Universal Approximation Theory: Foundations for Parallelism in Neural Networks

0

Sign in to get full access
Overview
- This paper explores the foundations of parallelism in neural networks through the lens of Universal Approximation Theory (UAT).
- UAT is a foundational theory in deep learning that demonstrates the ability of neural networks to approximate any continuous function.
- The authors investigate how this theory can inform the design and training of neural networks to leverage parallel computation.
Plain English Explanation
Neural networks are a type of machine learning model inspired by the human brain. They are composed of interconnected nodes, called neurons, that work together to process and transform input data into useful outputs. The Universal Approximation Theorem is a key theoretical result that shows neural networks can approximate any continuous function, given enough neurons and the right training.
In this paper, the authors explore how this powerful theoretical result can be used to design neural networks that can be trained and executed in parallel. Parallel computation is the ability to split a task into smaller parts and process them simultaneously, which can significantly speed up the training and deployment of neural networks.
The authors investigate the fundamental properties of neural networks that enable parallel computation, such as the role of the network architecture and the training process. They provide insights into how the Universal Approximation Theorem can guide the development of neural network models that are inherently parallel, unlocking new possibilities for efficient and scalable deep learning applications.
Technical Explanation
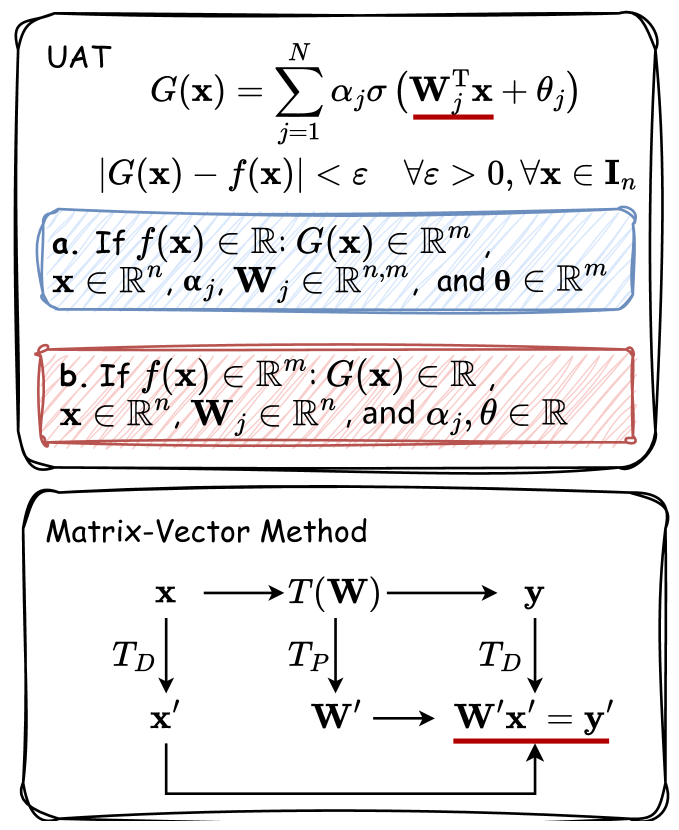
The paper begins by introducing the Universal Approximation Theorem (UAT), which is a foundational result in deep learning that demonstrates the ability of neural networks to approximate any continuous function. The authors then explore how this theoretical result can inform the design and training of neural networks to leverage parallel computation.
The authors first analyze the relationship between the structure of a neural network and its ability to be trained and executed in parallel. They discuss how the network architecture, such as the number and configuration of layers, can impact the potential for parallelism. Additionally, they examine the role of the training process, including the choice of optimization algorithms and the handling of dependencies between neurons and layers.
The paper also presents several key insights into the fundamental properties of neural networks that enable parallel computation. For example, the authors explore the concept of weight permutation, which refers to the ability to rearrange the weights of a neural network without changing its functional behavior. They demonstrate how this property can be leveraged to enable parallelism during both training and inference.
Furthermore, the authors introduce the concept of inter-layer and intra-layer parallelism, which describe different approaches to leveraging parallel computation within a neural network. They discuss the trade-offs and considerations involved in implementing these forms of parallelism, providing a comprehensive framework for designing and optimizing neural networks for parallel execution.
Critical Analysis
The paper provides a valuable contribution to the field of deep learning by exploring the theoretical foundations of parallelism in neural networks. The authors' investigation of the Universal Approximation Theorem and its implications for parallel computation is an important step in advancing the efficiency and scalability of deep learning models.
One potential limitation of the research is the focus on the theoretical aspects, without extensive experimental validation. While the authors present some conceptual examples and insights, further empirical studies would be needed to fully demonstrate the practical benefits of the proposed approaches.
Additionally, the paper could have explored the potential challenges and trade-offs associated with implementing parallel computation in neural networks, such as the impact on model performance, memory usage, or energy efficiency. Addressing these practical considerations would help to provide a more well-rounded understanding of the practical implications of the research.
Overall, this paper lays a strong theoretical foundation for leveraging the power of parallel computation in neural networks, paving the way for further research and development in this area. By continuing to explore the interplay between universal approximation theory and parallel processing, the field of deep learning can unlock new avenues for efficient and scalable machine learning applications.
Conclusion
This paper presents a comprehensive exploration of the foundations of parallelism in neural networks through the lens of Universal Approximation Theory. The authors delve into the relationship between network architecture, training processes, and the ability to leverage parallel computation, providing valuable insights into the design and optimization of neural networks for efficient and scalable deep learning.
By understanding the theoretical underpinnings of parallelism in neural networks, researchers and practitioners can develop more powerful and versatile deep learning models that can take advantage of advanced hardware and distributed computing resources. This work lays the groundwork for future advancements in the field, paving the way for innovative applications that harness the full potential of parallel processing in neural networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal Approximation Theory: Foundations for Parallelism in Neural Networks
Wei Wang, Qing Li
Neural networks are increasingly evolving towards training large models with big data, a method that has demonstrated superior performance across many tasks. However, this approach introduces an urgent problem: current deep learning models are predominantly serial, meaning that as the number of network layers increases, so do the training and inference times. This is unacceptable if deep learning is to continue advancing. Therefore, this paper proposes a deep learning parallelization strategy based on the Universal Approximation Theorem (UAT). From this foundation, we designed a parallel network called Para-Former to test our theory. Unlike traditional serial models, the inference time of Para-Former does not increase with the number of layers, significantly accelerating the inference speed of multi-layer networks. Experimental results validate the effectiveness of this network.
Read more8/20/2024

0
A Survey on Universal Approximation Theorems
Midhun T Augustine
This paper discusses various theorems on the approximation capabilities of neural networks (NNs), which are known as universal approximation theorems (UATs). The paper gives a systematic overview of UATs starting from the preliminary results on function approximation, such as Taylor's theorem, Fourier's theorem, Weierstrass approximation theorem, Kolmogorov - Arnold representation theorem, etc. Theoretical and numerical aspects of UATs are covered from both arbitrary width and depth.
Read more7/19/2024
0
Universal Approximation Theory: The basic theory for deep learning-based computer vision models
Wei Wang, Qing Li
Computer vision (CV) is one of the most crucial fields in artificial intelligence. In recent years, a variety of deep learning models based on convolutional neural networks (CNNs) and Transformers have been designed to tackle diverse problems in CV. These algorithms have found practical applications in areas such as robotics and facial recognition. Despite the increasing power of current CV models, several fundamental questions remain unresolved: Why do CNNs require deep layers? What ensures the generalization ability of CNNs? Why do residual-based networks outperform fully convolutional networks like VGG? What is the fundamental difference between residual-based CNNs and Transformer-based networks? Why can CNNs utilize LoRA and pruning techniques? The root cause of these questions lies in the lack of a robust theoretical foundation for deep learning models in CV. To address these critical issues and techniques, we employ the Universal Approximation Theorem (UAT) to provide a theoretical basis for convolution- and Transformer-based models in CV. By doing so, we aim to elucidate these questions from a theoretical perspective.
Read more8/20/2024
0
Universal Approximation Theory: The basic theory for large language models
Wei Wang, Qing Li
Language models have emerged as a critical area of focus in artificial intelligence, particularly with the introduction of groundbreaking innovations like ChatGPT. Large-scale Transformer networks have quickly become the leading approach for advancing natural language processing algorithms. Built on the Transformer architecture, these models enable interactions that closely mimic human communication and, equipped with extensive knowledge, can even assist in guiding human tasks. Despite their impressive capabilities and growing complexity, a key question remains-the theoretical foundations of large language models (LLMs). What makes Transformer so effective for powering intelligent language applications, such as translation and coding? What underlies LLMs' ability for In-Context Learning (ICL)? How does the LoRA scheme enhance the fine-tuning of LLMs? And what supports the practicality of pruning LLMs? To address these critical questions and explore the technological strategies within LLMs, we leverage the Universal Approximation Theory (UAT) to offer a theoretical backdrop, shedding light on the mechanisms that underpin these advancements.
Read more8/20/2024