UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition

0
🌐
Sign in to get full access
Overview
- This paper introduces the UniMER dataset, the first large-scale dataset for studying Mathematical Expression Recognition (MER) in real-world scenarios.
- The dataset includes a training set of 1 million instances (UniMER-1M) and a carefully designed test set (UniMER-Test) that reflects the diversity of mathematical expressions found in the real world.
- The paper also presents UniMERNet, an innovative framework that enhances MER performance by incorporating a Length-Aware Module and using data augmentation techniques.
Plain English Explanation
The researchers behind this paper have created a new dataset called UniMER to help improve the recognition of mathematical expressions in real-world situations. Mathematical expression recognition (MER) is the task of accurately identifying and understanding the mathematical equations and formulas found in things like textbooks, research papers, and even handwritten notes.
The UniMER dataset is unique because it is much larger and more diverse than previous MER datasets. It includes over 1 million training examples (UniMER-1M) that cover a wide range of mathematical expressions, from simple equations to complex, multi-line formulas. The researchers also carefully designed a separate test set (UniMER-Test) to reflect the types of mathematical expressions commonly seen in the real world.
In addition to the dataset, the researchers introduced a new AI model called UniMERNet that is specifically designed to tackle MER challenges. UniMERNet includes a "Length-Aware Module" that helps it process mathematical expressions of varying lengths and complexity more effectively. The model also uses data augmentation techniques to make it more robust to different types of noise or distortion that can occur in real-world images of mathematical expressions.
The researchers found that UniMERNet outperforms existing MER models, setting new benchmarks for accuracy and recognition quality. This suggests the UniMER dataset and UniMERNet framework could be valuable tools for advancing the state-of-the-art in mathematical expression recognition, with potential applications in areas like education, scientific publishing, and even handwritten note-taking.
Technical Explanation
The UniMER dataset provides the first large-scale study on Mathematical Expression Recognition (MER) for real-world scenarios. The dataset includes a training set called UniMER-1M with 1 million diverse instances, as well as a carefully designed test set called UniMER-Test that reflects the distribution of mathematical expressions found in the real world.
To enhance MER performance in practical settings, the researchers introduce the Universal Mathematical Expression Recognition Network (UniMERNet). UniMERNet incorporates a Length-Aware Module that can efficiently process mathematical expressions of varying lengths, enabling the model to handle more complex formulas with greater accuracy.
Additionally, UniMERNet leverages the UniMER-1M training data and employs image augmentation techniques to improve the model's robustness under different noise conditions. The researchers' extensive experiments demonstrate that UniMERNet outperforms existing MER models, setting new benchmarks across various scenarios and ensuring superior recognition quality for real-world applications.
The UniMER dataset and the UniMERNet model are publicly available at https://github.com/opendatalab/UniMERNet, providing a valuable resource for the research community to advance the field of mathematical expression recognition.
Critical Analysis
The UniMER dataset and UniMERNet framework represent a significant contribution to the field of mathematical expression recognition. By providing a large-scale, diverse dataset that reflects real-world scenarios, the researchers have created a valuable resource for training and evaluating MER models.
However, the paper does not extensively discuss the potential limitations or challenges of the UniMER dataset. For example, it would be interesting to know if the dataset covers a representative distribution of mathematical expressions found in different domains, such as scientific publications, educational materials, or handwritten notes. Expanding the dataset's diversity and applicability to a wider range of real-world use cases could further strengthen the research.
Additionally, while the UniMERNet model demonstrates improved performance, the paper could benefit from a more in-depth analysis of the model's strengths, weaknesses, and specific architectural choices. Comparing UniMERNet's performance to other state-of-the-art MER models, and discussing potential areas for further improvement, would provide a more comprehensive understanding of the model's capabilities and limitations.
Overall, the UniMER dataset and UniMERNet framework represent a significant step forward in mathematical expression recognition research. Continued refinement and expansion of the dataset, along with a deeper exploration of the model's design and performance, could further solidify the impact of this work and drive progress in this important field.
Conclusion
The UniMER dataset and UniMERNet framework introduced in this paper represent a substantial contribution to the field of mathematical expression recognition. By providing a large-scale, diverse dataset and an innovative model designed to handle complex real-world scenarios, the researchers have laid the groundwork for further advancements in this area.
The availability of the UniMER dataset and UniMERNet model can enable researchers and developers to train more robust and accurate MER systems, with potential applications in educational technology, scientific publishing, and various other domains where the accurate recognition of mathematical expressions is crucial. The comprehensive benchmarking and evaluation presented in this work set a new standard for MER research, paving the way for even more progress in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
UniMERNet: A Universal Network for Real-World Mathematical Expression Recognition
Bin Wang, Zhuangcheng Gu, Guang Liang, Chao Xu, Bo Zhang, Botian Shi, Conghui He
The paper introduces the UniMER dataset, marking the first study on Mathematical Expression Recognition (MER) targeting complex real-world scenarios. The UniMER dataset includes a large-scale training set, UniMER-1M, which offers unprecedented scale and diversity with one million training instances to train high-quality, robust models. Additionally, UniMER features a meticulously designed, diverse test set, UniMER-Test, which covers a variety of formula distributions found in real-world scenarios, providing a more comprehensive and fair evaluation. To better utilize the UniMER dataset, the paper proposes a Universal Mathematical Expression Recognition Network (UniMERNet), tailored to the characteristics of formula recognition. UniMERNet consists of a carefully designed encoder that incorporates detail-aware and local context features, and an optimized decoder for accelerated performance. Extensive experiments conducted using the UniMER-1M dataset and UniMERNet demonstrate that training on the large-scale UniMER-1M dataset can produce a more generalizable formula recognition model, significantly outperforming all previous datasets. Furthermore, the introduction of UniMERNet enhances the model's performance in formula recognition, achieving higher accuracy and speeds. All data, models, and code are available at https://github.com/opendatalab/UniMERNet.
Read more9/6/2024

0
MathNet: A Data-Centric Approach for Printed Mathematical Expression Recognition
Felix M. Schmitt-Koopmann, Elaine M. Huang, Hans-Peter Hutter, Thilo Stadelmann, Alireza Darvishy
Printed mathematical expression recognition (MER) models are usually trained and tested using LaTeX-generated mathematical expressions (MEs) as input and the LaTeX source code as ground truth. As the same ME can be generated by various different LaTeX source codes, this leads to unwanted variations in the ground truth data that bias test performance results and hinder efficient learning. In addition, the use of only one font to generate the MEs heavily limits the generalization of the reported results to realistic scenarios. We propose a data-centric approach to overcome this problem, and present convincing experimental results: Our main contribution is an enhanced LaTeX normalization to map any LaTeX ME to a canonical form. Based on this process, we developed an improved version of the benchmark dataset im2latex-100k, featuring 30 fonts instead of one. Second, we introduce the real-world dataset realFormula, with MEs extracted from papers. Third, we developed a MER model, MathNet, based on a convolutional vision transformer, with superior results on all four test sets (im2latex-100k, im2latexv2, realFormula, and InftyMDB-1), outperforming the previous state of the art by up to 88.3%.
Read more4/23/2024
👁️
0
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Stephen Mayhew, Terra Blevins, Shuheng Liu, Marek v{S}uppa, Hila Gonen, Joseph Marvin Imperial, Borje F. Karlsson, Peiqin Lin, Nikola Ljubev{s}i'c, LJ Miranda, Barbara Plank, Arij Riabi, Yuval Pinter
We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
Read more7/2/2024
0
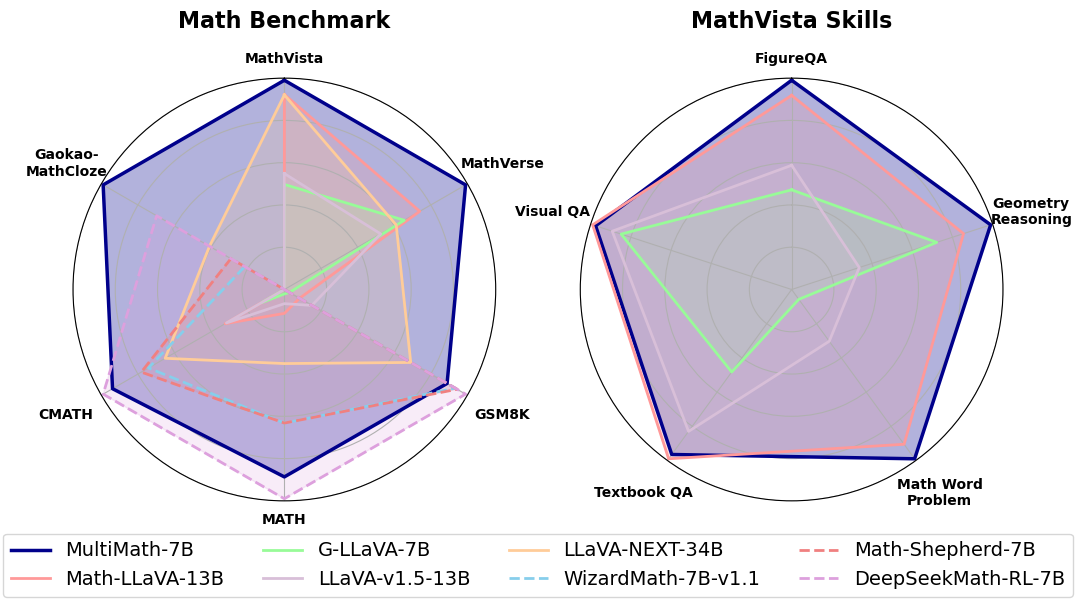
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024