Unraveling the Key Components of OOD Generalization via Diversification
2312.16313
0
0

Abstract
Supervised learning datasets may contain multiple cues that explain the training set equally well, i.e., learning any of them would lead to the correct predictions on the training data. However, many of them can be spurious, i.e., lose their predictive power under a distribution shift and consequently fail to generalize to out-of-distribution (OOD) data. Recently developed diversification methods (Lee et al., 2023; Pagliardini et al., 2023) approach this problem by finding multiple diverse hypotheses that rely on different features. This paper aims to study this class of methods and identify the key components contributing to their OOD generalization abilities. We show that (1) diversification methods are highly sensitive to the distribution of the unlabeled data used for diversification and can underperform significantly when away from a method-specific sweet spot. (2) Diversification alone is insufficient for OOD generalization. The choice of the used learning algorithm, e.g., the model's architecture and pretraining, is crucial. In standard experiments (classification on Waterbirds and Office-Home datasets), using the second-best choice leads to an up to 20% absolute drop in accuracy. (3) The optimal choice of learning algorithm depends on the unlabeled data and vice versa i.e. they are co-dependent. (4) Finally, we show that, in practice, the above pitfalls cannot be alleviated by increasing the number of diverse hypotheses, the major feature of diversification methods. These findings provide a clearer understanding of the critical design factors influencing the OOD generalization abilities of diversification methods. They can guide practitioners in how to use the existing methods best and guide researchers in developing new, better ones.
Create account to get full access
Overview
- This paper investigates the key components that contribute to Out-of-Distribution (OOD) generalization in machine learning models.
- The authors propose a learning approach called "Learning via Diversification" that aims to improve OOD generalization by encouraging diverse feature representations during training.
- The paper presents experiments and analyses to understand the underlying mechanisms behind the proposed approach and its impact on OOD performance.
Plain English Explanation
Machine learning models are often trained on a specific set of data, but they are expected to perform well on new, unseen data as well. This ability to generalize to "out-of-distribution" (OOD) data is a crucial challenge in the field.
The researchers in this paper explore ways to improve a model's ability to generalize to OOD data. They propose a new training approach called "Learning via Diversification" that encourages the model to learn diverse features during the training process. The idea is that by developing a more diverse set of features, the model will be better equipped to handle a wider range of data, including OOD examples.
Through a series of experiments and analyses, the researchers aim to uncover the key factors that contribute to OOD generalization. They investigate how their proposed approach impacts the model's feature representations and performance on OOD tasks. The goal is to gain a deeper understanding of the mechanisms behind OOD generalization and provide insights that can help improve the robustness and reliability of machine learning models.
Technical Explanation
The paper introduces a new training approach called "Learning via Diversification" that aims to enhance a model's ability to generalize to out-of-distribution (OOD) data. The key idea is to encourage the model to learn diverse feature representations during training, which can be achieved through a diversification loss term in the overall objective function.
The authors conduct a series of experiments on various benchmark datasets to evaluate the effectiveness of their proposed approach. They analyze the learned feature representations, the model's performance on OOD tasks, and the impact of different components of the diversification loss. The results suggest that the diversification-based training can lead to more robust and transferable features, ultimately improving the model's OOD generalization.
The paper also provides insights into the underlying mechanisms behind the proposed approach. The authors hypothesize that the diversification loss encourages the model to learn a wider range of features, which can help the model better handle the distribution shift between the training and OOD data. Additionally, the diversification loss is shown to promote the learning of more semantically meaningful features, further contributing to the model's OOD generalization capabilities.
Critical Analysis
The paper presents a well-designed and comprehensive study on improving OOD generalization through a diversification-based training approach. The proposed method and the thorough experimental evaluation provide valuable insights into the key factors that contribute to better OOD performance.
One potential limitation of the study is the focus on a specific set of benchmark datasets. While the chosen datasets are widely used in the field, it would be beneficial to explore the generalization of the proposed approach across a broader range of domains and problem settings. Additionally, the authors acknowledge the need for further investigation into the interpretability and transferability of the learned feature representations, as well as the potential trade-offs between OOD performance and in-distribution accuracy.
Nonetheless, the paper makes a significant contribution to the understanding of OOD generalization and provides a promising direction for developing more robust and versatile machine learning models. The insights gained from this research can inform the design of future OOD-focused training strategies and inspire further advancements in the field.
Conclusion
This paper presents a novel approach called "Learning via Diversification" that aims to improve a model's ability to generalize to out-of-distribution (OOD) data. The key idea is to encourage the model to learn diverse feature representations during training, which can lead to more robust and transferable features.
Through extensive experiments and analyses, the researchers have provided valuable insights into the underlying mechanisms behind OOD generalization. The results suggest that the diversification-based training can promote the learning of semantically meaningful and diverse features, ultimately enhancing the model's performance on OOD tasks.
The insights gained from this work can have significant implications for the development of more reliable and versatile machine learning models. By better understanding the factors that contribute to OOD generalization, researchers and practitioners can design more effective training strategies and improve the real-world applicability of these models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mixture Data for Training Cannot Ensure Out-of-distribution Generalization
Songming Zhang, Yuxiao Luo, Qizhou Wang, Haoang Chi, Xiaofeng Chen, Bo Han, Jinyan Li
0
0
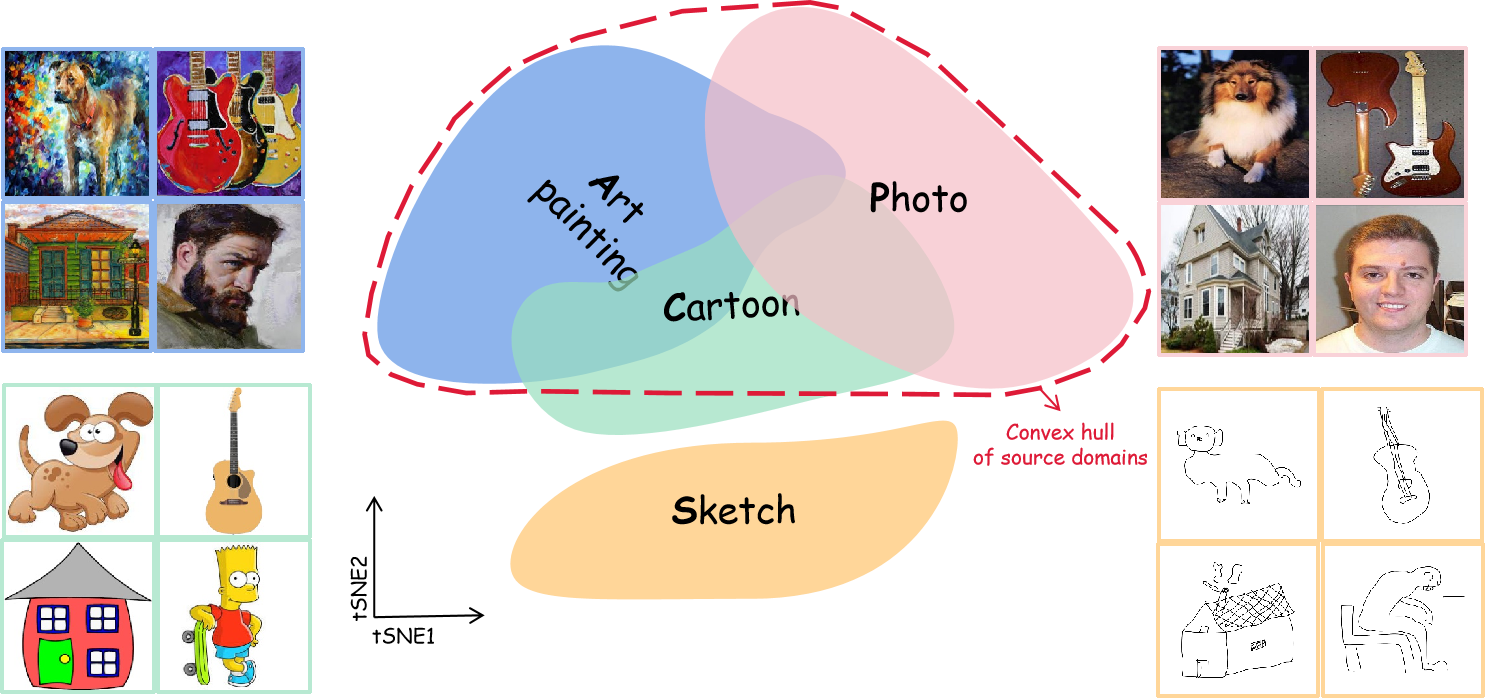
Deep neural networks often face generalization problems to handle out-of-distribution (OOD) data, and there remains a notable theoretical gap between the contributing factors and their respective impacts. Literature evidence from in-distribution data has suggested that generalization error can shrink if the size of mixture data for training increases. However, when it comes to OOD samples, this conventional understanding does not hold anymore -- Increasing the size of training data does not always lead to a reduction in the test generalization error. In fact, diverse trends of the errors have been found across various shifting scenarios including those decreasing trends under a power-law pattern, initial declines followed by increases, or continuous stable patterns. Previous work has approached OOD data qualitatively, treating them merely as samples unseen during training, which are hard to explain the complicated non-monotonic trends. In this work, we quantitatively redefine OOD data as those situated outside the convex hull of mixed training data and establish novel generalization error bounds to comprehend the counterintuitive observations better. Our proof of the new risk bound agrees that the efficacy of well-trained models can be guaranteed for unseen data within the convex hull; More interestingly, but for OOD data beyond this coverage, the generalization cannot be ensured, which aligns with our observations. Furthermore, we attempted various OOD techniques to underscore that our results not only explain insightful observations in recent OOD generalization work, such as the significance of diverse data and the sensitivity to unseen shifts of existing algorithms, but it also inspires a novel and effective data selection strategy.
4/24/2024
On the Learnability of Out-of-distribution Detection
Zhen Fang, Yixuan Li, Feng Liu, Bo Han, Jie Lu
0
0
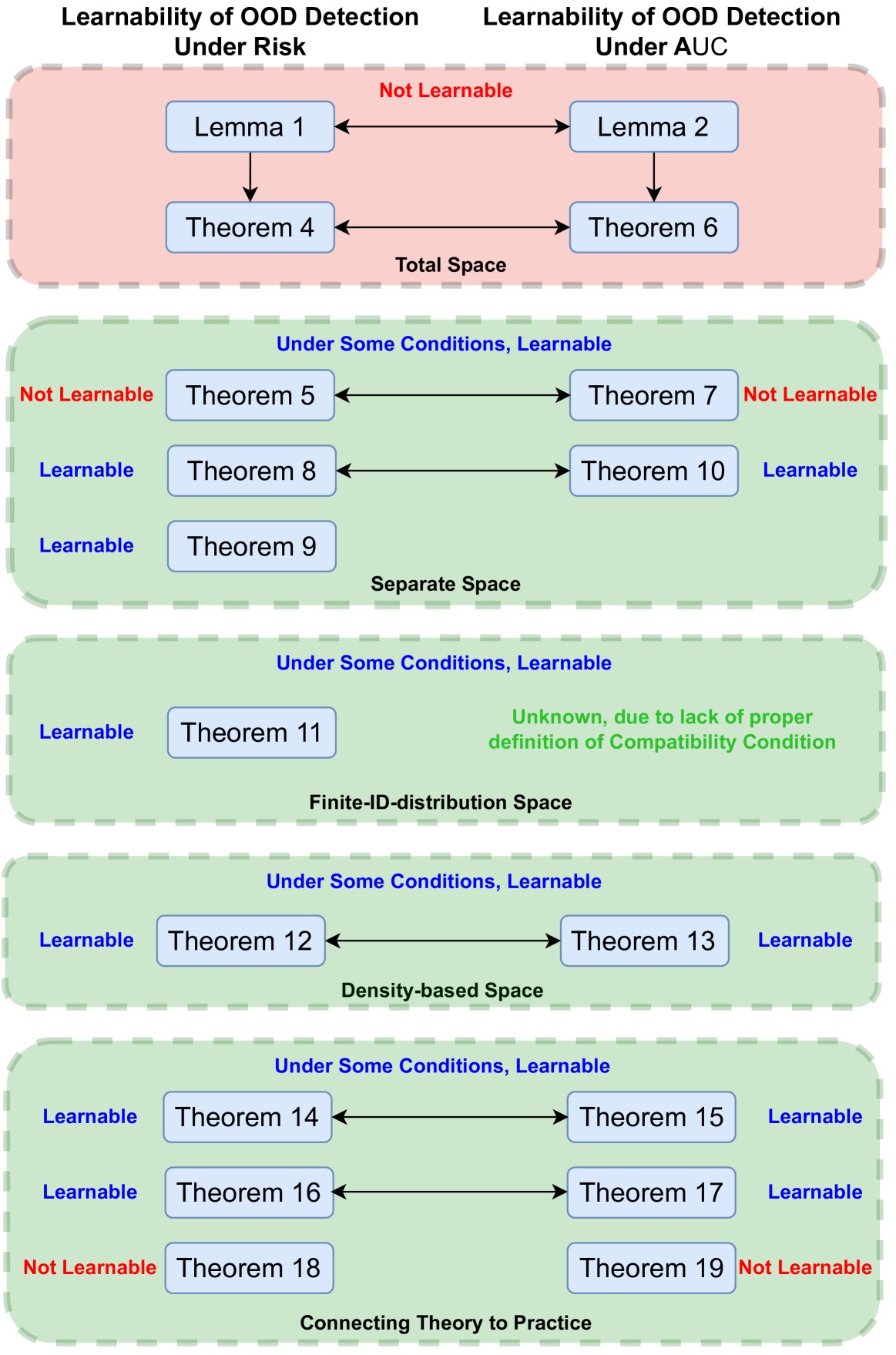
Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms, and corresponding learning theory is still an open problem. To study the generalization of OOD detection, this paper investigates the probably approximately correct (PAC) learning theory of OOD detection that fits the commonly used evaluation metrics in the literature. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we offer theoretical support for representative OOD detection works based on our OOD theory.
4/9/2024
📈
Overcoming the Pitfalls of Vision-Language Model Finetuning for OOD Generalization
Yuhang Zang, Hanlin Goh, Josh Susskind, Chen Huang
0
0
Existing vision-language models exhibit strong generalization on a variety of visual domains and tasks. However, such models mainly perform zero-shot recognition in a closed-set manner, and thus struggle to handle open-domain visual concepts by design. There are recent finetuning methods, such as prompt learning, that not only study the discrimination between in-distribution (ID) and out-of-distribution (OOD) samples, but also show some improvements in both ID and OOD accuracies. In this paper, we first demonstrate that vision-language models, after long enough finetuning but without proper regularization, tend to overfit the known classes in the given dataset, with degraded performance on unknown classes. Then we propose a novel approach OGEN to address this pitfall, with the main focus on improving the OOD GENeralization of finetuned models. Specifically, a class-conditional feature generator is introduced to synthesize OOD features using just the class name of any unknown class. Such synthesized features will provide useful knowledge about unknowns and help regularize the decision boundary between ID and OOD data when optimized jointly. Equally important is our adaptive self-distillation mechanism to regularize our feature generation model during joint optimization, i.e., adaptively transferring knowledge between model states to further prevent overfitting. Experiments validate that our method yields convincing gains in OOD generalization performance in different settings. Code: https://github.com/apple/ml-ogen.
4/17/2024

Out-of-Distribution Data: An Acquaintance of Adversarial Examples -- A Survey
Naveen Karunanayake, Ravin Gunawardena, Suranga Seneviratne, Sanjay Chawla
0
0
Deep neural networks (DNNs) deployed in real-world applications can encounter out-of-distribution (OOD) data and adversarial examples. These represent distinct forms of distributional shifts that can significantly impact DNNs' reliability and robustness. Traditionally, research has addressed OOD detection and adversarial robustness as separate challenges. This survey focuses on the intersection of these two areas, examining how the research community has investigated them together. Consequently, we identify two key research directions: robust OOD detection and unified robustness. Robust OOD detection aims to differentiate between in-distribution (ID) data and OOD data, even when they are adversarially manipulated to deceive the OOD detector. Unified robustness seeks a single approach to make DNNs robust against both adversarial attacks and OOD inputs. Accordingly, first, we establish a taxonomy based on the concept of distributional shifts. This framework clarifies how robust OOD detection and unified robustness relate to other research areas addressing distributional shifts, such as OOD detection, open set recognition, and anomaly detection. Subsequently, we review existing work on robust OOD detection and unified robustness. Finally, we highlight the limitations of the existing work and propose promising research directions that explore adversarial and OOD inputs within a unified framework.
4/9/2024