Universal Approximation Theory: The basic theory for deep learning-based computer vision models

0
Sign in to get full access
Overview
- Universal Approximation Theory (UAT) is the foundational theory behind deep learning-based computer vision models.
- UAT explains how deep neural networks can approximate any continuous function to arbitrary precision, enabling their powerful performance in complex tasks.
- This paper provides a plain English summary and technical explanation of UAT, as well as a critical analysis of its implications and limitations.
Plain English Explanation
Universal Approximation Theory is the key mathematical theory that underpins the remarkable success of deep learning models in computer vision. It explains how these complex neural networks can learn to perform tasks like image classification or object detection with such impressive accuracy.
The core idea is that deep neural networks can approximate any continuous function to any desired level of precision. This means they can learn to map any input (like an image) to any output (like the object labels in that image) as long as that mapping is a continuous mathematical function.
To visualize this, imagine trying to draw any arbitrary shape on a piece of paper using only straight line segments. By adding more and more segments, you can approximate the shape with greater and greater accuracy, until it's essentially indistinguishable from the original. Deep neural networks work the same way - they use millions of simple computational "units" (the artificial neurons) to collectively approximate highly complex functions.
This powerful approximation capability is what allows deep learning models to excel at computer vision tasks that were once thought to be beyond the reach of machines. The networks can learn rich, intricate representations of visual data and map them to the desired outputs, without the need for explicit, hand-coded rules or features.
Technical Explanation
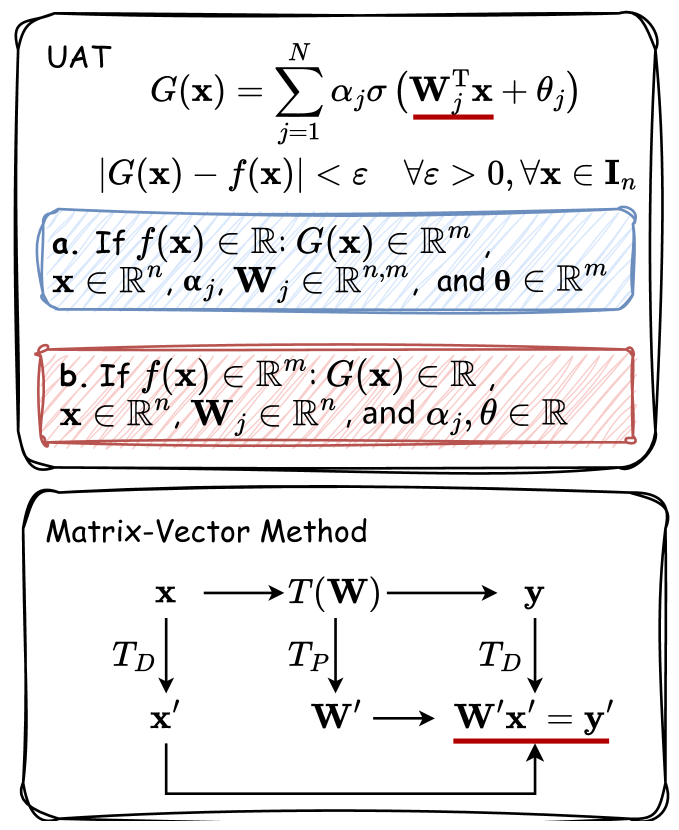
Universal Approximation Theory states that a simple feedforward neural network with a single hidden layer containing a finite number of neurons can approximate any continuous function on a compact input domain to any desired degree of accuracy. This means deep neural networks, which are composed of multiple hidden layers, can theoretically model any continuous function with arbitrary precision.
The key insight is that the nonlinear activation functions used in neural network layers, such as the sigmoid or ReLU functions, give the networks the representational power to approximate arbitrarily complex functions. By stacking multiple layers, the networks can build up hierarchical representations that capture intricate patterns in the data.
Numerous theoretical results have been proven to formalize and extend this basic UAT principle. For example, studies have shown that UAT holds not just for feedforward networks, but also for more advanced architectures like convolutional neural networks that are particularly well-suited for computer vision tasks.
Other work has explored the statistical properties of UAT, shedding light on the network training process and generalization capabilities. This theoretical foundation has been crucial for guiding the development of powerful deep learning models in computer vision and beyond.
Critical Analysis
While Universal Approximation Theory provides a powerful theoretical underpinning for deep learning, it also has important limitations that should be considered. The theory only guarantees the existence of a network that can approximate a target function - it does not indicate how to actually find that network or train it efficiently.
In practice, training deep neural networks can be challenging due to issues like vanishing gradients, poor optimization, and the need for massive amounts of training data. The UAT guarantee of universal approximation does not automatically translate to easy trainability or generalization in real-world applications.
Additionally, UAT only addresses the network's representational capacity, not its ability to actually learn the target function from finite sample data. Further statistical and algorithmic analyses are needed to fully understand the learning dynamics and generalization properties of deep models.
Overall, Universal Approximation Theory provides a foundational mathematical framework for understanding the potential of deep learning, but significant additional work is required to realize that potential in practical, high-performing computer vision systems.
Conclusion
Universal Approximation Theory is the core theoretical basis for the remarkable success of deep learning-based computer vision models. By proving that deep neural networks can approximate any continuous function with arbitrary precision, UAT explains the remarkable representational power that enables these models to excel at complex visual tasks.
While UAT is a powerful theoretical result, it also has important limitations that require further research and analysis. Practical implementation and training of deep models remains challenging, and additional statistical and algorithmic insights are needed to fully harness the potential of this foundational theory. Nevertheless, UAT provides an invaluable mathematical framework for understanding and advancing the field of deep learning and computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal Approximation Theory: The basic theory for deep learning-based computer vision models
Wei Wang, Qing Li
Computer vision (CV) is one of the most crucial fields in artificial intelligence. In recent years, a variety of deep learning models based on convolutional neural networks (CNNs) and Transformers have been designed to tackle diverse problems in CV. These algorithms have found practical applications in areas such as robotics and facial recognition. Despite the increasing power of current CV models, several fundamental questions remain unresolved: Why do CNNs require deep layers? What ensures the generalization ability of CNNs? Why do residual-based networks outperform fully convolutional networks like VGG? What is the fundamental difference between residual-based CNNs and Transformer-based networks? Why can CNNs utilize LoRA and pruning techniques? The root cause of these questions lies in the lack of a robust theoretical foundation for deep learning models in CV. To address these critical issues and techniques, we employ the Universal Approximation Theorem (UAT) to provide a theoretical basis for convolution- and Transformer-based models in CV. By doing so, we aim to elucidate these questions from a theoretical perspective.
Read more8/20/2024
0
Universal Approximation Theory: The basic theory for large language models
Wei Wang, Qing Li
Language models have emerged as a critical area of focus in artificial intelligence, particularly with the introduction of groundbreaking innovations like ChatGPT. Large-scale Transformer networks have quickly become the leading approach for advancing natural language processing algorithms. Built on the Transformer architecture, these models enable interactions that closely mimic human communication and, equipped with extensive knowledge, can even assist in guiding human tasks. Despite their impressive capabilities and growing complexity, a key question remains-the theoretical foundations of large language models (LLMs). What makes Transformer so effective for powering intelligent language applications, such as translation and coding? What underlies LLMs' ability for In-Context Learning (ICL)? How does the LoRA scheme enhance the fine-tuning of LLMs? And what supports the practicality of pruning LLMs? To address these critical questions and explore the technological strategies within LLMs, we leverage the Universal Approximation Theory (UAT) to offer a theoretical backdrop, shedding light on the mechanisms that underpin these advancements.
Read more8/20/2024

0
A Survey on Universal Approximation Theorems
Midhun T Augustine
This paper discusses various theorems on the approximation capabilities of neural networks (NNs), which are known as universal approximation theorems (UATs). The paper gives a systematic overview of UATs starting from the preliminary results on function approximation, such as Taylor's theorem, Fourier's theorem, Weierstrass approximation theorem, Kolmogorov - Arnold representation theorem, etc. Theoretical and numerical aspects of UATs are covered from both arbitrary width and depth.
Read more7/19/2024

0
Universal Approximation Theory: Foundations for Parallelism in Neural Networks
Wei Wang, Qing Li
Neural networks are increasingly evolving towards training large models with big data, a method that has demonstrated superior performance across many tasks. However, this approach introduces an urgent problem: current deep learning models are predominantly serial, meaning that as the number of network layers increases, so do the training and inference times. This is unacceptable if deep learning is to continue advancing. Therefore, this paper proposes a deep learning parallelization strategy based on the Universal Approximation Theorem (UAT). From this foundation, we designed a parallel network called Para-Former to test our theory. Unlike traditional serial models, the inference time of Para-Former does not increase with the number of layers, significantly accelerating the inference speed of multi-layer networks. Experimental results validate the effectiveness of this network.
Read more8/20/2024