Leveraging Self-supervised Audio Representations for Data-Efficient Acoustic Scene Classification

0

Sign in to get full access
Overview
- The paper explores how self-supervised audio representations can be leveraged for data-efficient acoustic scene classification.
- Self-supervised learning is used to pre-train audio models on large unlabeled datasets, which can then be fine-tuned on smaller labeled datasets for specific tasks.
- The researchers investigate the effectiveness of this approach for acoustic scene classification, a common audio processing task.
Plain English Explanation
Self-supervised learning is a technique where an AI model is first trained on a large amount of unlabeled data to learn general patterns and representations. This pre-training can help the model learn useful features and knowledge that can then be leveraged for specific tasks. The paper looks at how this approach can be applied to acoustic scene classification, which involves identifying the environment or "scene" a sound is coming from, such as an office, a park, or a busy street.
By first pre-training the model on a large amount of unlabeled audio data, the researchers aim to build representations that capture the general characteristics of different sounds. This pre-trained model can then be "fine-tuned" on a smaller labeled dataset for the specific task of acoustic scene classification. The hope is that this data-efficient approach can achieve strong performance even when limited labeled data is available for the target task.
Technical Explanation
The paper begins by discussing the potential benefits of leveraging self-supervised pre-training for acoustic scene classification. The researchers argue that this can help overcome the challenge of needing large labeled datasets, which are often difficult and expensive to obtain for audio processing tasks.
They describe their self-supervised pre-training approach, which involves training an audio encoder model on a large unlabeled audio dataset using a contrastive learning objective. This encourages the model to learn representations that capture the general structure and properties of different sounds. The pre-trained encoder is then fine-tuned on a smaller labeled dataset for the acoustic scene classification task.
The paper presents experiments evaluating this approach on several benchmark datasets for acoustic scene classification. The results show that the self-supervised pre-training can indeed provide significant performance gains, especially when the labeled dataset is small. The researchers also analyze the learned representations and provide insights into how the self-supervised pre-training enables the model to better capture the relevant features for the task.
Critical Analysis
The paper provides a thorough and well-designed study on leveraging self-supervised audio representations for data-efficient acoustic scene classification. The researchers carefully consider the experimental setup, including the choice of pre-training dataset, fine-tuning procedure, and evaluation on multiple benchmark datasets.
One potential limitation is that the paper focuses on a specific type of self-supervised pre-training using contrastive learning. There may be other self-supervised techniques, such as masked audio modeling, that could also be effective and worth exploring. Additionally, the paper does not delve into the computational and resource requirements of the self-supervised pre-training, which could be an important consideration for real-world applications.
Overall, the paper makes a compelling case for the benefits of self-supervised learning in the context of audio processing tasks like acoustic scene classification. The findings suggest that this approach can be a powerful tool for improving data efficiency and performance, especially in scenarios with limited labeled data available.
Conclusion
This paper demonstrates the potential of leveraging self-supervised audio representations to enable data-efficient acoustic scene classification. By first pre-training an audio encoder model on large unlabeled datasets, the researchers show that the resulting representations can be effectively fine-tuned on smaller labeled datasets to achieve strong performance.
The findings of this study have important implications for audio processing applications where labeled data is scarce or difficult to obtain. The self-supervised pre-training approach could help expand the reach and applicability of acoustic scene classification and other audio-based technologies. This research also highlights the broader value of self-supervised learning in advancing the field of machine learning and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Self-supervised Audio Representations for Data-Efficient Acoustic Scene Classification
Yiqiang Cai, Shengchen Li, Xi Shao
Acoustic scene classification (ASC) predominantly relies on supervised approaches. However, acquiring labeled data for training ASC models is often costly and time-consuming. Recently, self-supervised learning (SSL) has emerged as a powerful method for extracting features from unlabeled audio data, benefiting many downstream audio tasks. This paper proposes a data-efficient and low-complexity ASC system by leveraging self-supervised audio representations extracted from general-purpose audio datasets. We introduce BEATs, an audio SSL pre-trained model, to extract the general representations from AudioSet. Through extensive experiments, it has been demonstrated that the self-supervised audio representations can help to achieve high ASC accuracy with limited labeled fine-tuning data. Furthermore, we find that ensembling the SSL models fine-tuned with different strategies contributes to a further performance improvement. To meet low-complexity requirements, we use knowledge distillation to transfer the self-supervised knowledge from large teacher models to an efficient student model. The experimental results suggest that the self-supervised teachers effectively improve the classification accuracy of the student model. Our best-performing system obtains an average accuracy of 56.7%.
Read more8/28/2024
🏷️
0
New!Self-supervised Learning for Acoustic Few-Shot Classification
Jingyong Liang, Bernd Meyer, Issac Ning Lee, Thanh-Toan Do
Labelled data are limited and self-supervised learning is one of the most important approaches for reducing labelling requirements. While it has been extensively explored in the image domain, it has so far not received the same amount of attention in the acoustic domain. Yet, reducing labelling is a key requirement for many acoustic applications. Specifically in bioacoustic, there are rarely sufficient labels for fully supervised learning available. This has led to the widespread use of acoustic recognisers that have been pre-trained on unrelated data for bioacoustic tasks. We posit that training on the actual task data and combining self-supervised pre-training with few-shot classification is a superior approach that has the ability to deliver high accuracy even when only a few labels are available. To this end, we introduce and evaluate a new architecture that combines CNN-based preprocessing with feature extraction based on state space models (SSMs). This combination is motivated by the fact that CNN-based networks alone struggle to capture temporal information effectively, which is crucial for classifying acoustic signals. SSMs, specifically S4 and Mamba, on the other hand, have been shown to have an excellent ability to capture long-range dependencies in sequence data. We pre-train this architecture using contrastive learning on the actual task data and subsequent fine-tuning with an extremely small amount of labelled data. We evaluate the performance of this proposed architecture for ($n$-shot, $n$-class) classification on standard benchmarks as well as real-world data. Our evaluation shows that it outperforms state-of-the-art architectures on the few-shot classification problem.
Read more9/17/2024
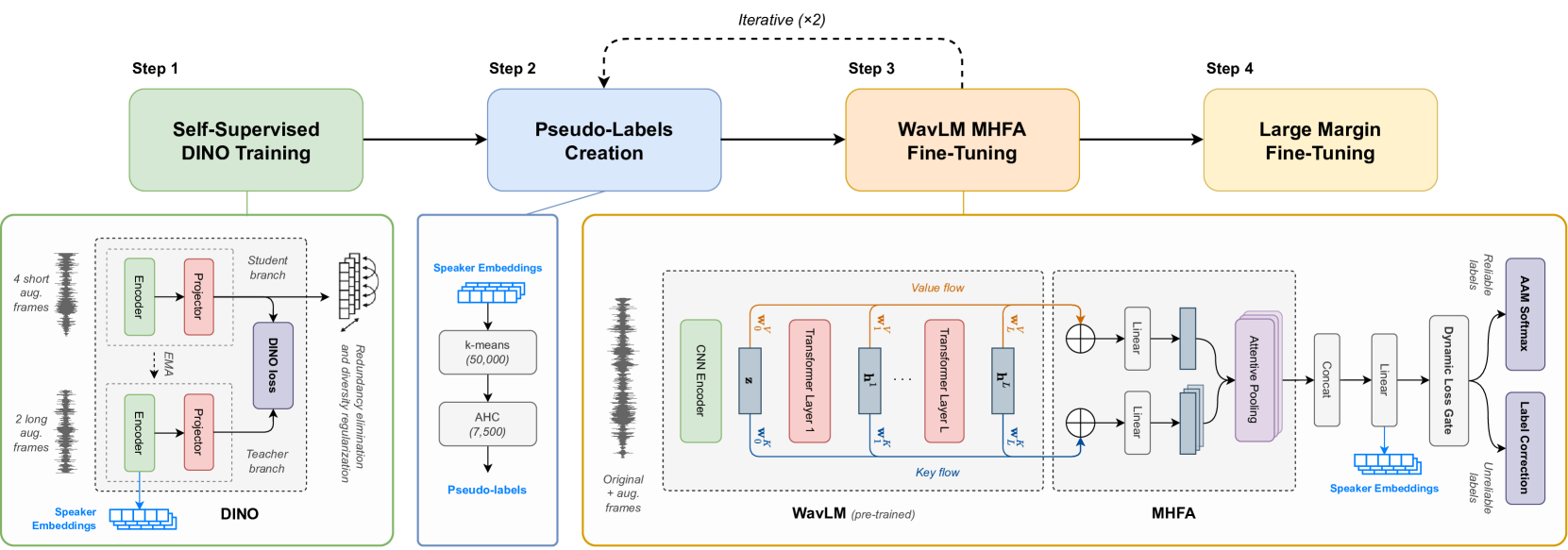
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more9/17/2024

0
Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Read more6/13/2024