Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution

0
Sign in to get full access
Overview
- Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution is a research paper that proposes a novel method for efficiently enhancing the resolution of images.
- The paper focuses on developing a lightweight and computationally efficient super-resolution model that can produce high-quality results.
- The proposed approach uses a linear adaptive framework to unify multiple feature dimensions, allowing for effective super-resolution without excessive computational requirements.
Plain English Explanation
Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution presents a new way to improve the quality of low-resolution images without requiring a lot of computer power. The key idea is to combine different types of visual features in a smart, efficient manner.
Traditionally, super-resolution models have been complex and resource-intensive, making them difficult to use in real-world applications. This paper introduces a lightweight and adaptable approach that can enhance image resolution without needing a lot of computing power.
The researchers developed a linear adaptive framework that unifies multiple feature dimensions, such as spatial information and color details. This allows the model to effectively capture the necessary visual cues for high-quality super-resolution, while keeping the computational requirements relatively low.
By striking a balance between performance and efficiency, this method makes it practical to use super-resolution in a wider range of scenarios, from mobile devices to real-time applications.
Technical Explanation
Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution presents a novel linear adaptive framework for image super-resolution. The key innovation is the unification of multiple feature dimensions, including spatial, spectral, and channel-wise information, within a computationally efficient architecture.
The proposed model uses adaptive linear projections to selectively combine these diverse feature representations, allowing it to effectively capture the necessary visual cues for high-quality super-resolution without excessive computational requirements.
The authors conduct extensive experiments on popular super-resolution benchmarks, demonstrating that their lightweight approach can achieve state-of-the-art performance while requiring significantly fewer parameters and lower inference time compared to existing methods.
Critical Analysis
The paper presents a promising lightweight super-resolution approach that addresses the computational challenges often associated with high-performance super-resolution models. The unification of feature dimensions through adaptive linear projections is an interesting and novel technical contribution.
However, the paper does not extensively explore potential limitations or edge cases of the proposed method. For example, it would be valuable to understand how the model's performance scales with varying upscaling factors or different types of input images.
Additionally, the paper does not provide an in-depth analysis of the trade-offs between model complexity, inference time, and super-resolution quality. A more comprehensive evaluation of these aspects could further strengthen the claims and practical implications of the research.
Conclusion
Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution presents a novel and computationally efficient super-resolution framework that unifies multiple feature dimensions through adaptive linear projections. The promising results demonstrated in the paper suggest that this approach could enable the widespread adoption of high-quality super-resolution in a variety of real-world applications, where efficiency and performance are both critical factors.
While the paper highlights the technical merits of the proposed method, further research and analysis could provide a more comprehensive understanding of its limitations and trade-offs. Nonetheless, the core ideas introduced in this work represent an important step towards developing practical and accessible super-resolution solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution
Zhenyu Hu, Wanjie Sun
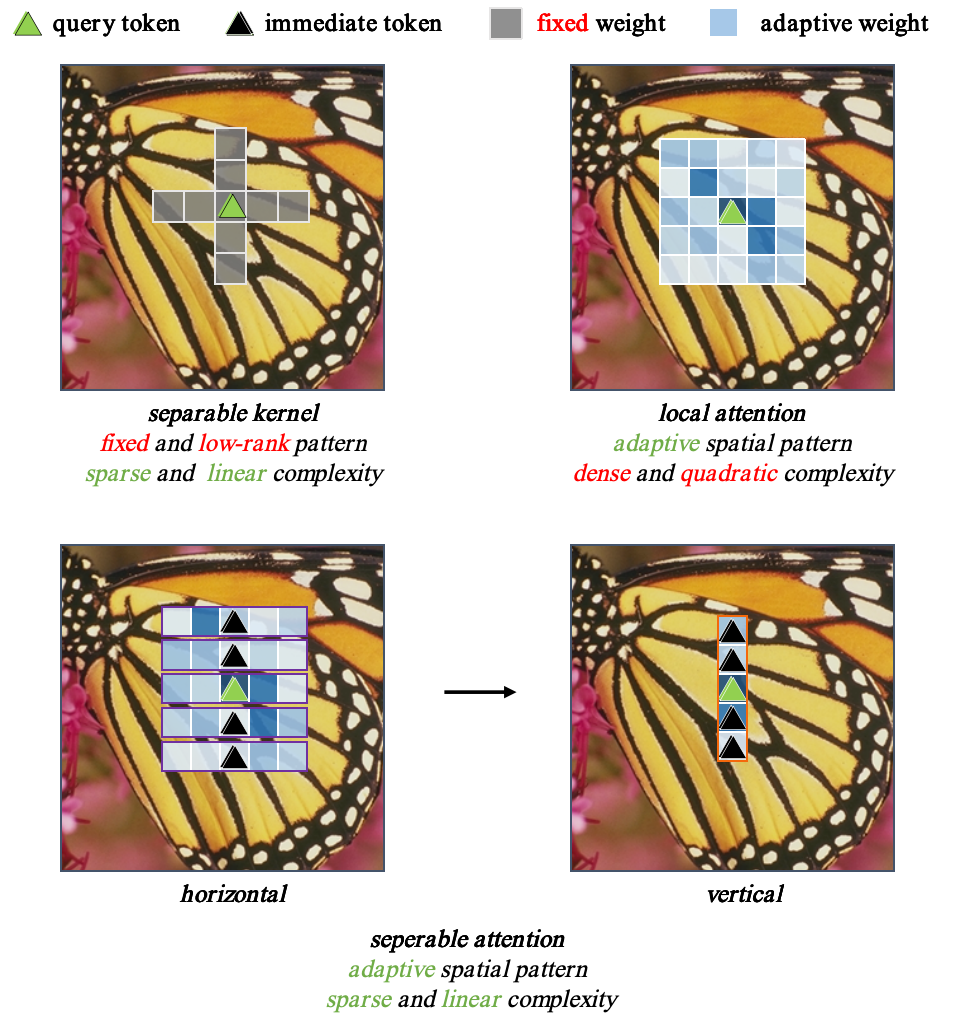
Window-based transformers have demonstrated outstanding performance in super-resolution tasks due to their adaptive modeling capabilities through local self-attention (SA). However, they exhibit higher computational complexity and inference latency than convolutional neural networks. In this paper, we first identify that the adaptability of the Transformers is derived from their adaptive spatial aggregation and advanced structural design, while their high latency results from the computational costs and memory layout transformations associated with the local SA. To simulate this aggregation approach, we propose an effective convolution-based linear focal separable attention (FSA), allowing for long-range dynamic modeling with linear complexity. Additionally, we introduce an effective dual-branch structure combined with an ultra-lightweight information exchange module (IEM) to enhance the aggregation of information by the Token Mixer. Finally, with respect to the structure, we modify the existing spatial-gate-based feedforward neural networks by incorporating a self-gate mechanism to preserve high-dimensional channel information, enabling the modeling of more complex relationships. With these advancements, we construct a convolution-based Transformer framework named the linear adaptive mixer network (LAMNet). Extensive experiments demonstrate that LAMNet achieves better performance than existing SA-based Transformer methods while maintaining the computational efficiency of convolutional neural networks, which can achieve a (3times) speedup of inference time. The code will be publicly available at: https://github.com/zononhzy/LAMNet.
Read more9/27/2024

0
LinFusion: 1 GPU, 1 Minute, 16K Image
Songhua Liu, Weihao Yu, Zhenxiong Tan, Xinchao Wang
Modern diffusion models, particularly those utilizing a Transformer-based UNet for denoising, rely heavily on self-attention operations to manage complex spatial relationships, thus achieving impressive generation performance. However, this existing paradigm faces significant challenges in generating high-resolution visual content due to its quadratic time and memory complexity with respect to the number of spatial tokens. To address this limitation, we aim at a novel linear attention mechanism as an alternative in this paper. Specifically, we begin our exploration from recently introduced models with linear complexity, e.g., Mamba2, RWKV6, Gated Linear Attention, etc, and identify two key features-attention normalization and non-causal inference-that enhance high-resolution visual generation performance. Building on these insights, we introduce a generalized linear attention paradigm, which serves as a low-rank approximation of a wide spectrum of popular linear token mixers. To save the training cost and better leverage pre-trained models, we initialize our models and distill the knowledge from pre-trained StableDiffusion (SD). We find that the distilled model, termed LinFusion, achieves performance on par with or superior to the original SD after only modest training, while significantly reducing time and memory complexity. Extensive experiments on SD-v1.5, SD-v2.1, and SD-XL demonstrate that LinFusion delivers satisfactory zero-shot cross-resolution generation performance, generating high-resolution images like 16K resolution. Moreover, it is highly compatible with pre-trained SD components, such as ControlNet and IP-Adapter, requiring no adaptation efforts. Codes are available at https://github.com/Huage001/LinFusion.
Read more9/6/2024

0
Lightweight Multiscale Feature Fusion Super-Resolution Network Based on Two-branch Convolution and Transformer
Li Ke, Liu Yukai
The single image super-resolution(SISR) algorithms under deep learning currently have two main models, one based on convolutional neural networks and the other based on Transformer. The former uses the stacking of convolutional layers with different convolutional kernel sizes to design the model, which enables the model to better extract the local features of the image; the latter uses the self-attention mechanism to design the model, which allows the model to establish long-distance dependencies between image pixel points through the self-attention mechanism and then better extract the global features of the image. However, both of the above methods face their problems. Based on this, this paper proposes a new lightweight multi-scale feature fusion network model based on two-way complementary convolutional and Transformer, which integrates the respective features of Transformer and convolutional neural networks through a two-branch network architecture, to realize the mutual fusion of global and local information. Meanwhile, considering the partial loss of information caused by the low-pixel images trained by the deep neural network, this paper designs a modular connection method of multi-stage feature supplementation to fuse the feature maps extracted from the shallow stage of the model with those extracted from the deep stage of the model, to minimize the loss of the information in the feature images that is beneficial to the image restoration as much as possible, to facilitate the obtaining of a higher-quality restored image. The practical results finally show that the model proposed in this paper is optimal in image recovery performance when compared with other lightweight models with the same amount of parameters.
Read more9/25/2024
🌐
0
Multi-scale Attention Network for Single Image Super-Resolution
Yan Wang, Yusen Li, Gang Wang, Xiaoguang Liu
ConvNets can compete with transformers in high-level tasks by exploiting larger receptive fields. To unleash the potential of ConvNet in super-resolution, we propose a multi-scale attention network (MAN), by coupling classical multi-scale mechanism with emerging large kernel attention. In particular, we proposed multi-scale large kernel attention (MLKA) and gated spatial attention unit (GSAU). Through our MLKA, we modify large kernel attention with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, thereby aggregating global and local information and avoiding potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can perform on par with SwinIR and achieve varied trade-offs between state-of-the-art performance and computations.
Read more4/16/2024