Universal Knowledge Graph Embeddings

0
📉
Sign in to get full access
Overview
- Researchers have developed various knowledge graph embedding approaches, most of which learn the structure of a single knowledge graph for link prediction.
- However, this results in embeddings that are not aligned across different knowledge graphs, which limits their usefulness for applications like entity disambiguation that require a more global representation.
- This paper proposes learning universal knowledge graph embeddings from large-scale, interlinked knowledge sources to address this challenge.
Plain English Explanation
The paper discusses a new way to create embeddings, or numerical representations, of the entities and relationships in knowledge graphs. Knowledge graphs are databases that store information about the world in a structured way, with entities (like people, places, or things) and the connections between them.
Most current approaches to creating knowledge graph embeddings focus on learning the structure of a single knowledge graph, such as DBpedia or Wikidata. This means the resulting embeddings only reflect the information in that one knowledge graph, and embeddings for different knowledge graphs are not aligned - they can't be easily compared or used together.
However, many real-world applications, like disambiguating which entity a mention in text refers to, need a more global, universal representation of entities that works across multiple knowledge sources. To address this, the researchers propose fusing large knowledge graphs based on the "same as" (owl:sameAs) relationship, so that each entity has a unique identity represented across the combined graph.
They then compute universal embeddings based on this fused knowledge graph, covering around 180 million entities, 15,000 relations, and 1.2 billion facts. The researchers believe these universal embeddings will be valuable for the emerging field of graph foundation models, which aim to create general-purpose representations of knowledge graphs.
Technical Explanation
The key technical aspects of the paper are:
-
Knowledge Graph Fusion: The researchers combine multiple large knowledge graphs, like DBpedia and Wikidata, by aligning entities based on the
owl:sameAsrelation. This results in a unified knowledge graph representation with unique entity identities. -
Universal Embedding Computation: Using the fused knowledge graph, the researchers compute universal embeddings that represent the entities and relations. This covers approximately 180 million entities, 15,000 relations, and 1.2 billion triples.
-
Evaluation on Link Prediction: The paper evaluates the universal embeddings on the task of link prediction, where the goal is to predict missing connections in the knowledge graph. The results suggest the universal embeddings encode better semantics compared to embeddings learned from a single knowledge graph.
-
Open-Source Release: For reproducibility, the researchers provide the source code and datasets used in the study as open-access resources.
Critical Analysis
The paper makes a compelling case for the need and value of universal knowledge graph embeddings that can work across multiple knowledge sources. However, some potential limitations and areas for further research include:
-
Scalability and Generalization: While the current approach covers a large number of entities, it may be challenging to scale to the full breadth of available knowledge graphs on the web. Further research is needed to ensure the universal embeddings generalize well to new, unseen knowledge.
-
Alignment Quality: The quality of the universal embeddings depends on the accuracy of the
owl:sameAsalignments between the original knowledge graphs. Errors or inconsistencies in these alignments could introduce noise or bias into the final embeddings. -
Downstream Application Performance: While the paper evaluates the embeddings on link prediction, more research is needed to understand how they perform on other important tasks, such as entity disambiguation, question answering, or knowledge-powered decision making.
-
Interpretability and Explainability: As with many embedding-based approaches, it may be difficult to interpret the meaning and reasoning behind the universal embeddings. Techniques to improve the interpretability of these representations could enhance their usability and trust.
Despite these potential limitations, the paper makes an important contribution towards the goal of creating more globally applicable knowledge representations, which could have significant implications for a wide range of knowledge-powered applications.
Conclusion
This paper proposes a novel approach to learning universal knowledge graph embeddings that can represent entities and relationships across multiple large-scale knowledge sources. By fusing knowledge graphs and computing unified embeddings, the researchers aim to create representations that are more globally applicable, supporting emerging applications that require a more general understanding of world knowledge.
The technical evaluation suggests these universal embeddings encode better semantics than those learned from a single knowledge graph, and the researchers provide the source code and datasets as open-access resources. While there are some potential limitations and areas for further research, this work represents an important step towards richer, more interoperable knowledge representations that can power the next generation of knowledge-driven AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Universal Knowledge Graph Embeddings
N'Dah Jean Kouagou, Caglar Demir, Hamada M. Zahera, Adrian Wilke, Stefan Heindorf, Jiayi Li, Axel-Cyrille Ngonga Ngomo
A variety of knowledge graph embedding approaches have been developed. Most of them obtain embeddings by learning the structure of the knowledge graph within a link prediction setting. As a result, the embeddings reflect only the structure of a single knowledge graph, and embeddings for different knowledge graphs are not aligned, e.g., they cannot be used to find similar entities across knowledge graphs via nearest neighbor search. However, knowledge graph embedding applications such as entity disambiguation require a more global representation, i.e., a representation that is valid across multiple sources. We propose to learn universal knowledge graph embeddings from large-scale interlinked knowledge sources. To this end, we fuse large knowledge graphs based on the owl:sameAs relation such that every entity is represented by a unique identity. We instantiate our idea by computing universal embeddings based on DBpedia and Wikidata yielding embeddings for about 180 million entities, 15 thousand relations, and 1.2 billion triples. We believe our computed embeddings will support the emerging field of graph foundation models. Moreover, we develop a convenient API to provide embeddings as a service. Experiments on link prediction suggest that universal knowledge graph embeddings encode better semantics compared to embeddings computed on a single knowledge graph. For reproducibility purposes, we provide our source code and datasets open access.
Read more7/8/2024
0
Survey on Embedding Models for Knowledge Graph and its Applications
Manita Pote
Knowledge Graph (KG) is a graph based data structure to represent facts of the world where nodes represent real world entities or abstract concept and edges represent relation between the entities. Graph as representation for knowledge has several drawbacks like data sparsity, computational complexity and manual feature engineering. Knowledge Graph embedding tackles the drawback by representing entities and relation in low dimensional vector space by capturing the semantic relation between them. There are different KG embedding models. Here, we discuss translation based and neural network based embedding models which differ based on semantic property, scoring function and architecture they use. Further, we discuss application of KG in some domains that use deep learning models and leverage social media data.
Read more4/16/2024
0
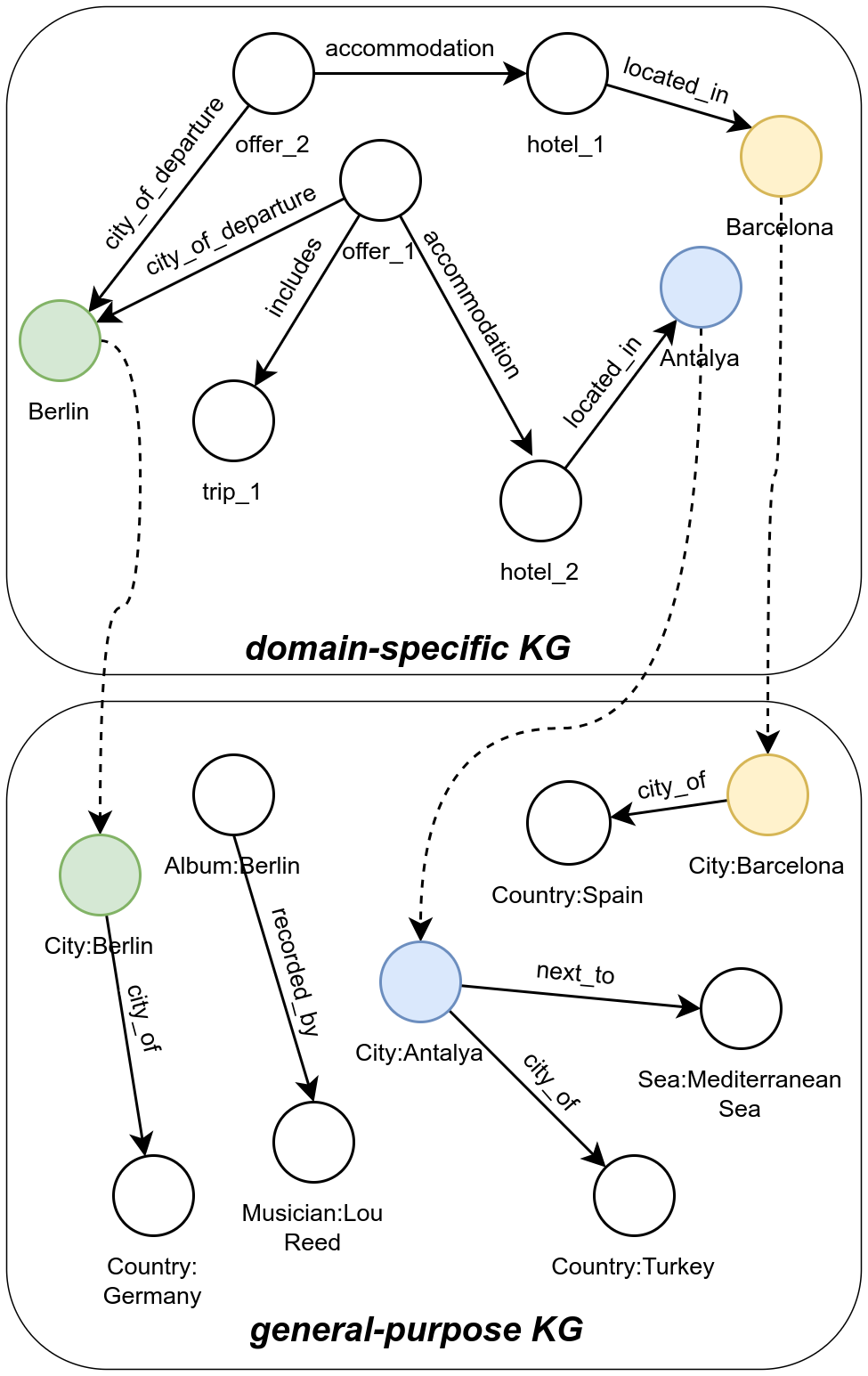
Empowering Small-Scale Knowledge Graphs: A Strategy of Leveraging General-Purpose Knowledge Graphs for Enriched Embeddings
Albert Sawczyn, Jakub Binkowski, Piotr Bielak, Tomasz Kajdanowicz
Knowledge-intensive tasks pose a significant challenge for Machine Learning (ML) techniques. Commonly adopted methods, such as Large Language Models (LLMs), often exhibit limitations when applied to such tasks. Nevertheless, there have been notable endeavours to mitigate these challenges, with a significant emphasis on augmenting LLMs through Knowledge Graphs (KGs). While KGs provide many advantages for representing knowledge, their development costs can deter extensive research and applications. Addressing this limitation, we introduce a framework for enriching embeddings of small-scale domain-specific Knowledge Graphs with well-established general-purpose KGs. Adopting our method, a modest domain-specific KG can benefit from a performance boost in downstream tasks when linked to a substantial general-purpose KG. Experimental evaluations demonstrate a notable enhancement, with up to a 44% increase observed in the Hits@10 metric. This relatively unexplored research direction can catalyze more frequent incorporation of KGs in knowledge-intensive tasks, resulting in more robust, reliable ML implementations, which hallucinates less than prevalent LLM solutions. Keywords: knowledge graph, knowledge graph completion, entity alignment, representation learning, machine learning
Read more5/20/2024

0
Improving rule mining via embedding-based link prediction
N'Dah Jean Kouagou, Arif Yilmaz, Michel Dumontier, Axel-Cyrille Ngonga Ngomo
Rule mining on knowledge graphs allows for explainable link prediction. Contrarily, embedding-based methods for link prediction are well known for their generalization capabilities, but their predictions are not interpretable. Several approaches combining the two families have been proposed in recent years. The majority of the resulting hybrid approaches are usually trained within a unified learning framework, which often leads to convergence issues due to the complexity of the learning task. In this work, we propose a new way to combine the two families of approaches. Specifically, we enrich a given knowledge graph by means of its pre-trained entity and relation embeddings before applying rule mining systems on the enriched knowledge graph. To validate our approach, we conduct extensive experiments on seven benchmark datasets. An analysis of the results generated by our approach suggests that we discover new valuable rules on the enriched graphs. We provide an open source implementation of our approach as well as pretrained models and datasets at https://github.com/Jean-KOUAGOU/EnhancedRuleLearning
Read more6/17/2024