Unsupervised Composable Representations for Audio

0

Sign in to get full access
Overview
- Unsupervised learning of audio representations
- Composable representations that can be combined to generate new audio
- Enables flexible and versatile audio generation and manipulation
Plain English Explanation
This research explores unsupervised composable representations for audio. The key idea is to learn audio representations in an unsupervised way, where the representations can be combined to generate new audio. This allows for flexible and versatile audio generation and manipulation, without the need for labeled training data.
The representations are learned in a way that captures the underlying structure and semantics of audio, rather than just low-level features. This enables users to combine these representations in creative ways to produce new audio that maintains coherence and meaningful properties.
This approach has several advantages over traditional supervised methods for audio generation and manipulation. It avoids the need for large labeled datasets, which can be time-consuming and expensive to collect. It also allows for more flexible and expressive audio generation, as the representations can be recombined in novel ways.
Technical Explanation
The researchers learn the audio representations in an unsupervised way using a variational autoencoder (VAE) model. The VAE encodes the audio input into a latent representation, which can then be decoded back into the original audio.
Crucially, the latent representation is structured in a way that allows the individual components to be manipulated and recombined. This is achieved through the use of a disentangled latent space, where each dimension of the latent vector corresponds to a distinct semantic or structural aspect of the audio.
By learning these composable representations, the model can generate new audio by combining the latent components in novel ways. This allows for flexible and creative audio generation, as well as the ability to perform tasks like audio style transfer or audio editing.
Critical Analysis
The paper demonstrates promising results in terms of the quality and versatility of the generated audio. However, it is worth noting that the research is still in an early stage, and there may be some limitations or areas for further exploration.
For example, the paper does not provide a comprehensive evaluation of the generalization capabilities of the model, or its robustness to different types of audio data. Additionally, the computational and memory requirements of the model are not discussed in depth, which could be an important consideration for real-world applications.
Further research could also explore ways to improve the interpretability and controllability of the latent representations, or to incorporate additional sources of supervision or guidance to enhance the model's performance and capabilities.
Conclusion
This research represents an exciting step forward in the field of unsupervised audio representation learning. By learning composable representations that can be flexibly combined, the model enables a new level of creativity and versatility in audio generation and manipulation.
The potential applications of this technology are wide-ranging, from creative audio production to audio editing and restoration. As the research continues to evolve, it will be exciting to see how these unsupervised composable representations can be further developed and applied to real-world problems in the audio domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Composable Representations for Audio
Giovanni Bindi, Philippe Esling
Current generative models are able to generate high-quality artefacts but have been shown to struggle with compositional reasoning, which can be defined as the ability to generate complex structures from simpler elements. In this paper, we focus on the problem of compositional representation learning for music data, specifically targeting the fully-unsupervised setting. We propose a simple and extensible framework that leverages an explicit compositional inductive bias, defined by a flexible auto-encoding objective that can leverage any of the current state-of-art generative models. We demonstrate that our framework, used with diffusion models, naturally addresses the task of unsupervised audio source separation, showing that our model is able to perform high-quality separation. Our findings reveal that our proposal achieves comparable or superior performance with respect to other blind source separation methods and, furthermore, it even surpasses current state-of-art supervised baselines on signal-to-interference ratio metrics. Additionally, by learning an a-posteriori masking diffusion model in the space of composable representations, we achieve a system capable of seamlessly performing unsupervised source separation, unconditional generation, and variation generation. Finally, as our proposal works in the latent space of pre-trained neural audio codecs, it also provides a lower computational cost with respect to other neural baselines.
Read more8/20/2024

0
New!Compositional Audio Representation Learning
Sripathi Sridhar, Mark Cartwright
Human auditory perception is compositional in nature -- we identify auditory streams from auditory scenes with multiple sound events. However, such auditory scenes are typically represented using clip-level representations that do not disentangle the constituent sound sources. In this work, we learn source-centric audio representations where each sound source is represented using a distinct, disentangled source embedding in the audio representation. We propose two novel approaches to learning source-centric audio representations: a supervised model guided by classification and an unsupervised model guided by feature reconstruction, both of which outperform the baselines. We thoroughly evaluate the design choices of both approaches using an audio classification task. We find that supervision is beneficial to learn source-centric representations, and that reconstructing audio features is more useful than reconstructing spectrograms to learn unsupervised source-centric representations. Leveraging source-centric models can help unlock the potential of greater interpretability and more flexible decoding in machine listening.
Read more9/17/2024
🛸
0
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, Mark D. Plumbley
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate state-of-the-art or competitive performance against previous approaches. Our code, pretrained model, and demo are available at https://audioldm.github.io/audioldm2.
Read more5/14/2024
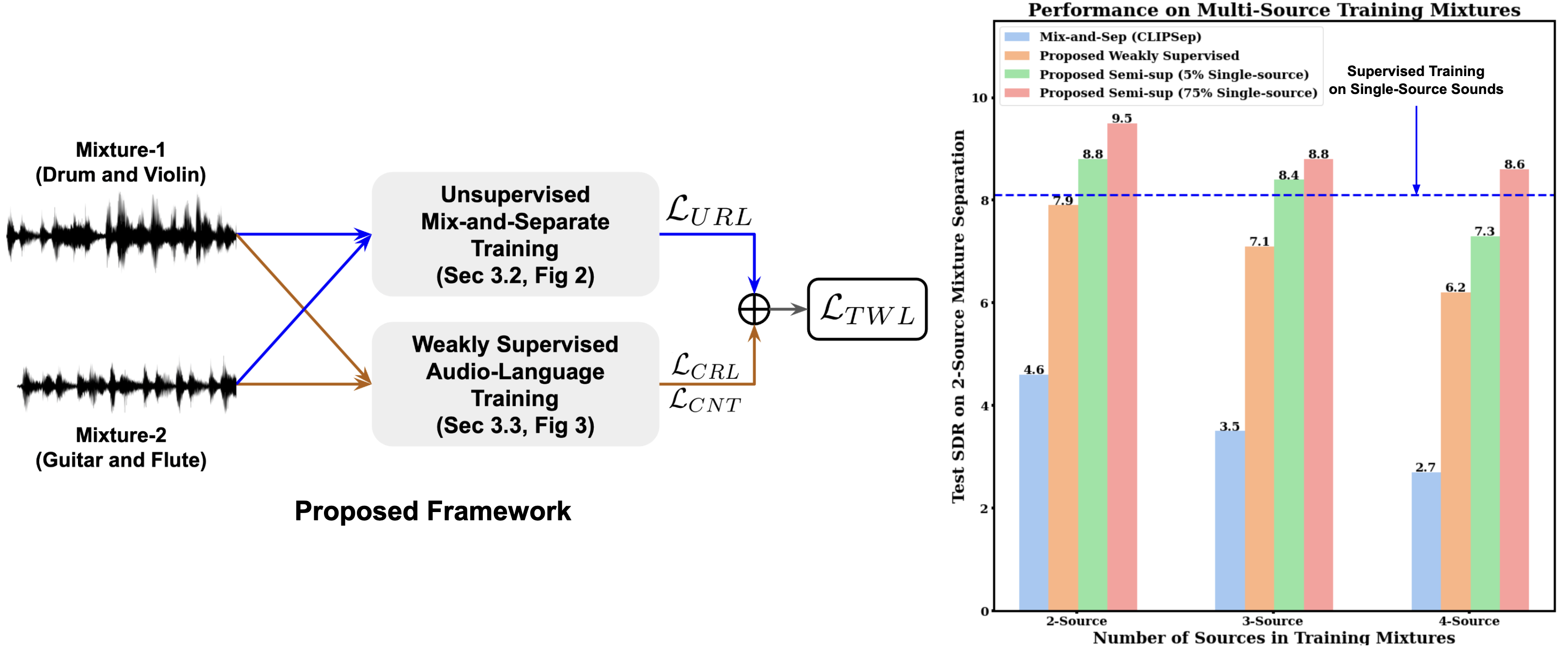
0
Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
Tanvir Mahmud, Saeed Amizadeh, Kazuhito Koishida, Diana Marculescu
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Read more4/3/2024