Unsupervised, Bottom-up Category Discovery for Symbol Grounding with a Curious Robot

0

Sign in to get full access
Overview
- This paper presents an unsupervised, bottom-up approach for a robot to discover categories and associate them with symbols through curious exploration.
- The robot learns to ground symbols to visual concepts without any prior knowledge or supervision.
- The method uses an information-theoretic approach to drive the robot's curiosity and guide its learning process.
Plain English Explanation
The researchers developed a way for a robot to learn about its world through its own curious exploration, without being told what things are called or how to recognize them. The robot starts out not knowing anything, but it has a drive to learn and understand its environment.
As the robot moves around and interacts with objects, it keeps track of the visual information it observes and the sounds or words that it hears. Over time, the robot starts to notice patterns - certain visual features tend to go along with certain sounds. The robot uses an information theory approach to figure out which visual-sound combinations provide the most new and useful information.
This allows the robot to discover distinct categories of objects on its own, and associate those categories with the corresponding words or symbols. For example, the robot might notice that certain shapes, colors, and textures tend to go along with the word "ball," and it can start to recognize balls as a distinct category. The robot doesn't need to be told what a ball is - it figures it out through its own curious exploration.
This approach allows the robot to learn about its environment in a natural, flexible way, without relying on pre-defined labels or categories. It's a step towards robots that can truly understand the world around them, rather than just recognizing predefined objects.
Technical Explanation
The researchers present an unsupervised, bottom-up approach for a robot to discover visual categories and associate them with linguistic symbols through curious exploration. The key components are:
-
Visual processing: The robot uses a convolutional neural network to extract visual features from its observations.
-
Language processing: The robot uses a recurrent neural network to process the linguistic inputs it receives, such as spoken words.
-
Information-theoretic curiosity: The robot uses an information gain metric to drive its exploration, preferentially attending to situations that are likely to provide new and useful information about the environment.
-
Associative learning: The robot learns associations between the discovered visual categories and the corresponding linguistic symbols through a co-occurrence learning mechanism.
The method is evaluated on a dataset of visual observations and spoken words, showing that the robot is able to discover meaningful visual categories and correctly associate them with the appropriate linguistic labels, without any prior knowledge or supervision.
Critical Analysis
The presented approach is a promising step towards more autonomous, flexible robot learning. By relying on curious exploration and information-theoretic principles rather than pre-defined categories, the method has the potential to enable robots to fluidly adapt to new environments and situations.
However, the paper does not address several important limitations and potential concerns. For example, the performance of the method may degrade in more complex, cluttered, or dynamic environments where visual-linguistic associations are less clear-cut. Additionally, the paper does not explore how the learned categories and associations could be refined or expanded over time through continued learning.
Further research would be needed to understand the scalability of this approach, its robustness to noisy or ambiguous inputs, and its ability to handle more open-ended language beyond simple object labels. Incorporating additional cognitive mechanisms, such as memory, reasoning, and abstraction, could also enhance the robot's ability to develop rich and coherent conceptual representations.
Conclusion
This paper presents an intriguing approach for a robot to discover and ground visual categories to linguistic symbols through curious, unsupervised exploration. By leveraging information-theoretic principles to drive learning, the method offers a promising direction for developing more flexible and adaptive robot intelligence, capable of learning about the world in a more autonomous and natural way. While the current implementation has some limitations, the core ideas have the potential to contribute to the broader goal of creating robots that can truly understand and interact with their environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised, Bottom-up Category Discovery for Symbol Grounding with a Curious Robot
Catherine Henry, Casey Kennington
Towards addressing the Symbol Grounding Problem and motivated by early childhood language development, we leverage a robot which has been equipped with an approximate model of curiosity with particular focus on bottom-up building of unsupervised categories grounded in the physical world. That is, rather than starting with a top-down symbol (e.g., a word referring to an object) and providing meaning through the application of predetermined samples, the robot autonomously and gradually breaks up its exploration space into a series of increasingly specific unlabeled categories at which point an external expert may optionally provide a symbol association. We extend prior work by using a robot that can observe the visual world, introducing a higher dimensional sensory space, and using a more generalizable method of category building. Our experiments show that the robot learns categories based on actions and what it visually observes, and that those categories can be symbolically grounded into.https://info.arxiv.org/help/prep#comments
Read more4/5/2024

0
Unsupervised Learning of Effective Actions in Robotics
Marko Zaric, Jakob Hollenstein, Justus Piater, Erwan Renaudo
Learning actions that are relevant to decision-making and can be executed effectively is a key problem in autonomous robotics. Current state-of-the-art action representations in robotics lack proper effect-driven learning of the robot's actions. Although successful in solving manipulation tasks, deep learning methods also lack this ability, in addition to their high cost in terms of memory or training data. In this paper, we propose an unsupervised algorithm to discretize a continuous motion space and generate action prototypes, each producing different effects in the environment. After an exploration phase, the algorithm automatically builds a representation of the effects and groups motions into action prototypes, where motions more likely to produce an effect are represented more than those that lead to negligible changes. We evaluate our method on a simulated stair-climbing reinforcement learning task, and the preliminary results show that our effect driven discretization outperforms uniformly and randomly sampled discretizations in convergence speed and maximum reward.
Read more4/4/2024
👨🏫
0
Language, Environment, and Robotic Navigation
Johnathan E. Avery
This paper explores the integration of linguistic inputs within robotic navigation systems, drawing upon the symbol interdependency hypothesis to bridge the divide between symbolic and embodied cognition. It examines previous work incorporating language and semantics into Neural Network (NN) and Simultaneous Localization and Mapping (SLAM) approaches, highlighting how these integrations have advanced the field. By contrasting abstract symbol manipulation with sensory-motor grounding, we propose a unified framework where language functions both as an abstract communicative system and as a grounded representation of perceptual experiences. Our review of cognitive models of distributional semantics and their application to autonomous agents underscores the transformative potential of language-integrated systems.
Read more4/5/2024
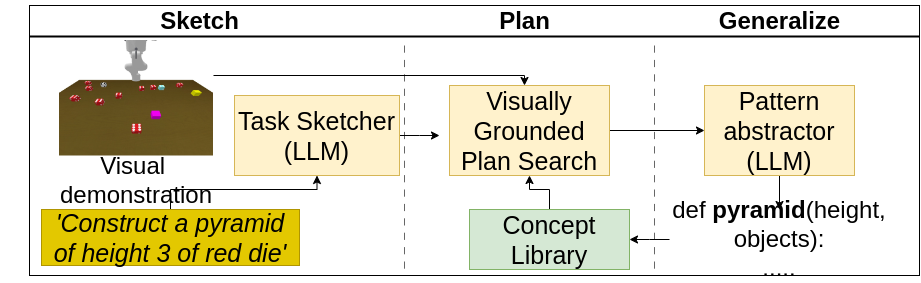
0
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Namasivayam Kalithasan, Sachit Sachdeva, Himanshu Gaurav Singh, Vishal Bindal, Arnav Tuli, Gurarmaan Singh Panjeta, Divyanshu Aggarwal, Rohan Paul, Parag Singla
Our goal is to enable embodied agents to learn inductively generalizable spatial concepts, e.g., learning staircase as an inductive composition of towers of increasing height. Given a human demonstration, we seek a learning architecture that infers a succinct ${program}$ representation that explains the observed instance. Additionally, the approach should generalize inductively to novel structures of different sizes or complex structures expressed as a hierarchical composition of previously learned concepts. Existing approaches that use code generation capabilities of pre-trained large (visual) language models, as well as purely neural models, show poor generalization to a-priori unseen complex concepts. Our key insight is to factor inductive concept learning as (i) ${it Sketch:}$ detecting and inferring a coarse signature of a new concept (ii) ${it Plan:}$ performing MCTS search over grounded action sequences (iii) ${it Generalize:}$ abstracting out grounded plans as inductive programs. Our pipeline facilitates generalization and modular reuse, enabling continual concept learning. Our approach combines the benefits of the code generation ability of large language models (LLM) along with grounded neural representations, resulting in neuro-symbolic programs that show stronger inductive generalization on the task of constructing complex structures in relation to LLM-only and neural-only approaches. Furthermore, we demonstrate reasoning and planning capabilities with learned concepts for embodied instruction following.
Read more5/30/2024