A Unified Understanding of Adversarial Vulnerability Regarding Unimodal Models and Vision-Language Pre-training Models

0

Sign in to get full access
Overview
- This paper presents a unified understanding of the adversarial vulnerability of unimodal models and vision-language pre-training models.
- The authors investigate the transferability of adversarial samples across different types of models, including image classification, visual question answering, and vision-language pre-training models.
- They find that adversarial samples crafted for one model can effectively transfer to other models, highlighting the inherent vulnerability of these systems.
Plain English Explanation
The paper explores how different AI models, like those used for image classification or answering questions about images, can be fooled by small changes to the input data. The researchers discovered that adversarial samples - slightly modified images or text that are designed to trick one model - can often be used to fool other models as well, even if they are trained for different tasks.
This means that the vulnerability to adversarial attacks is a widespread issue across many types of AI systems, not just isolated to a few specific models. The researchers provide a unified understanding of this problem, helping to explain why adversarial samples can transfer so effectively between different AI models.
This finding is significant because it suggests that the current approaches to making AI systems more robust to adversarial attacks may not be sufficient. The transferability of these adversarial samples across models indicates that the problem runs deeper than just individual model weaknesses. Addressing this fundamental vulnerability will likely require more comprehensive solutions.
Technical Explanation
The paper investigates the transferability of adversarial samples across different types of AI models, including image classification, visual question answering, and vision-language pre-training models. The authors find that adversarial samples crafted for one model can often be effectively used to fool other models as well.
To understand this unified view of adversarial vulnerability, the researchers analyze the decision boundaries and inner representations of these models. They find that the robust subspaces - regions of the input space where the models are more resistant to adversarial perturbations - tend to be aligned across different models, even if they are trained for different tasks.
This alignment of robust subspaces helps explain the high transferability of adversarial samples between models. The authors also investigate the impact of vision-language pre-training on adversarial vulnerability, finding that it can both increase and decrease a model's susceptibility to adversarial attacks depending on the specific task and training process.
Critical Analysis
The paper provides a valuable unified understanding of the widespread adversarial vulnerability across different types of AI models. This is an important contribution, as it highlights the need for more comprehensive solutions to address this fundamental issue.
However, the paper does not delve into the potential causes or underlying reasons for this alignment of robust subspaces across models. Further research is needed to fully understand the mechanisms driving this transferability of adversarial samples.
Additionally, while the authors investigate the impact of vision-language pre-training, the paper could have explored more deeply how different pre-training approaches and architectural choices might influence a model's susceptibility to adversarial attacks.
Conclusion
This paper presents a unified understanding of the adversarial vulnerability of unimodal and vision-language pre-training models, revealing the high transferability of adversarial samples across these systems. This finding suggests that the current approaches to improving adversarial robustness may not be sufficient, as the problem appears to be more fundamental in nature.
The insights provided in this paper highlight the need for more comprehensive and holistic solutions to address the inherent vulnerability of AI systems to adversarial attacks. Further research is necessary to fully understand the underlying mechanisms driving this transferability and to develop more robust and secure AI models that can better withstand such malicious inputs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Understanding of Adversarial Vulnerability Regarding Unimodal Models and Vision-Language Pre-training Models
Haonan Zheng, Xinyang Deng, Wen Jiang, Wenrui Li
With Vision-Language Pre-training (VLP) models demonstrating powerful multimodal interaction capabilities, the application scenarios of neural networks are no longer confined to unimodal domains but have expanded to more complex multimodal V+L downstream tasks. The security vulnerabilities of unimodal models have been extensively examined, whereas those of VLP models remain challenging. We note that in CV models, the understanding of images comes from annotated information, while VLP models are designed to learn image representations directly from raw text. Motivated by this discrepancy, we developed the Feature Guidance Attack (FGA), a novel method that uses text representations to direct the perturbation of clean images, resulting in the generation of adversarial images. FGA is orthogonal to many advanced attack strategies in the unimodal domain, facilitating the direct application of rich research findings from the unimodal to the multimodal scenario. By appropriately introducing text attack into FGA, we construct Feature Guidance with Text Attack (FGA-T). Through the interaction of attacking two modalities, FGA-T achieves superior attack effects against VLP models. Moreover, incorporating data augmentation and momentum mechanisms significantly improves the black-box transferability of FGA-T. Our method demonstrates stable and effective attack capabilities across various datasets, downstream tasks, and both black-box and white-box settings, offering a unified baseline for exploring the robustness of VLP models.
Read more7/26/2024

0
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Jiwei Guan, Tianyu Ding, Longbing Cao, Lei Pan, Chen Wang, Xi Zheng
Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.
Read more8/27/2024
🤯
0
Exploring Transferability of Multimodal Adversarial Samples for Vision-Language Pre-training Models with Contrastive Learning
Youze Wang, Wenbo Hu, Yinpeng Dong, Hanwang Zhang, Hang Su, Richang Hong
The integration of visual and textual data in Vision-Language Pre-training (VLP) models is crucial for enhancing vision-language understanding. However, the adversarial robustness of these models, especially in the alignment of image-text features, has not yet been sufficiently explored. In this paper, we introduce a novel gradient-based multimodal adversarial attack method, underpinned by contrastive learning, to improve the transferability of multimodal adversarial samples in VLP models. This method concurrently generates adversarial texts and images within imperceptive perturbation, employing both image-text and intra-modal contrastive loss. We evaluate the effectiveness of our approach on image-text retrieval and visual entailment tasks, using publicly available datasets in a black-box setting. Extensive experiments indicate a significant advancement over existing single-modal transfer-based adversarial attack methods and current multimodal adversarial attack approaches.
Read more7/23/2024
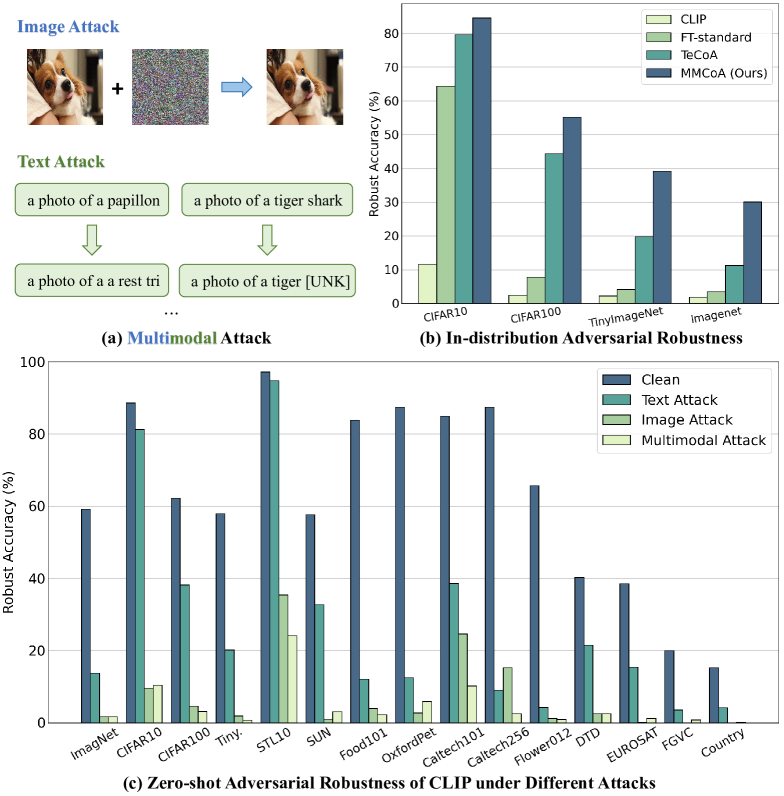
0
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
Read more7/18/2024