Mixture Data for Training Cannot Ensure Out-of-distribution Generalization
2312.16243
0
0
Abstract
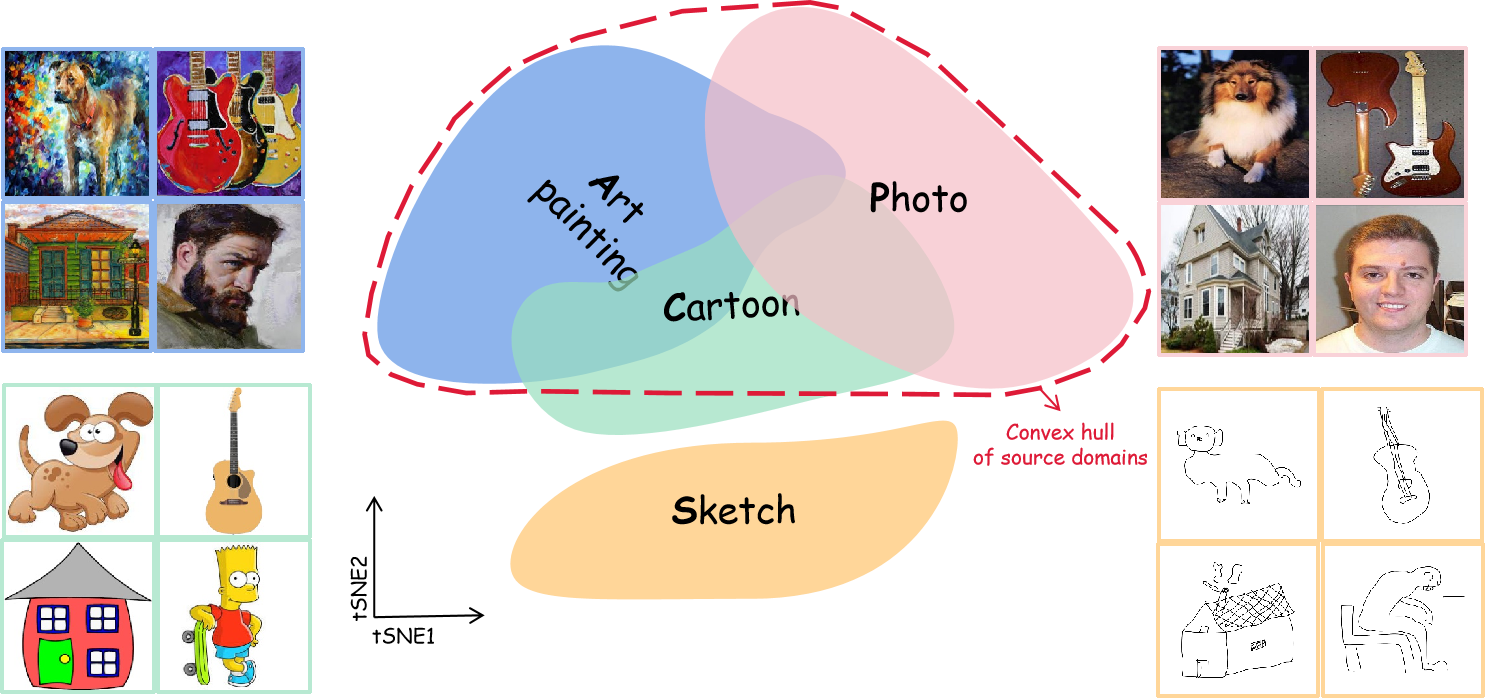
Deep neural networks often face generalization problems to handle out-of-distribution (OOD) data, and there remains a notable theoretical gap between the contributing factors and their respective impacts. Literature evidence from in-distribution data has suggested that generalization error can shrink if the size of mixture data for training increases. However, when it comes to OOD samples, this conventional understanding does not hold anymore -- Increasing the size of training data does not always lead to a reduction in the test generalization error. In fact, diverse trends of the errors have been found across various shifting scenarios including those decreasing trends under a power-law pattern, initial declines followed by increases, or continuous stable patterns. Previous work has approached OOD data qualitatively, treating them merely as samples unseen during training, which are hard to explain the complicated non-monotonic trends. In this work, we quantitatively redefine OOD data as those situated outside the convex hull of mixed training data and establish novel generalization error bounds to comprehend the counterintuitive observations better. Our proof of the new risk bound agrees that the efficacy of well-trained models can be guaranteed for unseen data within the convex hull; More interestingly, but for OOD data beyond this coverage, the generalization cannot be ensured, which aligns with our observations. Furthermore, we attempted various OOD techniques to underscore that our results not only explain insightful observations in recent OOD generalization work, such as the significance of diverse data and the sensitivity to unseen shifts of existing algorithms, but it also inspires a novel and effective data selection strategy.
Create account to get full access
Overview
- This paper examines the assumption that all unseen data is out-of-distribution (OOD) for machine learning models.
- It explores different error scenarios that can arise when attempting to generalize to OOD data.
- The paper provides an example using Fisher's Linear Discriminant to illustrate these error scenarios.
- It also discusses the implications for OOD detection and generalization, highlighting the importance of understanding the underlying data distribution.
Plain English Explanation
When machine learning models are deployed, they often encounter data that they haven't seen during training. The common assumption is that this "unseen" data is automatically considered "out-of-distribution" (OOD), meaning it's fundamentally different from the data the model was trained on.
However, this paper challenges that assumption. It shows that there can be different types of errors that occur when a model tries to generalize to OOD data. In some cases, the unseen data may actually be within the distribution of the training data, but the model still struggles to make accurate predictions.
To illustrate this, the paper uses an example of a statistical technique called Fisher's Linear Discriminant. It demonstrates how the model can make mistakes even when the unseen data is not truly OOD. This highlights the need for a more nuanced understanding of the relationship between the training data and the real-world data a model will encounter in the field.
The key takeaway is that simply labeling all unseen data as OOD can be an oversimplification. The paper suggests that researchers and practitioners need to delve deeper into the underlying data distributions and the specific error scenarios that can arise when trying to generalize to new, unseen data.
Technical Explanation
The paper starts by challenging the common assumption that all unseen data is inherently out-of-distribution (OOD) for machine learning models. It argues that there are different error scenarios that can occur when attempting to generalize to OOD data, and that not all unseen data necessarily falls into the OOD category.
To illustrate this, the paper provides an example using Fisher's Linear Discriminant, a statistical technique for classification. The example shows how the model can make mistakes even when the unseen data is not truly OOD, highlighting the need for a more nuanced understanding of the relationship between the training data and the real-world data a model will encounter.
The paper also discusses the implications of these findings for OOD detection and generalization. It emphasizes the importance of understanding the underlying data distribution, as opposed to simply assuming that all unseen data is OOD. This is crucial for developing robust and reliable machine learning models that can effectively generalize to new, previously unseen situations.
Critical Analysis
The paper raises valid concerns about the oversimplification of the OOD assumption. By demonstrating error scenarios where unseen data is not truly OOD, the authors highlight the need for a more nuanced approach to understanding the limitations of machine learning models when faced with new, previously unseen data.
However, the paper does not delve deeply into the specific reasons why the unseen data may still be problematic for the model, even if it is not strictly OOD. The authors could have explored the underlying factors, such as distributional shift, that can contribute to these errors.
Additionally, the paper could have provided more concrete recommendations for how researchers and practitioners can better detect and handle these more subtle cases of non-OOD generalization failures. This could involve advanced OOD detection techniques or the development of more diverse benchmark datasets to assess model robustness.
Overall, the paper successfully challenges a common assumption in the field and highlights the need for a more nuanced understanding of the relationship between training data and real-world data. However, further research and practical guidance could help address the challenges raised in this work.
Conclusion
This paper presents an important challenge to the assumption that all unseen data is automatically considered out-of-distribution (OOD) for machine learning models. By providing an example using Fisher's Linear Discriminant, the authors demonstrate that there can be error scenarios where the unseen data is not truly OOD, yet the model still struggles to generalize effectively.
The key takeaway is that researchers and practitioners need to move beyond simplistic notions of OOD and instead develop a more sophisticated understanding of the underlying data distributions and the specific challenges that can arise when attempting to generalize to new, previously unseen situations. This has significant implications for the development of robust and reliable machine learning systems that can operate effectively in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unraveling the Key Components of OOD Generalization via Diversification
Harold Benoit, Liangze Jiang, Andrei Atanov, Ou{g}uzhan Fatih Kar, Mattia Rigotti, Amir Zamir
0
0
Supervised learning datasets may contain multiple cues that explain the training set equally well, i.e., learning any of them would lead to the correct predictions on the training data. However, many of them can be spurious, i.e., lose their predictive power under a distribution shift and consequently fail to generalize to out-of-distribution (OOD) data. Recently developed diversification methods (Lee et al., 2023; Pagliardini et al., 2023) approach this problem by finding multiple diverse hypotheses that rely on different features. This paper aims to study this class of methods and identify the key components contributing to their OOD generalization abilities. We show that (1) diversification methods are highly sensitive to the distribution of the unlabeled data used for diversification and can underperform significantly when away from a method-specific sweet spot. (2) Diversification alone is insufficient for OOD generalization. The choice of the used learning algorithm, e.g., the model's architecture and pretraining, is crucial. In standard experiments (classification on Waterbirds and Office-Home datasets), using the second-best choice leads to an up to 20% absolute drop in accuracy. (3) The optimal choice of learning algorithm depends on the unlabeled data and vice versa i.e. they are co-dependent. (4) Finally, we show that, in practice, the above pitfalls cannot be alleviated by increasing the number of diverse hypotheses, the major feature of diversification methods. These findings provide a clearer understanding of the critical design factors influencing the OOD generalization abilities of diversification methods. They can guide practitioners in how to use the existing methods best and guide researchers in developing new, better ones.
4/23/2024

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024
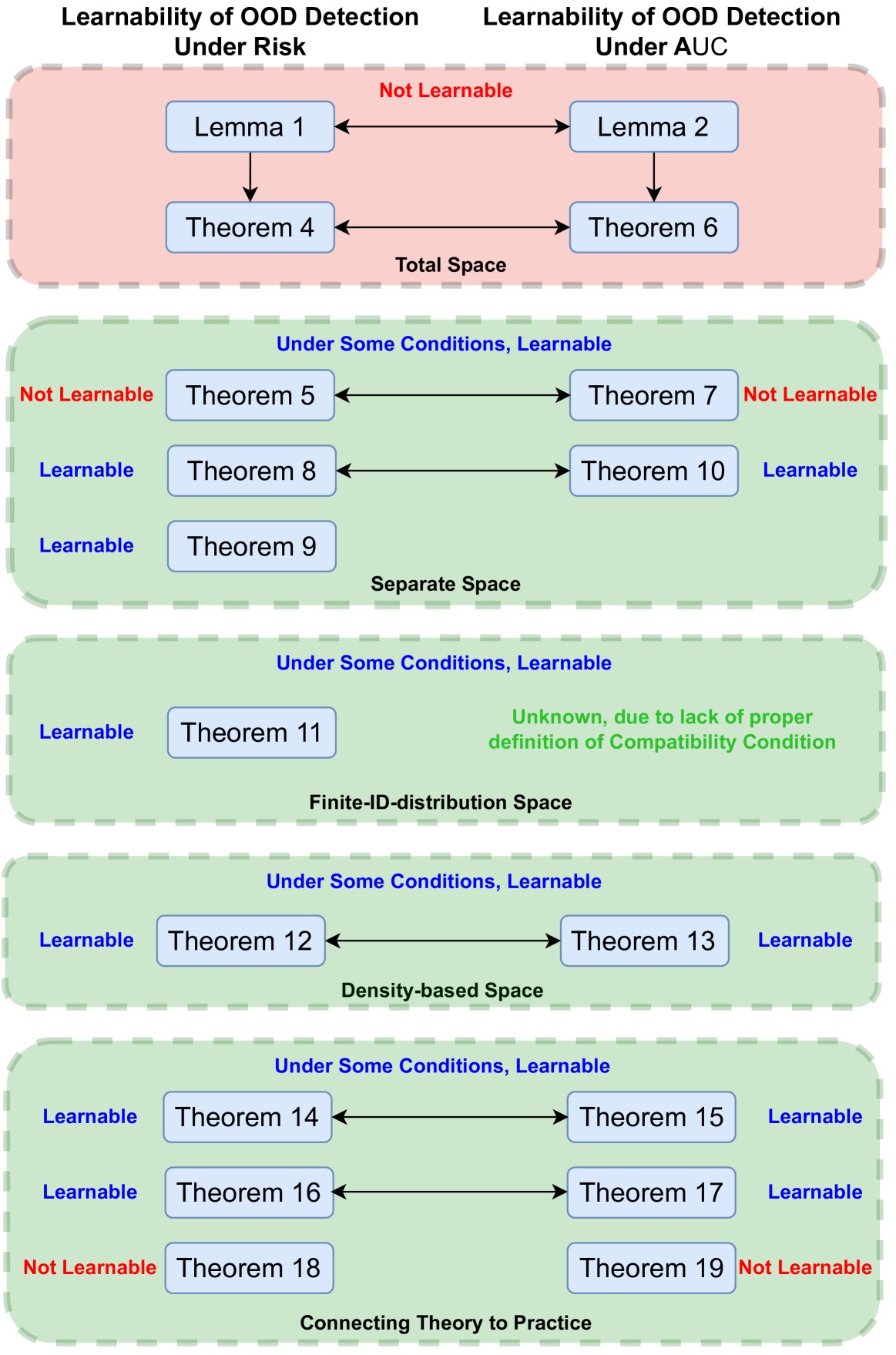
On the Learnability of Out-of-distribution Detection
Zhen Fang, Yixuan Li, Feng Liu, Bo Han, Jie Lu
0
0
Supervised learning aims to train a classifier under the assumption that training and test data are from the same distribution. To ease the above assumption, researchers have studied a more realistic setting: out-of-distribution (OOD) detection, where test data may come from classes that are unknown during training (i.e., OOD data). Due to the unavailability and diversity of OOD data, good generalization ability is crucial for effective OOD detection algorithms, and corresponding learning theory is still an open problem. To study the generalization of OOD detection, this paper investigates the probably approximately correct (PAC) learning theory of OOD detection that fits the commonly used evaluation metrics in the literature. First, we find a necessary condition for the learnability of OOD detection. Then, using this condition, we prove several impossibility theorems for the learnability of OOD detection under some scenarios. Although the impossibility theorems are frustrating, we find that some conditions of these impossibility theorems may not hold in some practical scenarios. Based on this observation, we next give several necessary and sufficient conditions to characterize the learnability of OOD detection in some practical scenarios. Lastly, we offer theoretical support for representative OOD detection works based on our OOD theory.
4/9/2024

Out-of-Distribution Data: An Acquaintance of Adversarial Examples -- A Survey
Naveen Karunanayake, Ravin Gunawardena, Suranga Seneviratne, Sanjay Chawla
0
0
Deep neural networks (DNNs) deployed in real-world applications can encounter out-of-distribution (OOD) data and adversarial examples. These represent distinct forms of distributional shifts that can significantly impact DNNs' reliability and robustness. Traditionally, research has addressed OOD detection and adversarial robustness as separate challenges. This survey focuses on the intersection of these two areas, examining how the research community has investigated them together. Consequently, we identify two key research directions: robust OOD detection and unified robustness. Robust OOD detection aims to differentiate between in-distribution (ID) data and OOD data, even when they are adversarially manipulated to deceive the OOD detector. Unified robustness seeks a single approach to make DNNs robust against both adversarial attacks and OOD inputs. Accordingly, first, we establish a taxonomy based on the concept of distributional shifts. This framework clarifies how robust OOD detection and unified robustness relate to other research areas addressing distributional shifts, such as OOD detection, open set recognition, and anomaly detection. Subsequently, we review existing work on robust OOD detection and unified robustness. Finally, we highlight the limitations of the existing work and propose promising research directions that explore adversarial and OOD inputs within a unified framework.
4/9/2024