Layerwise Early Stopping for Test Time Adaptation

0

Sign in to get full access
Overview
- This research paper explores a technique called "Layerwise Early Stopping for Test Time Adaptation" (LESTA), which aims to improve the performance of machine learning models during the testing or deployment phase.
- The key idea is to adapt the model parameters at each layer independently, rather than adapting the entire model at once, and to stop the adaptation process early for each layer to avoid overfitting.
- This approach is designed to be more parameter-efficient than full model adaptation, and can potentially lead to better performance on target tasks or datasets.
Plain English Explanation
Layerwise Early Stopping for Test Time Adaptation is a technique that helps machine learning models perform better when they're being used in the real world, rather than just during the training process.
Normally, when a model is deployed, it's used to make predictions on new data that it hasn't seen before. But sometimes the new data can be quite different from the data the model was trained on, and the model's performance can suffer. That's where test time adaptation (TTA) comes in - it allows the model to "adapt" to the new data during the testing or deployment phase.
The key insight of this research is that, instead of adapting the entire model at once, we can adapt each individual layer of the model separately. And instead of letting the adaptation process run indefinitely, we can "stop" the adaptation early for each layer, to avoid the model becoming too specialized to the new data and losing its general capabilities.
By adapting the model in this layerwise and early-stopping fashion, the researchers found that they could achieve better performance on target tasks or datasets, while using fewer parameters than full model adaptation. This makes the approach more efficient and practical for real-world deployment of machine learning models.
Technical Explanation
Layerwise Early Stopping for Test Time Adaptation proposes a novel test time adaptation (TTA) technique that aims to improve model performance while being more parameter-efficient than full model adaptation.
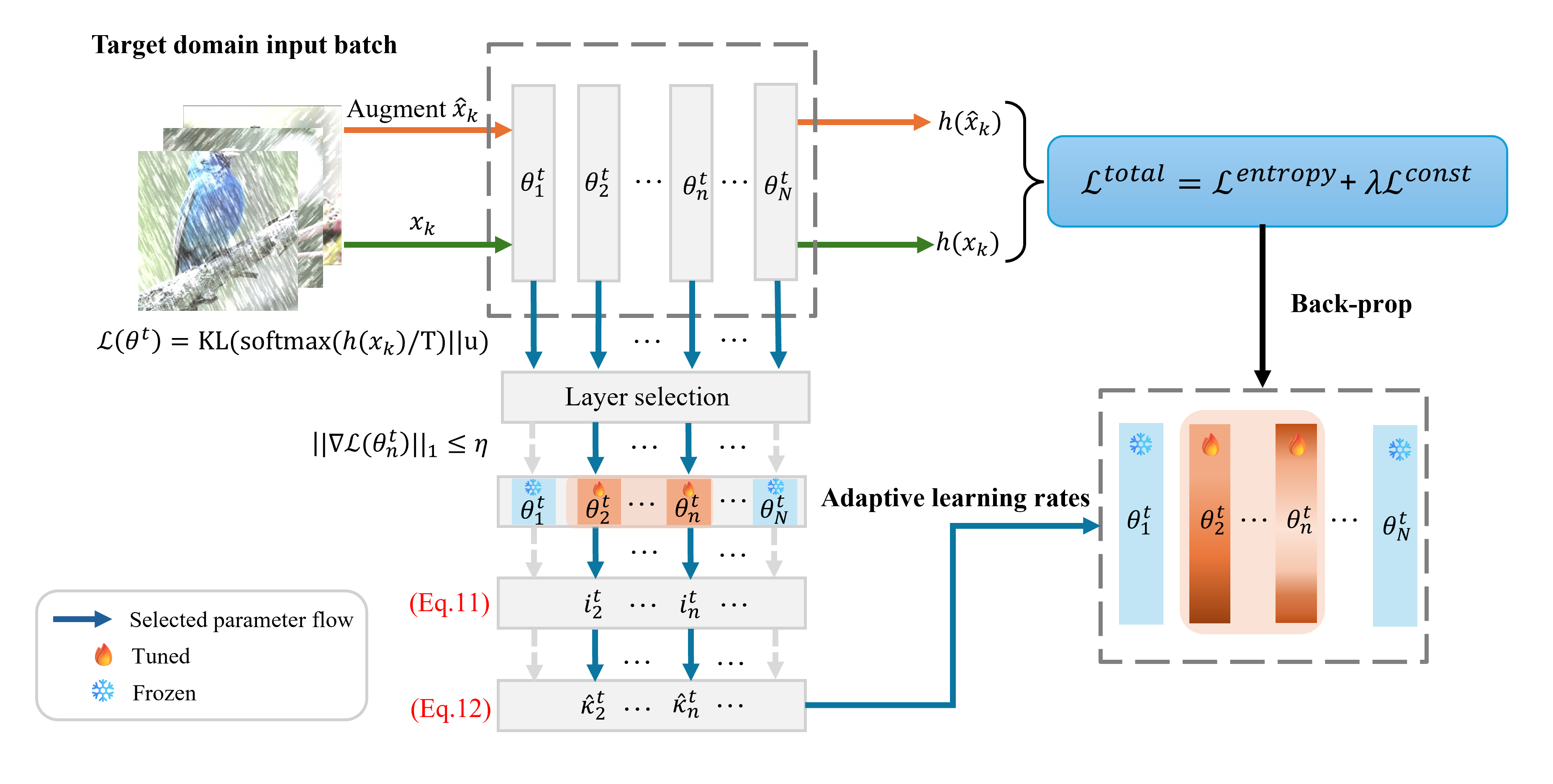
The core idea is to adapt the model parameters at each layer independently, rather than adapting the entire model at once. This "layerwise" adaptation allows the model to specialize to the target data more effectively than global adaptation. To prevent overfitting, the researchers also introduce an "early stopping" mechanism, where the adaptation process is stopped independently for each layer once its performance on a held-out validation set starts to degrade.
Compared to previous TTA approaches, such as rdumb: A Simple Approach That Questions Our Progress, Distribution-Aware Continual Test-Time Adaptation, and AETTA: Label-Free Accuracy Estimation at Test Time, the proposed LESTA method is more parameter-efficient, as it only updates a subset of the model parameters. It also outperforms Test-Time Model Adaptation with Only Forward Passes and Discriminative Sample-Guided Parameter-Efficient Feature Space in terms of accuracy on various benchmark datasets.
Critical Analysis
The authors provide a thorough evaluation of the LESTA approach, including comparisons to several state-of-the-art TTA methods. The results demonstrate the effectiveness of the layerwise adaptation and early stopping mechanisms in improving model performance while being more parameter-efficient.
However, the paper does not extensively discuss the potential limitations or caveats of the LESTA method. For example, it's unclear how the performance and parameter efficiency of LESTA might scale with model size and complexity, or how sensitive the method is to the choice of hyperparameters, such as the early stopping criteria.
Additionally, the paper focuses on image classification tasks, and it's uncertain how well the LESTA approach would generalize to other domains, such as natural language processing or speech recognition. Further research and experimentation would be needed to fully understand the broader applicability of this technique.
Conclusion
Layerwise Early Stopping for Test Time Adaptation presents a novel and promising approach to improving the performance of machine learning models during the testing or deployment phase. By adapting the model parameters at each layer independently and stopping the adaptation process early, the LESTA method achieves better accuracy while being more parameter-efficient than full model adaptation.
This research highlights the potential benefits of tailoring model adaptation strategies to the specific needs and constraints of real-world deployment scenarios. As machine learning models become increasingly ubiquitous in various applications, techniques like LESTA can play a crucial role in ensuring these models perform reliably and effectively in the face of diverse, unseen data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Layerwise Early Stopping for Test Time Adaptation
Sabyasachi Sahoo, Mostafa ElAraby, Jonas Ngnawe, Yann Pequignot, Frederic Precioso, Christian Gagne
Test Time Adaptation (TTA) addresses the problem of distribution shift by enabling pretrained models to learn new features on an unseen domain at test time. However, it poses a significant challenge to maintain a balance between learning new features and retaining useful pretrained features. In this paper, we propose Layerwise EArly STopping (LEAST) for TTA to address this problem. The key idea is to stop adapting individual layers during TTA if the features being learned do not appear beneficial for the new domain. For that purpose, we propose using a novel gradient-based metric to measure the relevance of the current learnt features to the new domain without the need for supervised labels. More specifically, we propose to use this metric to determine dynamically when to stop updating each layer during TTA. This enables a more balanced adaptation, restricted to layers benefiting from it, and only for a certain number of steps. Such an approach also has the added effect of limiting the forgetting of pretrained features useful for dealing with new domains. Through extensive experiments, we demonstrate that Layerwise Early Stopping improves the performance of existing TTA approaches across multiple datasets, domain shifts, model architectures, and TTA losses.
Read more4/8/2024
0
PALM: Pushing Adaptive Learning Rate Mechanisms for Continual Test-Time Adaptation
Sarthak Kumar Maharana, Baoming Zhang, Yunhui Guo
Real-world vision models in dynamic environments face rapid shifts in domain distributions, leading to decreased recognition performance. Using unlabeled test data, continual test-time adaptation (CTTA) directly adjusts a pre-trained source discriminative model to these changing domains. A highly effective CTTA method involves applying layer-wise adaptive learning rates for selectively adapting pre-trained layers. However, it suffers from the poor estimation of domain shift and the inaccuracies arising from the pseudo-labels. This work aims to overcome these limitations by identifying layers for adaptation via quantifying model prediction uncertainty without relying on pseudo-labels. We utilize the magnitude of gradients as a metric, calculated by backpropagating the KL divergence between the softmax output and a uniform distribution, to select layers for further adaptation. Subsequently, for the parameters exclusively belonging to these selected layers, with the remaining ones frozen, we evaluate their sensitivity to approximate the domain shift and adjust their learning rates accordingly. We conduct extensive image classification experiments on CIFAR-10C, CIFAR-100C, and ImageNet-C, demonstrating the superior efficacy of our method compared to prior approaches.
Read more8/27/2024

0
Enhancing Test Time Adaptation with Few-shot Guidance
Siqi Luo, Yi Xin, Yuntao Du, Zhongwei Wan, Tao Tan, Guangtao Zhai, Xiaohong Liu
Deep neural networks often encounter significant performance drops while facing with domain shifts between training (source) and test (target) data. To address this issue, Test Time Adaptation (TTA) methods have been proposed to adapt pre-trained source model to handle out-of-distribution streaming target data. Although these methods offer some relief, they lack a reliable mechanism for domain shift correction, which can often be erratic in real-world applications. In response, we develop Few-Shot Test Time Adaptation (FS-TTA), a novel and practical setting that utilizes a few-shot support set on top of TTA. Adhering to the principle of few inputs, big gains, FS-TTA reduces blind exploration in unseen target domains. Furthermore, we propose a two-stage framework to tackle FS-TTA, including (i) fine-tuning the pre-trained source model with few-shot support set, along with using feature diversity augmentation module to avoid overfitting, (ii) implementing test time adaptation based on prototype memory bank guidance to produce high quality pseudo-label for model adaptation. Through extensive experiments on three cross-domain classification benchmarks, we demonstrate the superior performance and reliability of our FS-TTA and framework.
Read more9/4/2024

0
New!Hybrid-TTA: Continual Test-time Adaptation via Dynamic Domain Shift Detection
Hyewon Park, Hyejin Park, Jueun Ko, Dongbo Min
Continual Test Time Adaptation (CTTA) has emerged as a critical approach for bridging the domain gap between the controlled training environments and the real-world scenarios, enhancing model adaptability and robustness. Existing CTTA methods, typically categorized into Full-Tuning (FT) and Efficient-Tuning (ET), struggle with effectively addressing domain shifts. To overcome these challenges, we propose Hybrid-TTA, a holistic approach that dynamically selects instance-wise tuning method for optimal adaptation. Our approach introduces the Dynamic Domain Shift Detection (DDSD) strategy, which identifies domain shifts by leveraging temporal correlations in input sequences and dynamically switches between FT and ET to adapt to varying domain shifts effectively. Additionally, the Masked Image Modeling based Adaptation (MIMA) framework is integrated to ensure domain-agnostic robustness with minimal computational overhead. Our Hybrid-TTA achieves a notable 1.6%p improvement in mIoU on the Cityscapes-to-ACDC benchmark dataset, surpassing previous state-of-the-art methods and offering a robust solution for real-world continual adaptation challenges.
Read more9/16/2024