Unraveling Batch Normalization for Realistic Test-Time Adaptation

0

Sign in to get full access
Overview
- This paper explores the effect of batch normalization on test-time adaptation, a technique used to improve model performance on new, unseen data.
- The authors investigate how batch normalization, a common technique used in deep learning models, behaves during test-time adaptation and propose solutions to improve its effectiveness.
- The paper provides insights into the challenges of using batch normalization in realistic test-time adaptation scenarios and offers strategies to address these challenges.
Plain English Explanation
Deep learning models are often trained on a large dataset, but when deployed in the real world, they may encounter new data that is different from the training data. Test-time adaptation is a technique used to adjust the model's behavior to better handle this new data.
One key component of many deep learning models is batch normalization, which helps stabilize the training process and improve model performance. However, batch normalization can pose challenges during test-time adaptation, as it relies on statistics computed from the training data.
This paper examines how batch normalization affects test-time adaptation and proposes solutions to address the issues that arise. The authors explore different approaches to adapt the batch normalization layers in the model to the new test-time data, without relying solely on the limited information available during a single test-time pass.
By understanding the interplay between batch normalization and test-time adaptation, the researchers aim to help developers build more robust and adaptable deep learning models that can perform well in a variety of real-world scenarios.
Technical Explanation
The paper begins by reviewing the related work on test-time adaptation, including techniques like entropy minimization, layerwise early stopping, and active adaptation. It then delves into the specific challenges posed by batch normalization during test-time adaptation.
The authors explain that batch normalization relies on computing statistics (mean and variance) from the current batch of data, which can be problematic when only a single test-time example is available. They propose several strategies to address this issue, including using a unified entropy optimization approach and adapting the batch normalization parameters in a layer-wise manner.
Through extensive experiments on various datasets and tasks, the researchers demonstrate the effectiveness of their proposed solutions. They show that their methods can significantly improve the performance of deep learning models during test-time adaptation, particularly in cases where the test-time data differs significantly from the training data.
Critical Analysis
The paper provides a thorough analysis of the impact of batch normalization on test-time adaptation and presents promising solutions to address the identified challenges. However, the authors acknowledge that their work is primarily focused on controlled experimental settings and may not fully capture the complexities of real-world deployment scenarios.
One potential limitation is the assumption that the test-time data is drawn from a related, but distinct, distribution compared to the training data. In practice, the test-time data may exhibit more drastic shifts, such as completely different domains or tasks, which could require additional techniques beyond what is described in the paper.
Additionally, the paper does not explore the computational and memory overhead of the proposed solutions, which could be an important consideration for practical deployments, especially on resource-constrained devices.
Further research could investigate the generalization of the proposed methods to a wider range of test-time adaptation scenarios, including more extreme domain shifts, and explore the trade-offs between performance gains and computational/memory requirements.
Conclusion
This paper offers valuable insights into the interplay between batch normalization and test-time adaptation, a critical challenge in deploying deep learning models in real-world settings. By proposing solutions to address the limitations of batch normalization during test-time adaptation, the authors contribute to the growing body of research aimed at building more robust and adaptable deep learning systems.
The findings presented in this work have the potential to inform the development of more reliable and versatile deep learning models, which could have far-reaching implications for a wide range of applications, from image recognition to natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unraveling Batch Normalization for Realistic Test-Time Adaptation
Zixian Su, Jingwei Guo, Kai Yao, Xi Yang, Qiufeng Wang, Kaizhu Huang
While recent test-time adaptations exhibit efficacy by adjusting batch normalization to narrow domain disparities, their effectiveness diminishes with realistic mini-batches due to inaccurate target estimation. As previous attempts merely introduce source statistics to mitigate this issue, the fundamental problem of inaccurate target estimation still persists, leaving the intrinsic test-time domain shifts unresolved. This paper delves into the problem of mini-batch degradation. By unraveling batch normalization, we discover that the inexact target statistics largely stem from the substantially reduced class diversity in batch. Drawing upon this insight, we introduce a straightforward tool, Test-time Exponential Moving Average (TEMA), to bridge the class diversity gap between training and testing batches. Importantly, our TEMA adaptively extends the scope of typical methods beyond the current batch to incorporate a diverse set of class information, which in turn boosts an accurate target estimation. Built upon this foundation, we further design a novel layer-wise rectification strategy to consistently promote test-time performance. Our proposed method enjoys a unique advantage as it requires neither training nor tuning parameters, offering a truly hassle-free solution. It significantly enhances model robustness against shifted domains and maintains resilience in diverse real-world scenarios with various batch sizes, achieving state-of-the-art performance on several major benchmarks. Code is available at url{https://github.com/kiwi12138/RealisticTTA}.
Read more4/16/2024
0
UniTTA: Unified Benchmark and Versatile Framework Towards Realistic Test-Time Adaptation
Chaoqun Du, Yulin Wang, Jiayi Guo, Yizeng Han, Jie Zhou, Gao Huang
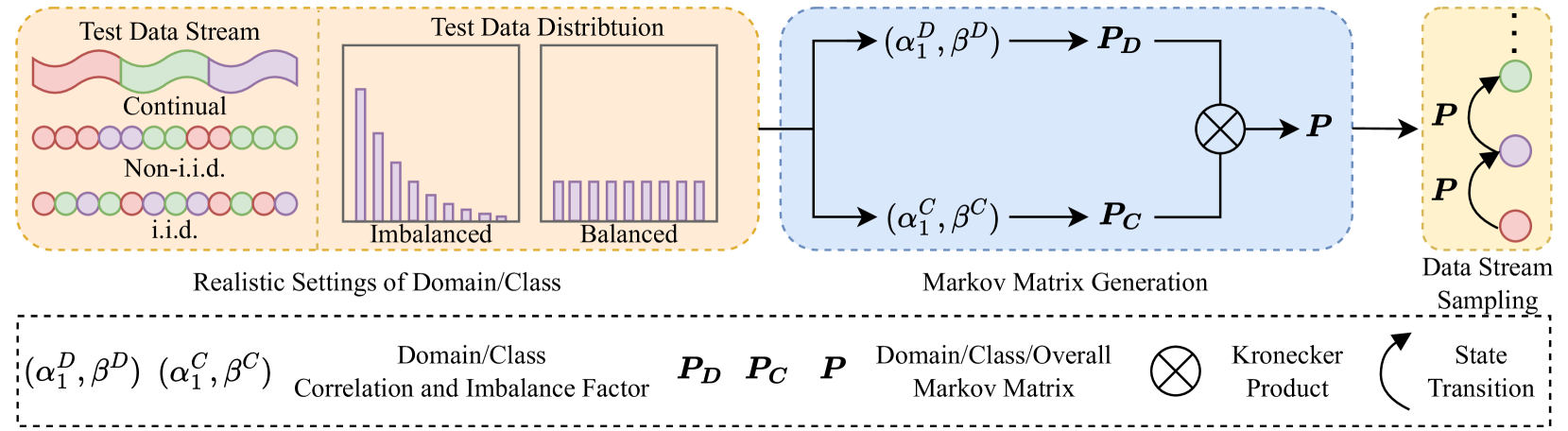
Test-Time Adaptation (TTA) aims to adapt pre-trained models to the target domain during testing. In reality, this adaptability can be influenced by multiple factors. Researchers have identified various challenging scenarios and developed diverse methods to address these challenges, such as dealing with continual domain shifts, mixed domains, and temporally correlated or imbalanced class distributions. Despite these efforts, a unified and comprehensive benchmark has yet to be established. To this end, we propose a Unified Test-Time Adaptation (UniTTA) benchmark, which is comprehensive and widely applicable. Each scenario within the benchmark is fully described by a Markov state transition matrix for sampling from the original dataset. The UniTTA benchmark considers both domain and class as two independent dimensions of data and addresses various combinations of imbalance/balance and i.i.d./non-i.i.d./continual conditions, covering a total of ( (2 times 3)^2 = 36 ) scenarios. It establishes a comprehensive evaluation benchmark for realistic TTA and provides a guideline for practitioners to select the most suitable TTA method. Alongside this benchmark, we propose a versatile UniTTA framework, which includes a Balanced Domain Normalization (BDN) layer and a COrrelated Feature Adaptation (COFA) method--designed to mitigate distribution gaps in domain and class, respectively. Extensive experiments demonstrate that our UniTTA framework excels within the UniTTA benchmark and achieves state-of-the-art performance on average. Our code is available at url{https://github.com/LeapLabTHU/UniTTA}.
Read more7/30/2024

0
Channel-Selective Normalization for Label-Shift Robust Test-Time Adaptation
Pedro Vianna, Muawiz Chaudhary, Paria Mehrbod, An Tang, Guy Cloutier, Guy Wolf, Michael Eickenberg, Eugene Belilovsky
Deep neural networks have useful applications in many different tasks, however their performance can be severely affected by changes in the data distribution. For example, in the biomedical field, their performance can be affected by changes in the data (different machines, populations) between training and test datasets. To ensure robustness and generalization to real-world scenarios, test-time adaptation has been recently studied as an approach to adjust models to a new data distribution during inference. Test-time batch normalization is a simple and popular method that achieved compelling performance on domain shift benchmarks. It is implemented by recalculating batch normalization statistics on test batches. Prior work has focused on analysis with test data that has the same label distribution as the training data. However, in many practical applications this technique is vulnerable to label distribution shifts, sometimes producing catastrophic failure. This presents a risk in applying test time adaptation methods in deployment. We propose to tackle this challenge by only selectively adapting channels in a deep network, minimizing drastic adaptation that is sensitive to label shifts. Our selection scheme is based on two principles that we empirically motivate: (1) later layers of networks are more sensitive to label shift (2) individual features can be sensitive to specific classes. We apply the proposed technique to three classification tasks, including CIFAR10-C, Imagenet-C, and diagnosis of fatty liver, where we explore both covariate and label distribution shifts. We find that our method allows to bring the benefits of TTA while significantly reducing the risk of failure common in other methods, while being robust to choice in hyperparameters.
Read more5/30/2024
🤯
0
Discover Your Neighbors: Advanced Stable Test-Time Adaptation in Dynamic World
Qinting Jiang, Chuyang Ye, Dongyan Wei, Yuan Xue, Jingyan Jiang, Zhi Wang
Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for multimedia applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. This work provides a new perspective on analyzing batch normalization techniques through class-related and class-irrelevant features, our observations reveal combining source and test batch normalization statistics robustly characterizes target distributions. However, test statistics must have high similarity. We thus propose Discover Your Neighbours (DYN), the first backward-free approach specialized for dynamic TTA. The core innovation is identifying similar samples via instance normalization statistics and clustering into groups which provides consistent class-irrelevant representations. Specifically, Our DYN consists of layer-wise instance statistics clustering (LISC) and cluster-aware batch normalization (CABN). In LISC, we perform layer-wise clustering of approximate feature samples at each BN layer by calculating the cosine similarity of instance normalization statistics across the batch. CABN then aggregates SBN and TCN statistics to collaboratively characterize the target distribution, enabling more robust representations. Experimental results validate DYN's robustness and effectiveness, demonstrating maintained performance under dynamic data stream patterns.
Read more6/11/2024