Ranking LLMs by compression
2406.14171
0
0
🏷️
Abstract
We conceptualize the process of understanding as information compression, and propose a method for ranking large language models (LLMs) based on lossless data compression. We demonstrate the equivalence of compression length under arithmetic coding with cumulative negative log probabilities when using a large language model as a prior, that is, the pre-training phase of the model is essentially the process of learning the optimal coding length. At the same time, the evaluation metric compression ratio can be obtained without actual compression, which greatly saves overhead. In this paper, we use five large language models as priors for compression, then compare their performance on challenging natural language processing tasks, including sentence completion, question answering, and coreference resolution. Experimental results show that compression ratio and model performance are positively correlated, so it can be used as a general metric to evaluate large language models.
Create account to get full access
Overview
- The research paper discusses a novel approach to ranking and evaluating large language models (LLMs) based on their compression capabilities.
- The authors propose using compression as a proxy for measuring the intelligence and capabilities of LLMs, as models that can effectively compress information are likely to be more capable at understanding and reasoning about the world.
- The paper presents several experiments and analyses to support the idea that compression represents a useful and informative metric for LLM evaluation.
Plain English Explanation
The paper is trying to find a better way to measure how capable and intelligent large language models (LLMs) are. Current methods of evaluating LLMs often focus on their performance on specific tasks, but the authors argue that this doesn't fully capture the models' underlying abilities. Instead, they suggest looking at how well the models can compress information.
The idea is that more intelligent models should be able to take complex information and compress it down into a smaller, more efficient representation. This compression ability is a sign that the model has really understood the content and can represent it in a more compact way. So the researchers investigate using compression as a proxy for measuring the overall capabilities of different LLMs.
They run a series of experiments to test this idea, looking at how well various LLMs can compress different types of text data. The results suggest that compression is indeed a useful and insightful metric for evaluating LLMs, providing a window into the models' reasoning and language understanding abilities in a way that task-specific benchmarks may miss.
Technical Explanation
The paper proposes using compression represents intelligence linearly as a new approach for evaluating and ranking large language models (LLMs). The authors hypothesize that an LLM's ability to compress information is a proxy for its underlying intelligence and capabilities.
To test this, the researchers conduct several experiments. First, they quantify the multilingual performance of large language models across a diverse set of tasks and evaluate how the models' compression abilities relate to their task-specific performance.
Next, they investigate feature-based low-rank compression of large language models to understand how model compression impacts performance. Finally, they explore training LLMs over neurally compressed text to see if models can learn more efficiently from compressed data.
The results indicate that compression is a meaningful and informative metric for evaluating LLMs, as models that can more effectively compress information also tend to perform better on a range of language understanding tasks. The authors also find that compressed models can maintain strong performance while being more efficient and compact.
Critical Analysis
The paper presents a compelling argument for using compression as a valuable tool in evaluating and comparing large language models. The authors make a strong case that compression ability is a meaningful proxy for a model's underlying intelligence and language understanding capabilities.
However, the research does have some limitations. The experiments are largely focused on text-based compression and tasks, so it's unclear how well the compression-based evaluation would extend to more diverse, multimodal language models. Additionally, the paper does not fully address potential biases or other issues that could arise from relying too heavily on compression as the sole metric for LLM assessment.
Further research is needed to better understand the nuances and tradeoffs of using compression as an LLM evaluation method. For example, it would be interesting to explore how compression-based evaluation compares to or complements existing task-based benchmarks, and whether there are certain types of language tasks or models where compression is particularly insightful versus less useful.
Overall, the paper presents a thought-provoking and potentially impactful approach to LLM evaluation. While more work is needed, the idea of using compression as a proxy for intelligence is an intriguing one that could help drive the development of more capable and efficient language models.
Conclusion
The research paper introduces a novel approach for evaluating and ranking large language models based on their compression capabilities. The key idea is that a model's ability to effectively compress information is a meaningful proxy for its underlying intelligence and language understanding abilities.
Through a series of experiments, the authors demonstrate that compression is a useful and insightful metric for assessing LLMs, providing complementary insights to traditional task-based benchmarks. The findings suggest that models that can compress information more efficiently also tend to perform better on a range of language understanding tasks.
This compression-based evaluation method has the potential to become a valuable tool for researchers and developers working on advancing the state of the art in large language models. By focusing on compression as a proxy for intelligence, the approach may help drive the creation of more capable, efficient, and generally useful language models that can better understand and reason about the world.
While more research is needed to fully understand the nuances and limitations of this approach, the paper presents an exciting new direction for LLM evaluation that could have significant implications for the field of natural language processing and artificial intelligence as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
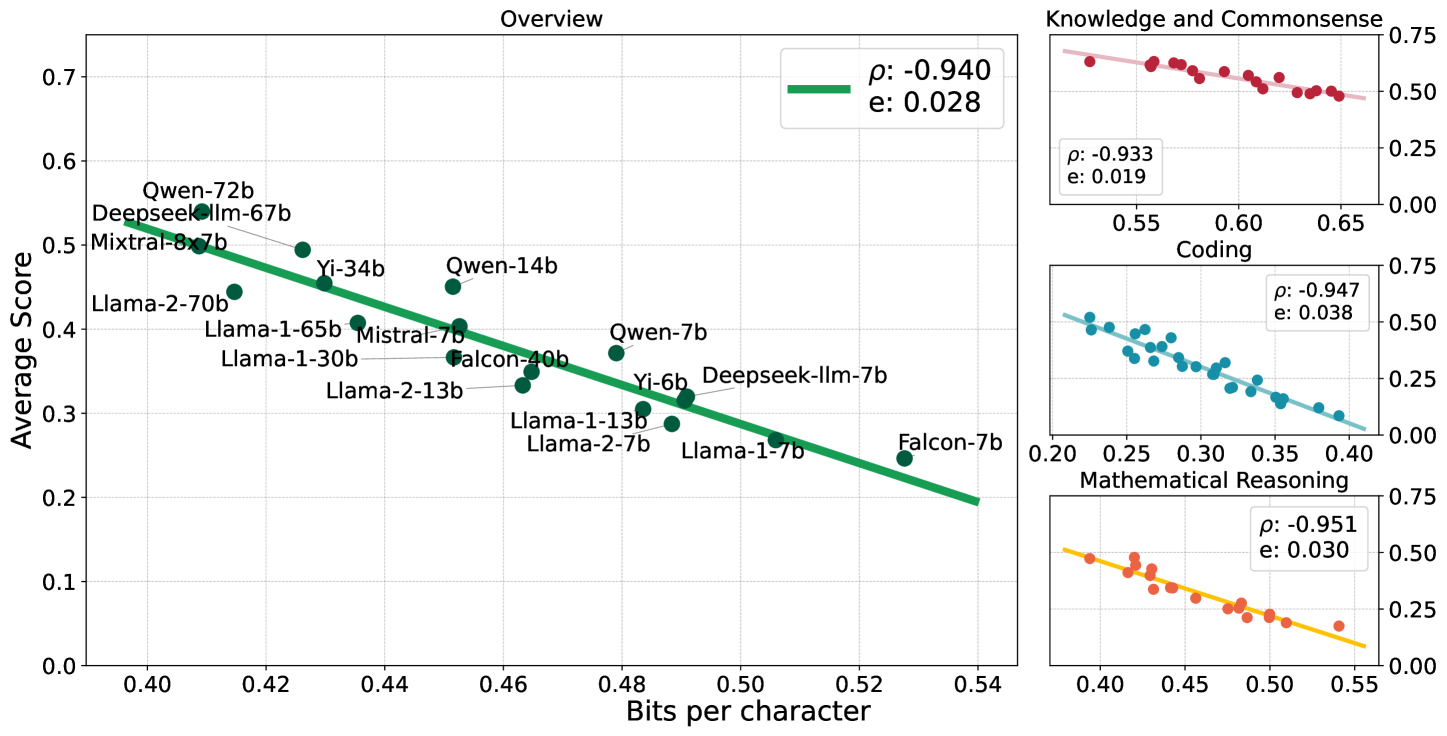
Compression Represents Intelligence Linearly
Yuzhen Huang, Jinghan Zhang, Zifei Shan, Junxian He
0
0
There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors. Given the abstract concept of intelligence, we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning. Across 12 benchmarks, our study brings together 30 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs' intelligence -- reflected by average benchmark scores -- almost linearly correlates with their ability to compress external text corpora. These results provide concrete evidence supporting the belief that superior compression indicates greater intelligence. Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
4/16/2024
Quantifying Multilingual Performance of Large Language Models Across Languages
Zihao Li, Yucheng Shi, Zirui Liu, Fan Yang, Ali Payani, Ninghao Liu, Mengnan Du
0
0
The development of Large Language Models (LLMs) relies on extensive text corpora, which are often unevenly distributed across languages. This imbalance results in LLMs performing significantly better on high-resource languages like English, German, and French, while their capabilities in low-resource languages remain inadequate. Currently, there is a lack of quantitative methods to evaluate the performance of LLMs in these low-resource languages. To address this gap, we propose the Language Ranker, an intrinsic metric designed to benchmark and rank languages based on LLM performance using internal representations. By comparing the LLM's internal representation of various languages against a baseline derived from English, we can assess the model's multilingual capabilities in a robust and language-agnostic manner. Our analysis reveals that high-resource languages exhibit higher similarity scores with English, demonstrating superior performance, while low-resource languages show lower similarity scores, underscoring the effectiveness of our metric in assessing language-specific capabilities. Besides, the experiments show that there is a strong correlation between the LLM's performance in different languages and the proportion of those languages in its pre-training corpus. These insights underscore the efficacy of the Language Ranker as a tool for evaluating LLM performance across different languages, particularly those with limited resources.
6/18/2024
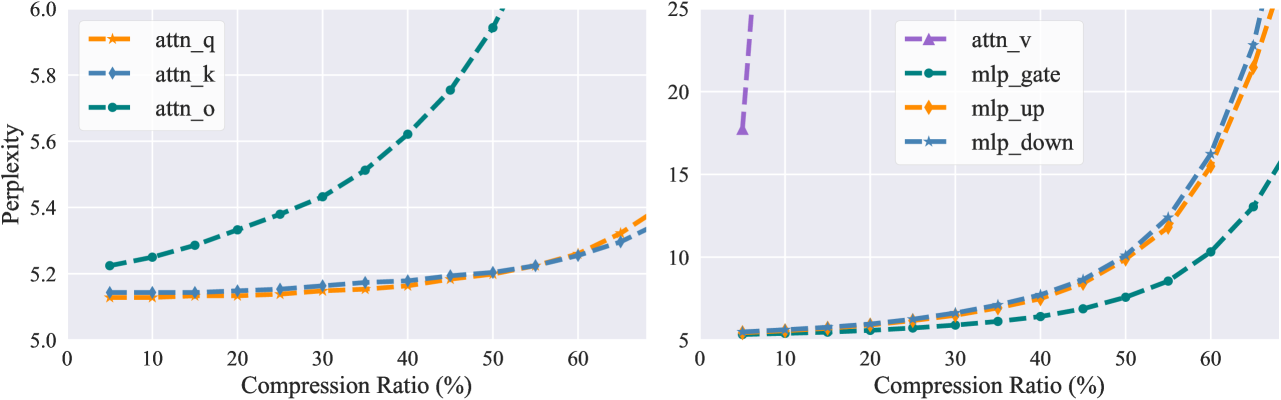
Feature-based Low-Rank Compression of Large Language Models via Bayesian Optimization
Yixin Ji, Yang Xiang, Juntao Li, Wei Chen, Zhongyi Liu, Kehai Chen, Min Zhang
0
0
In recent years, large language models (LLMs) have driven advances in natural language processing. Still, their growing scale has increased the computational burden, necessitating a balance between efficiency and performance. Low-rank compression, a promising technique, reduces non-essential parameters by decomposing weight matrices into products of two low-rank matrices. Yet, its application in LLMs has not been extensively studied. The key to low-rank compression lies in low-rank factorization and low-rank dimensions allocation. To address the challenges of low-rank compression in LLMs, we conduct empirical research on the low-rank characteristics of large models. We propose a low-rank compression method suitable for LLMs. This approach involves precise estimation of feature distributions through pooled covariance matrices and a Bayesian optimization strategy for allocating low-rank dimensions. Experiments on the LLaMA-2 models demonstrate that our method outperforms existing strong structured pruning and low-rank compression techniques in maintaining model performance at the same compression ratio.
5/20/2024

Evaluating Zero-Shot Long-Context LLM Compression
Chenyu Wang, Yihan Wang
0
0
This study evaluates the effectiveness of zero-shot compression techniques on large language models (LLMs) under long-context. We identify the tendency for computational errors to increase under long-context when employing certain compression methods. We propose a hypothesis to explain the varied behavior of different LLM compression techniques and explore remedies to mitigate the performance decline observed in some techniques under long-context. This is a course report for COS 598D Machine Learning and Systems by Prof. Kai Li at Princeton University. Due to limited computational resources, our experiments were conducted only on LLaMA-2-7B-32K.
6/12/2024