Universal Approximation Theory: The basic theory for large language models

0
Sign in to get full access
Overview
- The paper discusses the Universal Approximation Theory, which provides the fundamental theoretical basis for large language models (LLMs).
- LLMs, such as GPT-3 and its successors, have revolutionized the field of natural language processing and have found numerous applications in various domains.
- The Universal Approximation Theory establishes that these LLMs have the capability to approximate any continuous function, given a sufficiently large and complex neural network architecture.
Plain English Explanation
The paper explores the mathematical theory that underpins the incredible capabilities of large language models (LLMs) like GPT-3 and its successors. These models have transformed the field of natural language processing, allowing machines to understand and generate human-like text with remarkable accuracy.
The key to this breakthrough lies in the Universal Approximation Theory, which states that neural networks, if properly designed and trained, can approximate any continuous function. In other words, LLMs can learn to mimic any pattern or relationship in text data, given a sufficiently complex architecture and enough training data.
This theory essentially means that LLMs have the potential to learn and understand the nuances of human language, from the simple to the most complex. By leveraging this theoretical foundation, researchers and engineers have been able to create LLMs that can perform a wide range of tasks, from answering questions to generating coherent and contextual responses.
The practical implications of the Universal Approximation Theory are far-reaching, as it provides a solid mathematical basis for the development and advancement of LLMs. This theory not only helps us understand the inner workings of these models but also serves as a guidepost for future research and innovation in the field of natural language processing.
Technical Explanation
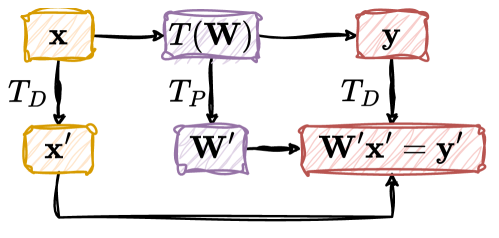
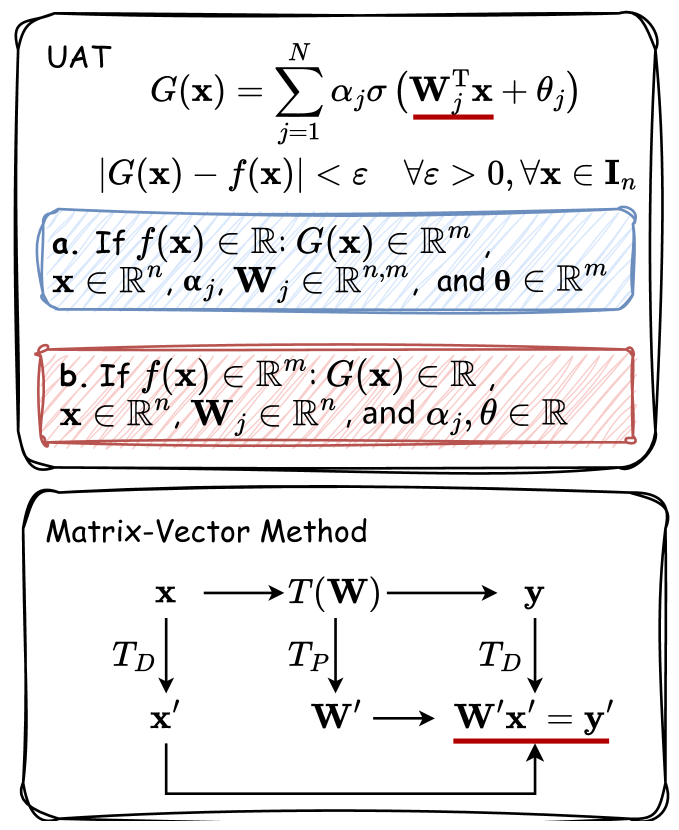
The Universal Approximation Theory is a fundamental concept in the field of neural networks and machine learning, and it forms the theoretical foundation for the remarkable capabilities of large language models (LLMs).
The theory states that a feedforward neural network with a single hidden layer, containing a finite number of neurons, can approximate any continuous function on a compact subset of ℝn, provided that the activation function of the hidden layer neurons is non-constant, bounded, and continuous. This means that, in theory, a neural network of sufficient complexity can learn to mimic any pattern or relationship in the data it is trained on.
In the context of LLMs, this theory suggests that these models, which are essentially deep neural networks trained on vast amounts of text data, have the potential to learn and understand the complex structures and semantics of human language. By leveraging this theoretical foundation, researchers have been able to develop LLMs that can perform a wide range of natural language processing tasks, from generating coherent and contextual responses to answering questions with human-like accuracy.
The Universal Approximation Theory not only helps us understand the underlying principles that enable the remarkable capabilities of LLMs but also serves as a guidepost for future research and development in the field of natural language processing. By building on this theoretical foundation, researchers can continue to push the boundaries of what is possible with these models, potentially leading to even more advanced and versatile language understanding and generation capabilities.
Critical Analysis
The Universal Approximation Theory provides a strong theoretical foundation for the capabilities of large language models, but it is important to recognize its limitations and potential caveats.
One key limitation is that the theory only guarantees the approximation of continuous functions, not their exact representation. In practice, this means that LLMs may not be able to perfectly replicate certain linguistic patterns or nuances, and their performance may be subject to various sources of error or bias.
Additionally, the theory assumes the availability of a sufficiently large and complex neural network architecture, as well as extensive training data. In reality, the training of LLMs is a complex and resource-intensive process, and the models may still exhibit limitations and biases that are not fully addressed by the underlying theory.
Furthermore, the Universal Approximation Theory does not provide insights into the specific mechanisms or learning processes that allow LLMs to achieve their impressive performance. While the theory establishes the potential capabilities of these models, it does not necessarily explain the how and why of their inner workings.
Despite these limitations, the Universal Approximation Theory remains a crucial starting point for understanding the fundamental principles that enable the success of large language models. By continuing to explore and refine this theory, as well as expanding our understanding of the practical challenges and considerations in LLM development, researchers can work towards even more advanced and reliable natural language processing systems.
Conclusion
The Universal Approximation Theory provides the essential mathematical foundation for the remarkable capabilities of large language models (LLMs), which have revolutionized the field of natural language processing. This theory establishes that neural networks, if properly designed and trained, have the potential to approximate any continuous function, including the complex patterns and semantics of human language.
By leveraging this theoretical basis, researchers and engineers have been able to develop LLMs that can perform a wide range of tasks, from answering questions to generating coherent and contextual responses. The practical implications of the Universal Approximation Theory are far-reaching, as it provides a solid mathematical foundation for the continued advancement and application of natural language processing technologies.
While the theory has its limitations, it serves as a crucial starting point for understanding the inner workings of LLMs and guiding future research and development in this rapidly evolving field. By building upon this theoretical foundation and addressing the practical challenges involved in LLM development, the research community can work towards even more advanced and capable language models that can benefit a wide range of applications and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal Approximation Theory: The basic theory for large language models
Wei Wang, Qing Li
Language models have emerged as a critical area of focus in artificial intelligence, particularly with the introduction of groundbreaking innovations like ChatGPT. Large-scale Transformer networks have quickly become the leading approach for advancing natural language processing algorithms. Built on the Transformer architecture, these models enable interactions that closely mimic human communication and, equipped with extensive knowledge, can even assist in guiding human tasks. Despite their impressive capabilities and growing complexity, a key question remains-the theoretical foundations of large language models (LLMs). What makes Transformer so effective for powering intelligent language applications, such as translation and coding? What underlies LLMs' ability for In-Context Learning (ICL)? How does the LoRA scheme enhance the fine-tuning of LLMs? And what supports the practicality of pruning LLMs? To address these critical questions and explore the technological strategies within LLMs, we leverage the Universal Approximation Theory (UAT) to offer a theoretical backdrop, shedding light on the mechanisms that underpin these advancements.
Read more8/20/2024
0
Universal Approximation Theory: The basic theory for deep learning-based computer vision models
Wei Wang, Qing Li
Computer vision (CV) is one of the most crucial fields in artificial intelligence. In recent years, a variety of deep learning models based on convolutional neural networks (CNNs) and Transformers have been designed to tackle diverse problems in CV. These algorithms have found practical applications in areas such as robotics and facial recognition. Despite the increasing power of current CV models, several fundamental questions remain unresolved: Why do CNNs require deep layers? What ensures the generalization ability of CNNs? Why do residual-based networks outperform fully convolutional networks like VGG? What is the fundamental difference between residual-based CNNs and Transformer-based networks? Why can CNNs utilize LoRA and pruning techniques? The root cause of these questions lies in the lack of a robust theoretical foundation for deep learning models in CV. To address these critical issues and techniques, we employ the Universal Approximation Theorem (UAT) to provide a theoretical basis for convolution- and Transformer-based models in CV. By doing so, we aim to elucidate these questions from a theoretical perspective.
Read more8/20/2024
0
A Survey on Large Language Models from Concept to Implementation
Chen Wang, Jin Zhao, Jiaqi Gong
Recent advancements in Large Language Models (LLMs), particularly those built on Transformer architectures, have significantly broadened the scope of natural language processing (NLP) applications, transcending their initial use in chatbot technology. This paper investigates the multifaceted applications of these models, with an emphasis on the GPT series. This exploration focuses on the transformative impact of artificial intelligence (AI) driven tools in revolutionizing traditional tasks like coding and problem-solving, while also paving new paths in research and development across diverse industries. From code interpretation and image captioning to facilitating the construction of interactive systems and advancing computational domains, Transformer models exemplify a synergy of deep learning, data analysis, and neural network design. This survey provides an in-depth look at the latest research in Transformer models, highlighting their versatility and the potential they hold for transforming diverse application sectors, thereby offering readers a comprehensive understanding of the current and future landscape of Transformer-based LLMs in practical applications.
Read more5/29/2024
34
Large Language Models for Mathematicians
Simon Frieder, Julius Berner, Philipp Petersen, Thomas Lukasiewicz
Large language models (LLMs) such as ChatGPT have received immense interest for their general-purpose language understanding and, in particular, their ability to generate high-quality text or computer code. For many professions, LLMs represent an invaluable tool that can speed up and improve the quality of work. In this note, we discuss to what extent they can aid professional mathematicians. We first provide a mathematical description of the transformer model used in all modern language models. Based on recent studies, we then outline best practices and potential issues and report on the mathematical abilities of language models. Finally, we shed light on the potential of LLMs to change how mathematicians work.
Read more4/3/2024