LinFusion: 1 GPU, 1 Minute, 16K Image

0

Sign in to get full access
Overview
- LinFusion is a new image generation model that can produce high-resolution 16K images using just a single GPU and a single minute of training time.
- It achieves this efficiency by using a novel linear fusion architecture, which combines the strengths of diffusion models and generative adversarial networks (GANs).
- The key insights are the use of linear additive models and gated linear transformations to create a computationally efficient yet powerful image generation system.
Plain English Explanation
LinFusion is a new type of AI model that can create very high-quality, high-resolution images. What makes LinFusion special is that it can do this using just a single graphics processing unit (GPU) and in a very short amount of time - just one minute.
Typically, creating high-resolution images with AI requires a lot of computational power and time. But the researchers behind LinFusion have come up with a clever way to make the process much more efficient. They've combined two main approaches to image generation - diffusion models and generative adversarial networks (GANs) - in a novel "linear fusion" architecture.
The key ideas behind LinFusion are:
- Linear Additive Models: Instead of using complex nonlinear transformations, LinFusion employs simple linear operations that are much faster to compute.
- Gated Linear Transformations: LinFusion uses a type of linear transformation that can selectively control the flow of information, making the model more powerful and flexible.
By using these efficient building blocks, the LinFusion model is able to generate stunning 16K resolution images in just a single minute on a single GPU. This is a major advance in the field of AI-powered image generation, potentially opening up new applications and possibilities.
Technical Explanation
LinFusion tackles the challenge of efficiently generating high-resolution images using a novel architecture that combines the strengths of diffusion models and generative adversarial networks (GANs).
The key innovations in LinFusion's design are:
- Linear Additive Models: Instead of using complex nonlinear transformations, LinFusion employs simple linear operations that are much faster to compute. This includes linear additive layers that combine multiple input features in a linear fashion.
- Gated Linear Transformations: LinFusion uses a type of linear transformation that can selectively control the flow of information through the network. This gating mechanism allows the model to be more powerful and flexible than traditional linear layers.
By leveraging these efficient building blocks, the LinFusion architecture is able to generate high-quality 16K resolution images using just a single GPU in a matter of minutes. This is a significant improvement over previous state-of-the-art image generation models, which often require massive computational resources and long training times.
Critical Analysis
The paper does a thorough job of demonstrating the effectiveness of the LinFusion approach through extensive experiments and comparisons to other models. However, it's worth noting a few potential limitations and areas for further research:
- Scalability to Even Higher Resolutions: While LinFusion can generate 16K images, it's not clear if the model can be scaled up to even higher resolutions without a significant increase in compute resources.
- Generalization to Other Domains: The experiments in the paper focus on generating natural images, but it's unclear how well the LinFusion approach would transfer to other data domains, such as medical imaging or scientific visualizations.
- Robustness and Reliability: The paper does not extensively explore the robustness of the LinFusion model to distribution shift or adversarial attacks, which are important considerations for real-world deployment.
Overall, the LinFusion paper presents a compelling advance in efficient image generation, but further research is needed to fully understand the capabilities and limitations of the approach.
Conclusion
LinFusion represents a significant breakthrough in the field of AI-powered image generation. By combining the strengths of diffusion models and GANs in a novel linear fusion architecture, the researchers have created a highly efficient system capable of generating stunning 16K resolution images using just a single GPU and a single minute of training time.
The key innovations behind LinFusion's success are the use of linear additive models and gated linear transformations, which allow the model to achieve high performance without relying on computationally expensive nonlinear operations. This could have far-reaching implications for a wide range of applications, from high-quality content creation to medical imaging and scientific visualization.
While the paper demonstrates the impressive capabilities of LinFusion, further research is needed to fully understand the model's scalability, generalization, and robustness. Nonetheless, the LinFusion approach represents a significant step forward in the field of efficient and high-quality image generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LinFusion: 1 GPU, 1 Minute, 16K Image
Songhua Liu, Weihao Yu, Zhenxiong Tan, Xinchao Wang
Modern diffusion models, particularly those utilizing a Transformer-based UNet for denoising, rely heavily on self-attention operations to manage complex spatial relationships, thus achieving impressive generation performance. However, this existing paradigm faces significant challenges in generating high-resolution visual content due to its quadratic time and memory complexity with respect to the number of spatial tokens. To address this limitation, we aim at a novel linear attention mechanism as an alternative in this paper. Specifically, we begin our exploration from recently introduced models with linear complexity, e.g., Mamba2, RWKV6, Gated Linear Attention, etc, and identify two key features-attention normalization and non-causal inference-that enhance high-resolution visual generation performance. Building on these insights, we introduce a generalized linear attention paradigm, which serves as a low-rank approximation of a wide spectrum of popular linear token mixers. To save the training cost and better leverage pre-trained models, we initialize our models and distill the knowledge from pre-trained StableDiffusion (SD). We find that the distilled model, termed LinFusion, achieves performance on par with or superior to the original SD after only modest training, while significantly reducing time and memory complexity. Extensive experiments on SD-v1.5, SD-v2.1, and SD-XL demonstrate that LinFusion delivers satisfactory zero-shot cross-resolution generation performance, generating high-resolution images like 16K resolution. Moreover, it is highly compatible with pre-trained SD components, such as ControlNet and IP-Adapter, requiring no adaptation efforts. Codes are available at https://github.com/Huage001/LinFusion.
Read more9/6/2024
0
New!Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution
Zhenyu Hu, Wanjie Sun
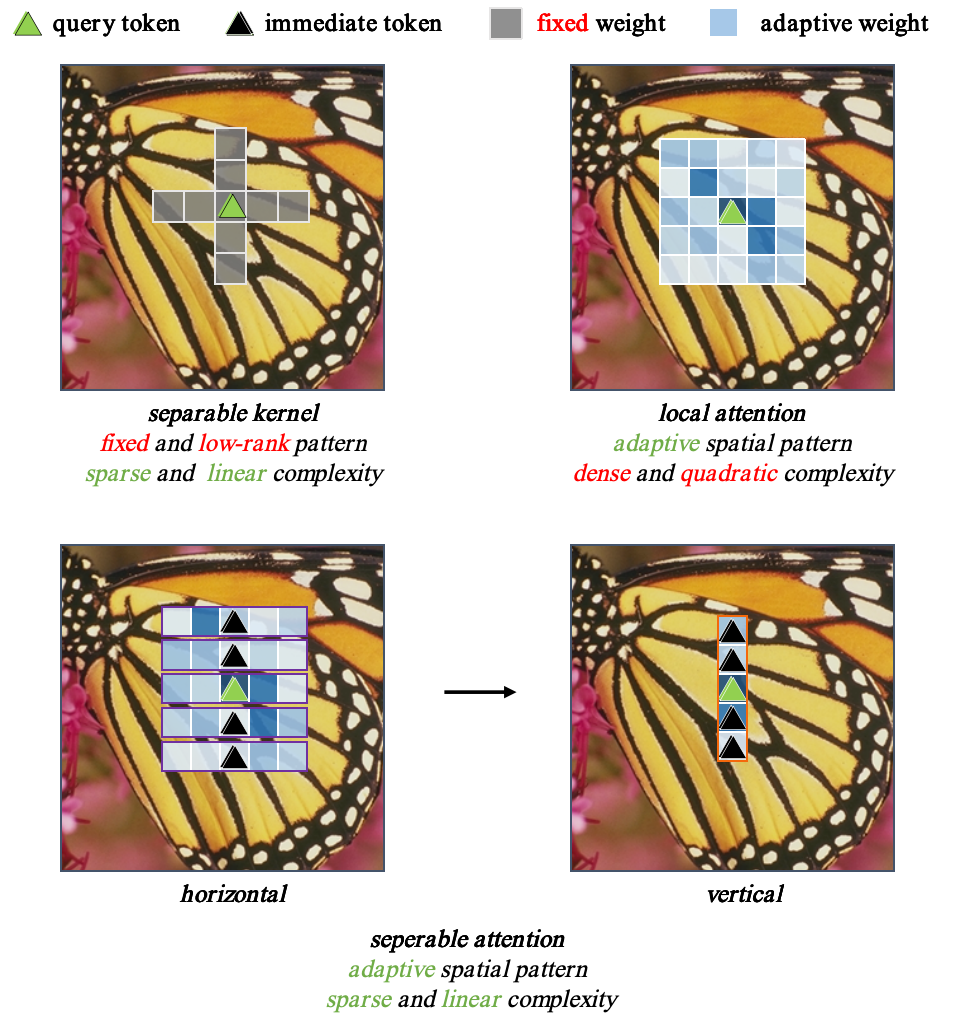
Window-based transformers have demonstrated outstanding performance in super-resolution tasks due to their adaptive modeling capabilities through local self-attention (SA). However, they exhibit higher computational complexity and inference latency than convolutional neural networks. In this paper, we first identify that the adaptability of the Transformers is derived from their adaptive spatial aggregation and advanced structural design, while their high latency results from the computational costs and memory layout transformations associated with the local SA. To simulate this aggregation approach, we propose an effective convolution-based linear focal separable attention (FSA), allowing for long-range dynamic modeling with linear complexity. Additionally, we introduce an effective dual-branch structure combined with an ultra-lightweight information exchange module (IEM) to enhance the aggregation of information by the Token Mixer. Finally, with respect to the structure, we modify the existing spatial-gate-based feedforward neural networks by incorporating a self-gate mechanism to preserve high-dimensional channel information, enabling the modeling of more complex relationships. With these advancements, we construct a convolution-based Transformer framework named the linear adaptive mixer network (LAMNet). Extensive experiments demonstrate that LAMNet achieves better performance than existing SA-based Transformer methods while maintaining the computational efficiency of convolutional neural networks, which can achieve a (3times) speedup of inference time. The code will be publicly available at: https://github.com/zononhzy/LAMNet.
Read more9/27/2024
0
MegaFusion: Extend Diffusion Models towards Higher-resolution Image Generation without Further Tuning
Haoning Wu, Shaocheng Shen, Qiang Hu, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang
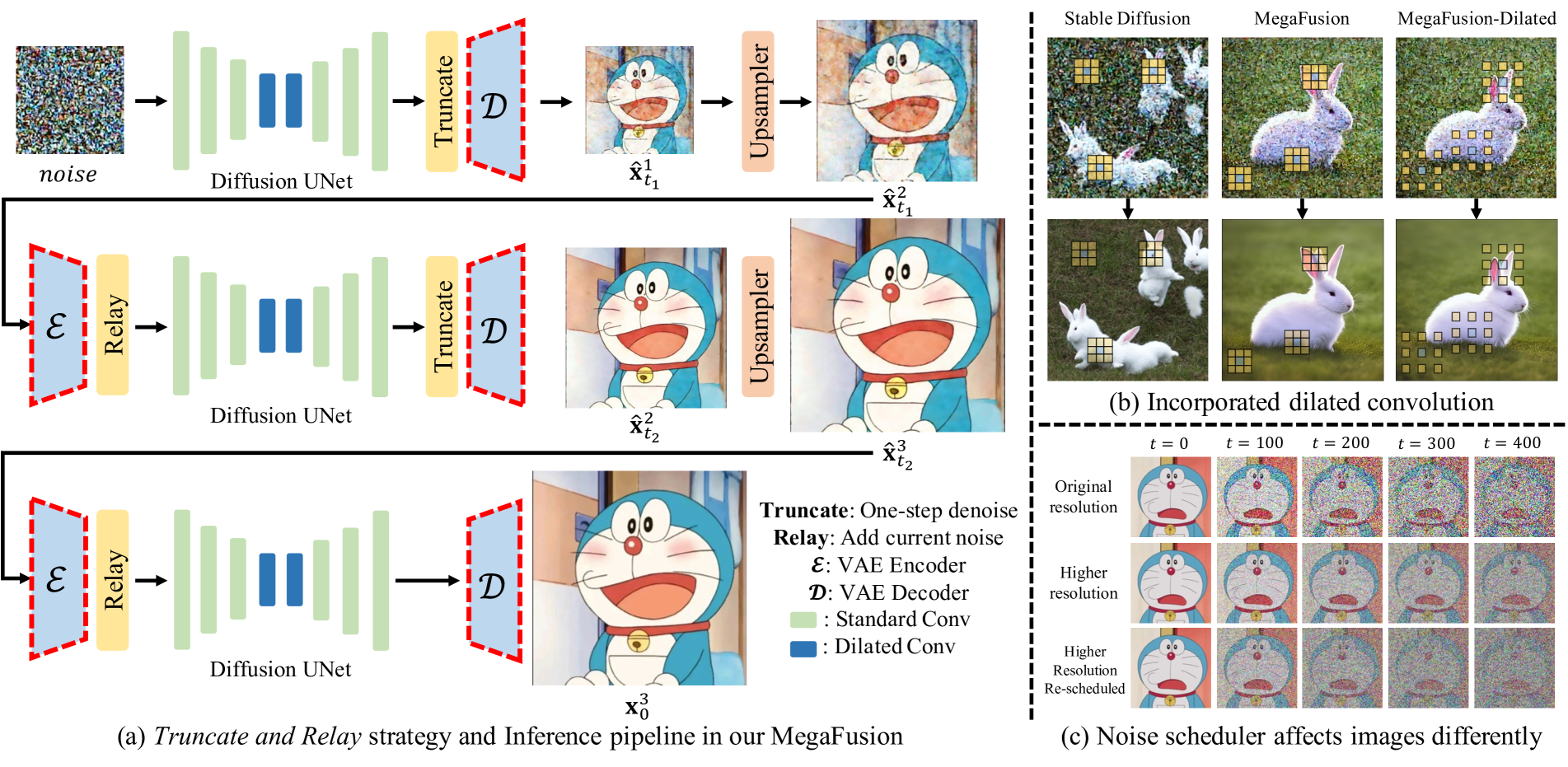
Diffusion models have emerged as frontrunners in text-to-image generation, however, their fixed image resolution during training often leads to challenges in high-resolution image generation, such as semantic deviations and object replication. This paper introduces MegaFusion, a novel approach that extends existing diffusion-based text-to-image generation models towards efficient higher-resolution generation without additional fine-tuning or extra adaptation. Specifically, we employ an innovative truncate and relay strategy to bridge the denoising processes across different resolutions, allowing for high-resolution image generation in a coarse-to-fine manner. Moreover, by integrating dilated convolutions and noise re-scheduling, we further adapt the model's priors for higher resolution. The versatility and efficacy of MegaFusion make it universally applicable to both latent-space and pixel-space diffusion models, along with other derivative models. Extensive experiments confirm that MegaFusion significantly boosts the capability of existing models to produce images of megapixels and various aspect ratios, while only requiring about 40% of the original computational cost.
Read more9/10/2024
0
Efficient generative adversarial networks using linear additive-attention Transformers
Emilio Morales-Juarez, Gibran Fuentes-Pineda
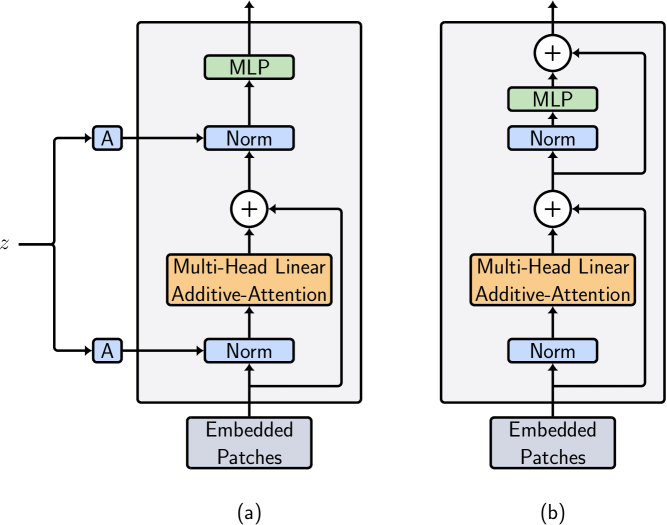
Although the capacity of deep generative models for image generation, such as Diffusion Models (DMs) and Generative Adversarial Networks (GANs), has dramatically improved in recent years, much of their success can be attributed to computationally expensive architectures. This has limited their adoption and use to research laboratories and companies with large resources, while significantly raising the carbon footprint for training, fine-tuning, and inference. In this work, we present LadaGAN, an efficient generative adversarial network that is built upon a novel Transformer block named Ladaformer. The main component of this block is a linear additive-attention mechanism that computes a single attention vector per head instead of the quadratic dot-product attention. We employ Ladaformer in both the generator and discriminator, which reduces the computational complexity and overcomes the training instabilities often associated with Transformer GANs. LadaGAN consistently outperforms existing convolutional and Transformer GANs on benchmark datasets at different resolutions while being significantly more efficient. Moreover, LadaGAN shows competitive performance compared to state-of-the-art multi-step generative models (e.g. DMs) using orders of magnitude less computational resources.
Read more8/22/2024