Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark

0
👁️
Sign in to get full access
Overview
- This paper introduces Universal NER (UNER), an open and community-driven project to develop high-quality, cross-lingual named entity recognition (NER) benchmarks.
- The goal of UNER is to facilitate and standardize multilingual NER research by providing consistent annotations across a diverse set of languages.
- UNER v1 contains 18 datasets with named entity annotations in a cross-lingual schema, covering 12 languages.
- The paper details the dataset creation and composition, and provides initial modeling baselines for both in-language and cross-lingual learning settings.
- The data, code, and fitted models are publicly released.
Plain English Explanation
The researchers have created a new project called Universal NER (UNER) that aims to develop high-quality named entity recognition (NER) benchmarks for many different languages. NER is the task of identifying and categorizing named entities like people, organizations, and locations in text.
The key idea behind UNER is to provide consistent annotations for named entities across a diverse set of languages. This will help researchers working on multilingual NER models, as they can use the UNER datasets to train and evaluate their models in a standardized way.
The first version of UNER (v1) contains 18 datasets covering 12 languages, all annotated using a common schema. The researchers explain how they created these datasets and provide initial baseline results for training NER models both within a single language and across multiple languages.
Importantly, the researchers have made the UNER datasets, code, and trained models publicly available. This allows other researchers and developers to build upon this work and advance the state of the art in multilingual NER.
Technical Explanation
The UNER project aims to develop high-quality, cross-lingual named entity recognition (NER) benchmarks to facilitate and standardize multilingual NER research. The researchers have created UNER v1, which consists of 18 datasets annotated with named entities across 12 diverse languages, using a common annotation schema.
To create the UNER datasets, the researchers collected text from various sources, including news articles, Wikipedia, and social media. They then hired annotators fluent in each target language to label the named entities in the text according to a predefined set of entity types. The researchers took steps to ensure the consistency of the annotations across languages.
The paper provides initial modeling baselines for both in-language and cross-lingual NER learning settings. For in-language learning, the researchers fine-tuned multilingual language models like mBERT and XLM-R on the UNER datasets. For cross-lingual learning, they explored techniques like zero-shot transfer and cross-lingual knowledge distillation.
The results show that the UNER datasets can be effectively used to train high-performing NER models, both within individual languages and across multiple languages. The researchers have made the UNER datasets, code, and fitted models publicly available to support further research and development in this area.
Critical Analysis
The UNER project is a valuable contribution to the field of multilingual NER research. By providing high-quality, cross-lingual datasets, the researchers have addressed a key challenge in this domain - the lack of standardized evaluation benchmarks.
However, the paper does not delve into the potential biases or limitations of the UNER datasets. For example, the datasets may not be representative of all text genres or domains, and the annotation process could be subject to human biases. The researchers could have discussed these caveats and how they plan to address them in future iterations of UNER.
Additionally, the paper focuses primarily on the dataset creation and initial modeling baselines. It would have been helpful to see more in-depth analysis of the cross-lingual learning techniques and their relative strengths and weaknesses. This could provide valuable insights for researchers working on more advanced multilingual NER models.
Despite these minor limitations, the UNER project is a significant step forward in promoting standardization and collaboration in multilingual NER research. The publicly released data and code will undoubtedly spur further advancements in this important field.
Conclusion
The UNER project introduces a valuable resource for multilingual named entity recognition research. By providing high-quality, cross-lingual datasets with consistent annotations, the researchers have created a foundation for advancing the state of the art in this domain.
The initial modeling baselines demonstrate the effectiveness of UNER for training NER models, both within individual languages and across multiple languages. The public release of the data, code, and fitted models will enable other researchers and developers to build upon this work and drive further progress in multilingual NER.
Overall, the UNER project represents an important step towards more standardized and collaborative research in the field of multilingual natural language processing. As the project evolves and expands, it has the potential to significantly impact the development of robust and inclusive NLP systems that can operate effectively across a wide range of languages.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Universal NER: A Gold-Standard Multilingual Named Entity Recognition Benchmark
Stephen Mayhew, Terra Blevins, Shuheng Liu, Marek v{S}uppa, Hila Gonen, Joseph Marvin Imperial, Borje F. Karlsson, Peiqin Lin, Nikola Ljubev{s}i'c, LJ Miranda, Barbara Plank, Arij Riabi, Yuval Pinter
We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.
Read more7/2/2024

0
UNER: A Unified Prediction Head for Named Entity Recognition in Visually-rich Documents
Yi Tu, Chong Zhang, Ya Guo, Huan Chen, Jinyang Tang, Huijia Zhu, Qi Zhang
The recognition of named entities in visually-rich documents (VrD-NER) plays a critical role in various real-world scenarios and applications. However, the research in VrD-NER faces three major challenges: complex document layouts, incorrect reading orders, and unsuitable task formulations. To address these challenges, we propose a query-aware entity extraction head, namely UNER, to collaborate with existing multi-modal document transformers to develop more robust VrD-NER models. The UNER head considers the VrD-NER task as a combination of sequence labeling and reading order prediction, effectively addressing the issues of discontinuous entities in documents. Experimental evaluations on diverse datasets demonstrate the effectiveness of UNER in improving entity extraction performance. Moreover, the UNER head enables a supervised pre-training stage on various VrD-NER datasets to enhance the document transformer backbones and exhibits substantial knowledge transfer from the pre-training stage to the fine-tuning stage. By incorporating universal layout understanding, a pre-trained UNER-based model demonstrates significant advantages in few-shot and cross-linguistic scenarios and exhibits zero-shot entity extraction abilities.
Read more8/13/2024
0
Beyond Boundaries: Learning a Universal Entity Taxonomy across Datasets and Languages for Open Named Entity Recognition
Yuming Yang, Wantong Zhao, Caishuang Huang, Junjie Ye, Xiao Wang, Huiyuan Zheng, Yang Nan, Yuran Wang, Xueying Xu, Kaixin Huang, Yunke Zhang, Tao Gui, Qi Zhang, Xuanjing Huang
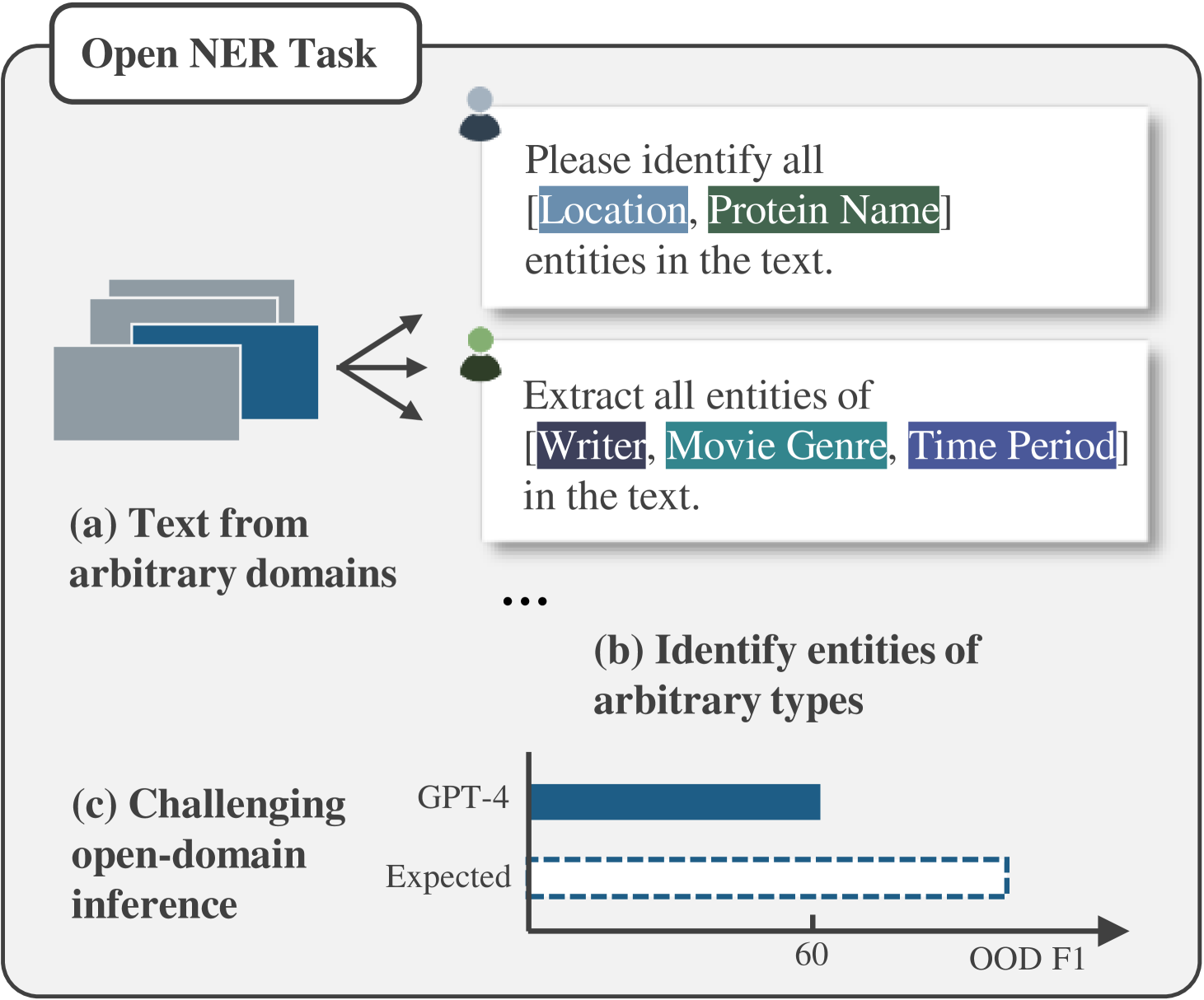
Open Named Entity Recognition (NER), which involves identifying arbitrary types of entities from arbitrary domains, remains challenging for Large Language Models (LLMs). Recent studies suggest that fine-tuning LLMs on extensive NER data can boost their performance. However, training directly on existing datasets faces issues due to inconsistent entity definitions and redundant data, limiting LLMs to dataset-specific learning and hindering out-of-domain generalization. To address this, we present B2NERD, a cohesive and efficient dataset for Open NER, normalized from 54 existing English or Chinese datasets using a two-step approach. First, we detect inconsistent entity definitions across datasets and clarify them by distinguishable label names to construct a universal taxonomy of 400+ entity types. Second, we address redundancy using a data pruning strategy that selects fewer samples with greater category and semantic diversity. Comprehensive evaluation shows that B2NERD significantly improves LLMs' generalization on Open NER. Our B2NER models, trained on B2NERD, outperform GPT-4 by 6.8-12.0 F1 points and surpass previous methods in 3 out-of-domain benchmarks across 15 datasets and 6 languages.
Read more6/18/2024

0
MSNER: A Multilingual Speech Dataset for Named Entity Recognition
Quentin Meeus, Marie-Francine Moens, Hugo Van hamme
While extensively explored in text-based tasks, Named Entity Recognition (NER) remains largely neglected in spoken language understanding. Existing resources are limited to a single, English-only dataset. This paper addresses this gap by introducing MSNER, a freely available, multilingual speech corpus annotated with named entities. It provides annotations to the VoxPopuli dataset in four languages (Dutch, French, German, and Spanish). We have also releasing an efficient annotation tool that leverages automatic pre-annotations for faster manual refinement. This results in 590 and 15 hours of silver-annotated speech for training and validation, alongside a 17-hour, manually-annotated evaluation set. We further provide an analysis comparing silver and gold annotations. Finally, we present baseline NER models to stimulate further research on this newly available dataset.
Read more5/21/2024