BadActs: A Universal Backdoor Defense in the Activation Space

0

Sign in to get full access
Overview
- This paper introduces a new defense mechanism called "BadActs" that aims to protect deep neural networks from backdoor attacks.
- Backdoor attacks are a type of security vulnerability where an attacker can covertly manipulate a model's behavior by triggering a specific input pattern.
- BadActs proposes a defense that operates in the activation space of the model, rather than the input space, to detect and mitigate these backdoor attacks.
Plain English Explanation
The paper describes a new technique called "BadActs" that can help protect AI models from a type of security flaw known as a "backdoor attack." Backdoor attacks allow an attacker to secretly change how an AI model behaves by triggering a specific input pattern. For example, an attacker could make an image classification model consistently misclassify images of stop signs as speed limit signs whenever a certain pattern is present in the image.
The key idea behind BadActs is to monitor the internal activations of the AI model, rather than just the inputs and outputs, to detect when a backdoor attack is being triggered. By analyzing the patterns in the model's internal activity, BadActs can identify when the model is behaving suspiciously and take action to mitigate the attack.
This approach is designed to be more effective than previous defenses that focus only on the input data, as backdoor attacks can be crafted to avoid detection at the input level. By looking under the hood of the model, BadActs can catch these more subtle and sophisticated attacks.
Technical Explanation
The paper first provides an overview of the backdoor attack threat and reviews related work on defense mechanisms. It then introduces the BadActs defense, which operates by monitoring the activation patterns of the target model during inference.
The key components of BadActs are:
-
Activation Fingerprinting: The defense creates a "fingerprint" of the model's normal activation patterns by analyzing its behavior on a set of clean (non-backdoored) inputs. This fingerprint serves as a baseline for detecting anomalous activations.
-
Activation Anomaly Detection: During inference, BadActs continuously compares the model's current activations to the established fingerprint. If the activations deviate significantly from the norm, it is flagged as a potential backdoor trigger.
-
Mitigation: When a backdoor trigger is detected, BadActs can take various mitigation actions, such as blocking the input, perturbing the model's activations, or completely disabling the model.
The paper evaluates BadActs on several benchmark datasets and backdoor attack techniques, including invisible backdoor attacks and simple horizontal class backdoors. The results demonstrate that BadActs can effectively detect and mitigate a wide range of backdoor attacks, outperforming previous defense methods.
Critical Analysis
The paper presents a novel and promising approach to defending against backdoor attacks in deep neural networks. By focusing on the activation patterns of the model, rather than just the input and output, BadActs can detect more subtle and sophisticated attacks that may bypass input-level defenses.
However, the paper does not address the potential impact of this defense on the model's normal performance or the computational overhead it may introduce. There are also open questions about the generalizability of the approach, as the fingerprinting and anomaly detection mechanisms may need to be tailored to different model architectures and attack scenarios.
Additionally, the paper does not explore the potential for adversarial attacks against the BadActs defense itself. An attacker could potentially find ways to circumvent the activation-based detection by crafting backdoor triggers that mimic the model's normal activation patterns.
Overall, the BadActs defense represents an important step forward in the ongoing arms race between attackers and defenders in the AI security landscape. However, further research is needed to address the potential limitations and to explore the broader implications of this approach.
Conclusion
The "BadActs" defense proposed in this paper offers a novel way to protect deep neural networks from backdoor attacks by monitoring the models' internal activation patterns. This approach can detect more sophisticated attacks that may bypass input-level defenses, making it a promising contribution to the field of AI security.
While the paper demonstrates the effectiveness of BadActs on several benchmark scenarios, further research is needed to fully understand its limitations and potential for adversarial attacks. Nonetheless, the core idea of leveraging the model's activation space for backdoor detection represents an important advancement in the ongoing efforts to secure AI systems against malicious actors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BadActs: A Universal Backdoor Defense in the Activation Space
Biao Yi, Sishuo Chen, Yiming Li, Tong Li, Baolei Zhang, Zheli Liu
Backdoor attacks pose an increasingly severe security threat to Deep Neural Networks (DNNs) during their development stage. In response, backdoor sample purification has emerged as a promising defense mechanism, aiming to eliminate backdoor triggers while preserving the integrity of the clean content in the samples. However, existing approaches have been predominantly focused on the word space, which are ineffective against feature-space triggers and significantly impair performance on clean data. To address this, we introduce a universal backdoor defense that purifies backdoor samples in the activation space by drawing abnormal activations towards optimized minimum clean activation distribution intervals. The advantages of our approach are twofold: (1) By operating in the activation space, our method captures from surface-level information like words to higher-level semantic concepts such as syntax, thus counteracting diverse triggers; (2) the fine-grained continuous nature of the activation space allows for more precise preservation of clean content while removing triggers. Furthermore, we propose a detection module based on statistical information of abnormal activations, to achieve a better trade-off between clean accuracy and defending performance.
Read more5/21/2024

0
Mitigating Deep Reinforcement Learning Backdoors in the Neural Activation Space
Sanyam Vyas, Chris Hicks, Vasilios Mavroudis
This paper investigates the threat of backdoors in Deep Reinforcement Learning (DRL) agent policies and proposes a novel method for their detection at runtime. Our study focuses on elusive in-distribution backdoor triggers. Such triggers are designed to induce a deviation in the behaviour of a backdoored agent while blending into the expected data distribution to evade detection. Through experiments conducted in the Atari Breakout environment, we demonstrate the limitations of current sanitisation methods when faced with such triggers and investigate why they present a challenging defence problem. We then evaluate the hypothesis that backdoor triggers might be easier to detect in the neural activation space of the DRL agent's policy network. Our statistical analysis shows that indeed the activation patterns in the agent's policy network are distinct in the presence of a trigger, regardless of how well the trigger is concealed in the environment. Based on this, we propose a new defence approach that uses a classifier trained on clean environment samples and detects abnormal activations. Our results show that even lightweight classifiers can effectively prevent malicious actions with considerable accuracy, indicating the potential of this research direction even against sophisticated adversaries.
Read more7/23/2024
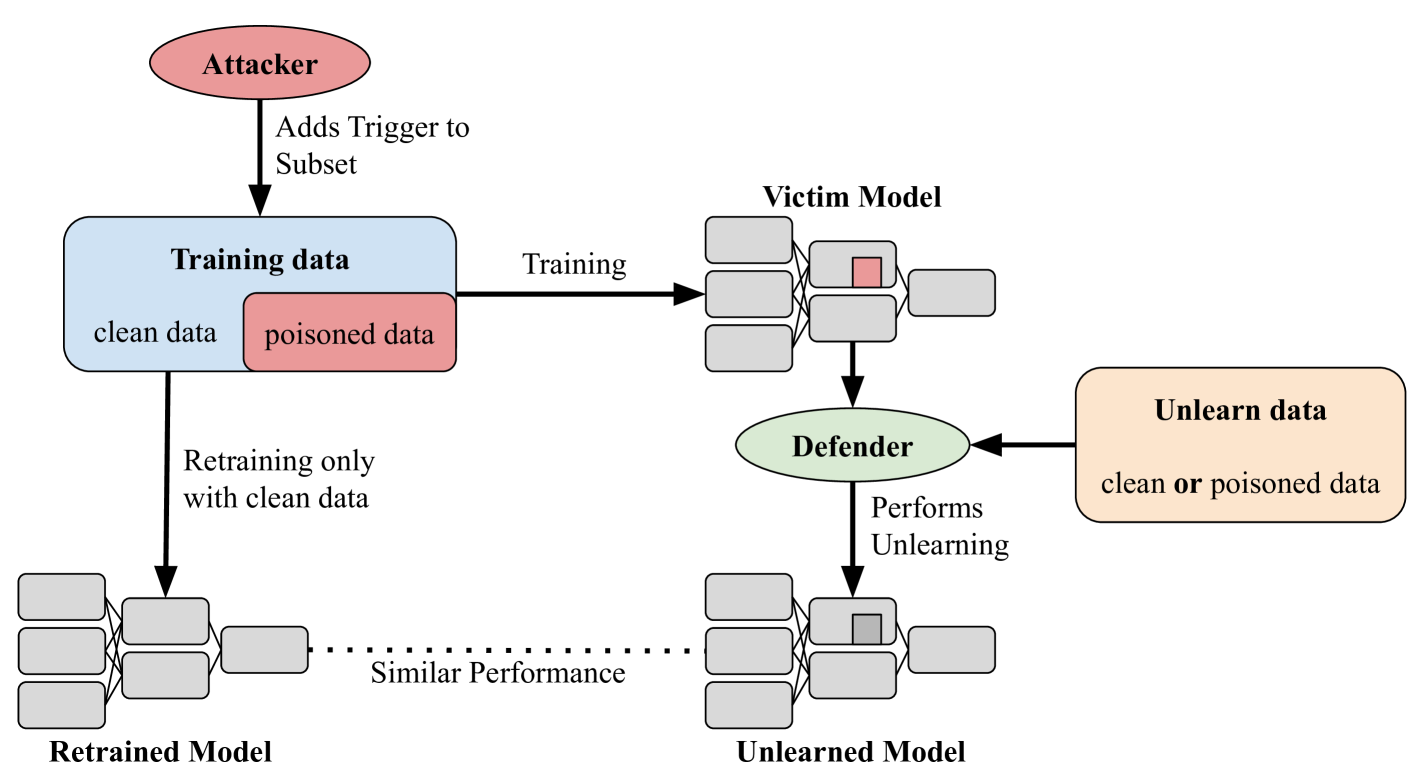
0
Mitigating Backdoor Attacks using Activation-Guided Model Editing
Felix Hsieh, Huy H. Nguyen, AprilPyone MaungMaung, Dmitrii Usynin, Isao Echizen
Backdoor attacks compromise the integrity and reliability of machine learning models by embedding a hidden trigger during the training process, which can later be activated to cause unintended misbehavior. We propose a novel backdoor mitigation approach via machine unlearning to counter such backdoor attacks. The proposed method utilizes model activation of domain-equivalent unseen data to guide the editing of the model's weights. Unlike the previous unlearning-based mitigation methods, ours is computationally inexpensive and achieves state-of-the-art performance while only requiring a handful of unseen samples for unlearning. In addition, we also point out that unlearning the backdoor may cause the whole targeted class to be unlearned, thus introducing an additional repair step to preserve the model's utility after editing the model. Experiment results show that the proposed method is effective in unlearning the backdoor on different datasets and trigger patterns.
Read more7/11/2024

0
Breaking the False Sense of Security in Backdoor Defense through Re-Activation Attack
Mingli Zhu, Siyuan Liang, Baoyuan Wu
Deep neural networks face persistent challenges in defending against backdoor attacks, leading to an ongoing battle between attacks and defenses. While existing backdoor defense strategies have shown promising performance on reducing attack success rates, can we confidently claim that the backdoor threat has truly been eliminated from the model? To address it, we re-investigate the characteristics of the backdoored models after defense (denoted as defense models). Surprisingly, we find that the original backdoors still exist in defense models derived from existing post-training defense strategies, and the backdoor existence is measured by a novel metric called backdoor existence coefficient. It implies that the backdoors just lie dormant rather than being eliminated. To further verify this finding, we empirically show that these dormant backdoors can be easily re-activated during inference, by manipulating the original trigger with well-designed tiny perturbation using universal adversarial attack. More practically, we extend our backdoor reactivation to black-box scenario, where the defense model can only be queried by the adversary during inference, and develop two effective methods, i.e., query-based and transfer-based backdoor re-activation attacks. The effectiveness of the proposed methods are verified on both image classification and multimodal contrastive learning (i.e., CLIP) tasks. In conclusion, this work uncovers a critical vulnerability that has never been explored in existing defense strategies, emphasizing the urgency of designing more robust and advanced backdoor defense mechanisms in the future.
Read more5/31/2024