Jiliang Tang
Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the scaling properties of deep graph models have not been systematically investigated, casting doubt on the feasibility of achieving large graph models through enlarging the model and dataset sizes. In this work, we delve into neural scaling laws on graphs from both model and data perspectives. We first verify the validity of such laws on graphs, establishing formulations to describe the scaling behaviors. For model scaling, we investigate the phenomenon of scaling law collapse and identify overfitting as the potential reason. Moreover, we reveal that the model depth of deep graph models can impact the model scaling behaviors, which differ from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively metric the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of edges as the metric to address the irregular graph sizes. We further demonstrate the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an essential step toward large graph models.
Read more6/11/2024