UNIT: Backdoor Mitigation via Automated Neural Distribution Tightening

0
Sign in to get full access
Overview
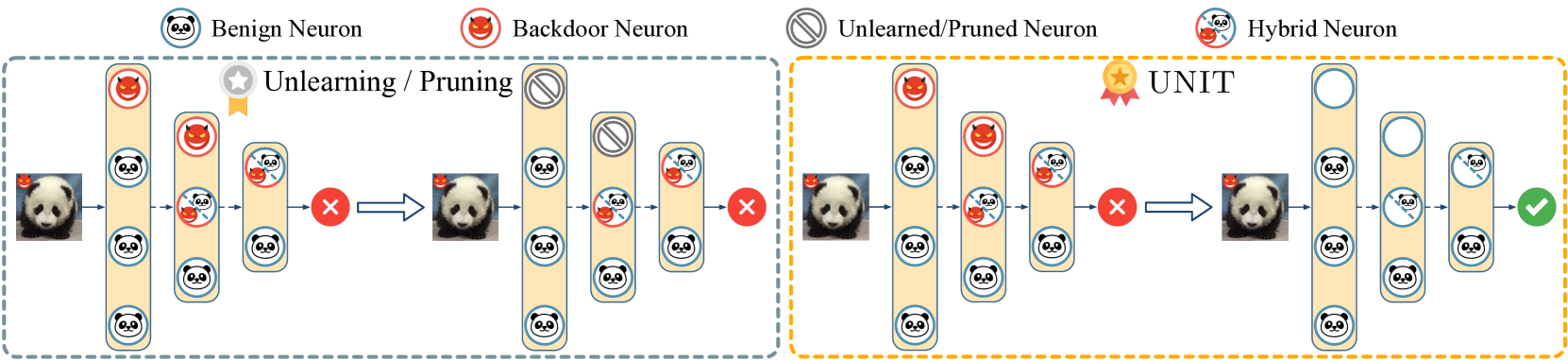
- This paper proposes a new method called "UNIT" (Backdoor Mitigation via Automated Neural Distribution Tightening) to defend against backdoor attacks in deep neural networks.
- Backdoor attacks are a type of security vulnerability where an attacker can cause a model to misclassify specific inputs in a targeted way, even if the model performs well on normal data.
- The UNIT method aims to tighten the neural distributions of a model to make it more robust against such backdoor attacks.
Plain English Explanation
The paper describes a new technique called "UNIT" that can help protect AI models from a type of security threat known as a "backdoor attack". Backdoor attacks are when an attacker finds a way to sneak in malicious behavior into an AI model, so that the model will make mistakes on certain inputs, even though it works correctly on normal data.
The UNIT method tries to fix this problem by tightening up the internal workings of the AI model, making it harder for attackers to insert these backdoors. The key idea is to automatically adjust the neural distributions - the patterns of activations inside the model - to be more compact and well-behaved, reducing the space for backdoors to hide.
This is an important problem to solve, as backdoor attacks are a growing concern for the security of AI systems. By making models more resilient to these types of attacks, the UNIT method could help make AI more robust and trustworthy for real-world applications.
Technical Explanation
The UNIT method works by performing an "automated neural distribution tightening" process on a pre-trained model. This involves two key steps:
-
Reverse Engineering: The first step is to analyze the internal activations of the model to identify potential backdoors. This is done by reverse engineering the model to understand how it makes decisions.
-
Distribution Tightening: Based on the reverse engineering insights, UNIT then applies a series of targeted regularization techniques to tighten the neural distributions of the model. This reduces the flexibility of the model's internal representations, making it harder for backdoors to be injected.
The paper demonstrates that UNIT can effectively mitigate a variety of backdoor attacks on different model architectures and datasets, without significantly impacting the model's normal performance.
Critical Analysis
The UNIT method presents a promising approach to defending against backdoor attacks, but there are a few potential limitations to consider:
-
The paper only evaluates UNIT on a limited set of backdoor attack scenarios. More comprehensive testing would be needed to assess its robustness across a wider range of attack types and model architectures.
-
The exact reverse engineering and distribution tightening techniques used in UNIT are not fully explained. More details on the implementation would be helpful to understand the method's broader applicability.
-
While UNIT aims to maintain normal model performance, the impact of the tightening process on other desirable model properties (e.g. generalization, interpretability) is not explored. Further investigation into potential tradeoffs would be valuable.
Overall, the UNIT method represents an important step forward in addressing the critical issue of backdoor security in AI systems. However, continued research and evaluation will be needed to fully understand its capabilities and limitations.
Conclusion
The UNIT method proposed in this paper offers a novel approach to mitigating backdoor attacks in deep neural networks. By reverse engineering models to identify potential backdoors and then applying targeted techniques to tighten the neural distributions, UNIT can make models more robust against these types of security vulnerabilities.
As AI systems become increasingly ubiquitous, ensuring their reliability and trustworthiness in the face of adversarial threats like backdoor attacks will be crucial. The UNIT method provides a promising direction for enhancing the security of AI, which could have significant implications for the safe and responsible deployment of these technologies in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UNIT: Backdoor Mitigation via Automated Neural Distribution Tightening
Siyuan Cheng, Guangyu Shen, Kaiyuan Zhang, Guanhong Tao, Shengwei An, Hanxi Guo, Shiqing Ma, Xiangyu Zhang
Deep neural networks (DNNs) have demonstrated effectiveness in various fields. However, DNNs are vulnerable to backdoor attacks, which inject a unique pattern, called trigger, into the input to cause misclassification to an attack-chosen target label. While existing works have proposed various methods to mitigate backdoor effects in poisoned models, they tend to be less effective against recent advanced attacks. In this paper, we introduce a novel post-training defense technique UNIT that can effectively eliminate backdoor effects for a variety of attacks. In specific, UNIT approximates a unique and tight activation distribution for each neuron in the model. It then proactively dispels substantially large activation values that exceed the approximated boundaries. Our experimental results demonstrate that UNIT outperforms 7 popular defense methods against 14 existing backdoor attacks, including 2 advanced attacks, using only 5% of clean training data. UNIT is also cost efficient. The code is accessible at https://github.com/Megum1/UNIT.
Read more7/17/2024

0
Universal Post-Training Reverse-Engineering Defense Against Backdoors in Deep Neural Networks
Xi Li, Hang Wang, David J. Miller, George Kesidis
A variety of defenses have been proposed against backdoors attacks on deep neural network (DNN) classifiers. Universal methods seek to reliably detect and/or mitigate backdoors irrespective of the incorporation mechanism used by the attacker, while reverse-engineering methods often explicitly assume one. In this paper, we describe a new detector that: relies on internal feature map of the defended DNN to detect and reverse-engineer the backdoor and identify its target class; can operate post-training (without access to the training dataset); is highly effective for various incorporation mechanisms (i.e., is universal); and which has low computational overhead and so is scalable. Our detection approach is evaluated for different attacks on benchmark CIFAR-10 and CIFAR-100 image classifiers.
Read more5/24/2024
⛏️
0
Unveiling and Mitigating Backdoor Vulnerabilities based on Unlearning Weight Changes and Backdoor Activeness
Weilin Lin, Li Liu, Shaokui Wei, Jianze Li, Hui Xiong
The security threat of backdoor attacks is a central concern for deep neural networks (DNNs). Recently, without poisoned data, unlearning models with clean data and then learning a pruning mask have contributed to backdoor defense. Additionally, vanilla fine-tuning with those clean data can help recover the lost clean accuracy. However, the behavior of clean unlearning is still under-explored, and vanilla fine-tuning unintentionally induces back the backdoor effect. In this work, we first investigate model unlearning from the perspective of weight changes and gradient norms, and find two interesting observations in the backdoored model: 1) the weight changes between poison and clean unlearning are positively correlated, making it possible for us to identify the backdoored-related neurons without using poisoned data; 2) the neurons of the backdoored model are more active (i.e., larger changes in gradient norm) than those in the clean model, suggesting the need to suppress the gradient norm during fine-tuning. Then, we propose an effective two-stage defense method. In the first stage, an efficient Neuron Weight Change (NWC)-based Backdoor Reinitialization is proposed based on observation 1). In the second stage, based on observation 2), we design an Activeness-Aware Fine-Tuning to replace the vanilla fine-tuning. Extensive experiments, involving eight backdoor attacks on three benchmark datasets, demonstrate the superior performance of our proposed method compared to recent state-of-the-art backdoor defense approaches.
Read more5/31/2024
0
Mitigating Backdoor Attacks using Activation-Guided Model Editing
Felix Hsieh, Huy H. Nguyen, AprilPyone MaungMaung, Dmitrii Usynin, Isao Echizen
Backdoor attacks compromise the integrity and reliability of machine learning models by embedding a hidden trigger during the training process, which can later be activated to cause unintended misbehavior. We propose a novel backdoor mitigation approach via machine unlearning to counter such backdoor attacks. The proposed method utilizes model activation of domain-equivalent unseen data to guide the editing of the model's weights. Unlike the previous unlearning-based mitigation methods, ours is computationally inexpensive and achieves state-of-the-art performance while only requiring a handful of unseen samples for unlearning. In addition, we also point out that unlearning the backdoor may cause the whole targeted class to be unlearned, thus introducing an additional repair step to preserve the model's utility after editing the model. Experiment results show that the proposed method is effective in unlearning the backdoor on different datasets and trigger patterns.
Read more7/11/2024