Universal Sound Separation with Self-Supervised Audio Masked Autoencoder

0

Sign in to get full access
Overview
- Introduces a new self-supervised audio masked autoencoder (SSAMA) model for universal sound separation
- Leverages pre-trained models and self-supervised learning to enable separation of diverse audio signals without task-specific training
- Demonstrates strong performance on a range of audio separation tasks, including music, speech, and environmental sounds
Plain English Explanation
The paper presents a new deep learning model called a self-supervised audio masked autoencoder (SSAMA) that can separate diverse audio signals into their individual components. This is an important task in areas like music production, speech recognition, and environmental monitoring, where you often need to isolate specific sounds from a mix.
Typically, models for audio separation require extensive training on large annotated datasets for each specific task, which can be time-consuming and expensive to collect. The key innovation of SSAMA is that it can perform universal sound separation - separating audio into its constituent parts - without needing task-specific training data. Instead, it leverages self-supervised learning techniques to learn powerful audio representations from unlabeled data.
The model works by taking a mixed audio signal, randomly masking out parts of it, and then training the model to reconstruct the original unmasked audio. This teaches the model to learn useful features for separating sounds, even without being told what the individual sources are. The authors show that a model trained this way can then be applied to separate a wide variety of audio signals, from musical instruments to speech to environmental sounds, achieving strong performance on par with or exceeding task-specific models.
This universal sound separation capability could have many practical applications, such as improving audio quality in virtual meetings, enhancing music production workflows, or monitoring urban soundscapes. By reducing the need for labeled training data, the SSAMA model makes high-quality audio separation more accessible and scalable.
Technical Explanation
The core of the SSAMA model is a transformer-based audio encoder-decoder architecture that is trained in a self-supervised manner on unlabeled audio data. The key technical components are:
-
Audio Masking: During training, the input audio is randomly masked, with some percentage of the time-frequency bins being set to zero. This forces the model to learn robust audio representations that can fill in the missing parts.
-
Reconstruction Objective: The model is trained to reconstruct the original unmasked audio from the partially masked input. This self-supervised "audio inpainting" task teaches the model to disentangle and represent the underlying sound sources.
-
Transfer to Separation Tasks: Once pre-trained on the self-supervised task, the SSAMA model can be fine-tuned or directly applied to a wide range of audio separation problems, including music, speech, and environmental sound separation. The authors show it matches or outperforms task-specific models on these benchmarks.
-
Leveraging Pre-Trained Models: The SSAMA model builds on top of existing self-supervised audio models like MAE-Duo and EncodeC-MAE, inheriting their strong audio representations. This allows SSAMA to achieve high performance without requiring enormous training datasets.
Through extensive experiments, the authors demonstrate the versatility and effectiveness of the SSAMA approach for universal sound separation. They analyze the model's performance, robustness, and transfer capabilities, providing insights into how self-supervised pretraining enables this powerful audio understanding.
Critical Analysis
The SSAMA model represents an impressive advance in the field of audio separation, showing how self-supervised learning can enable high-performing, task-agnostic models. Some potential caveats and areas for future research include:
- The paper focuses on evaluating SSAMA on standard, curated benchmarks. Its performance on real-world, noisy audio signals with complex mixtures is still an open question that requires further investigation.
- While the self-supervised pretraining approach reduces the need for labeled data, the model still requires a significant amount of unlabeled audio data for pretraining. Developing more sample-efficient pretraining techniques could further improve accessibility.
- The authors note that SSAMA, like other transformer-based models, has high computational and memory requirements. Exploring ways to reduce the model's footprint without sacrificing performance could broaden its deployment, especially on edge devices.
- An interesting direction for future work would be to investigate ways to make the SSAMA model more interpretable, providing insight into how it is able to disentangle and separate the underlying sound sources.
Overall, the SSAMA model is a compelling step towards truly universal audio understanding and separation capabilities. By leveraging self-supervised learning, it opens up new possibilities for practical applications that require robust, flexible audio processing.
Conclusion
The "Universal Sound Separation with Self-Supervised Audio Masked Autoencoder" paper presents a novel deep learning model that can separate diverse audio signals into their individual components without the need for task-specific training data. By leveraging self-supervised learning techniques, the SSAMA model is able to learn powerful audio representations that enable it to perform high-quality separation on a wide range of audio sources, including music, speech, and environmental sounds.
This universal sound separation capability has many potential applications, from enhancing virtual meeting experiences to improving music production workflows to enabling more advanced urban soundscape monitoring. By reducing the reliance on labeled training data, the SSAMA approach makes audio separation more accessible and scalable, with the potential to drive progress in a variety of audio-centric domains.
While the paper demonstrates the strong performance of SSAMA on standard benchmarks, there are still opportunities to further improve the model's robustness, efficiency, and interpretability. Nonetheless, this work represents an important step towards more flexible and capable audio understanding systems that can be applied broadly without the need for extensive task-specific engineering.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Universal Sound Separation with Self-Supervised Audio Masked Autoencoder
Junqi Zhao, Xubo Liu, Jinzheng Zhao, Yi Yuan, Qiuqiang Kong, Mark D. Plumbley, Wenwu Wang
Universal sound separation (USS) is a task of separating mixtures of arbitrary sound sources. Typically, universal separation models are trained from scratch in a supervised manner, using labeled data. Self-supervised learning (SSL) is an emerging deep learning approach that leverages unlabeled data to obtain task-agnostic representations, which can benefit many downstream tasks. In this paper, we propose integrating a self-supervised pre-trained model, namely the audio masked autoencoder (A-MAE), into a universal sound separation system to enhance its separation performance. We employ two strategies to utilize SSL embeddings: freezing or updating the parameters of A-MAE during fine-tuning. The SSL embeddings are concatenated with the short-time Fourier transform (STFT) to serve as input features for the separation model. We evaluate our methods on the AudioSet dataset, and the experimental results indicate that the proposed methods successfully enhance the separation performance of a state-of-the-art ResUNet-based USS model.
Read more7/17/2024

0
Leveraging Self-supervised Audio Representations for Data-Efficient Acoustic Scene Classification
Yiqiang Cai, Shengchen Li, Xi Shao
Acoustic scene classification (ASC) predominantly relies on supervised approaches. However, acquiring labeled data for training ASC models is often costly and time-consuming. Recently, self-supervised learning (SSL) has emerged as a powerful method for extracting features from unlabeled audio data, benefiting many downstream audio tasks. This paper proposes a data-efficient and low-complexity ASC system by leveraging self-supervised audio representations extracted from general-purpose audio datasets. We introduce BEATs, an audio SSL pre-trained model, to extract the general representations from AudioSet. Through extensive experiments, it has been demonstrated that the self-supervised audio representations can help to achieve high ASC accuracy with limited labeled fine-tuning data. Furthermore, we find that ensembling the SSL models fine-tuned with different strategies contributes to a further performance improvement. To meet low-complexity requirements, we use knowledge distillation to transfer the self-supervised knowledge from large teacher models to an efficient student model. The experimental results suggest that the self-supervised teachers effectively improve the classification accuracy of the student model. Our best-performing system obtains an average accuracy of 56.7%.
Read more8/28/2024
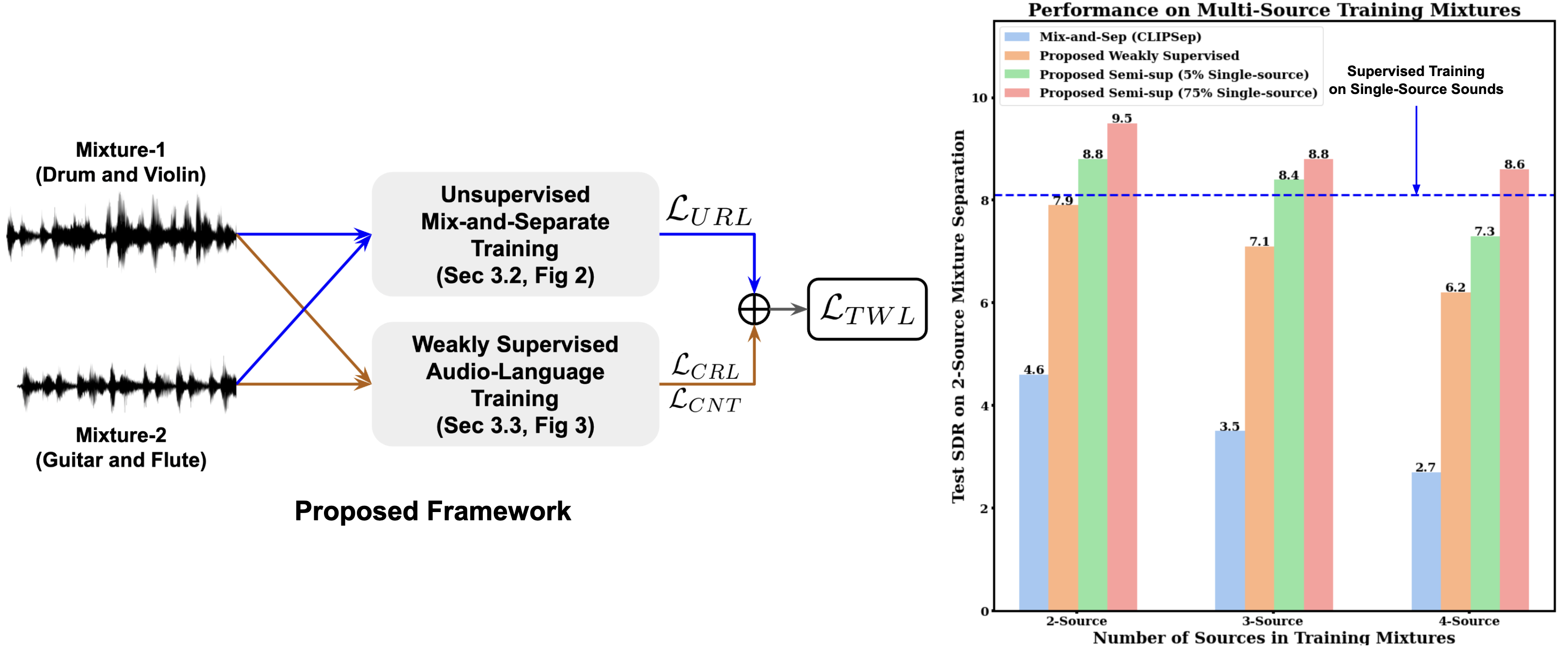
0
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Read more4/3/2024

0
Towards Audio Codec-based Speech Separation
Jia Qi Yip, Shengkui Zhao, Dianwen Ng, Eng Siong Chng, Bin Ma
Recent improvements in neural audio codec (NAC) models have generated interest in adopting pre-trained codecs for a variety of speech processing applications to take advantage of the efficiencies gained from high compression, but these have yet been applied to the speech separation (SS) task. SS can benefit from high compression because the compute required for traditional SS models makes them impractical for many edge computing use cases. However, SS is a waveform-masking task where compression tends to introduce distortions that severely impact performance. Here we propose a novel task of Audio Codec-based SS, where SS is performed within the embedding space of a NAC, and propose a new model, Codecformer, to address this task. At inference, Codecformer achieves a 52x reduction in MAC while producing separation performance comparable to a cloud deployment of Sepformer. This method charts a new direction for performing efficient SS in practical scenarios.
Read more7/8/2024