Unsupervised Distractor Generation via Large Language Model Distilling and Counterfactual Contrastive Decoding

0

Sign in to get full access
Overview
- This paper introduces an approach for generating distractors (incorrect answer choices) for multiple-choice questions in an unsupervised manner.
- The method involves distilling a large language model to capture the semantic knowledge, then using counterfactual contrastive decoding to generate diverse and relevant distractors.
- The authors demonstrate the effectiveness of their approach on several benchmarks, showing that it outperforms existing distractor generation techniques.
Plain English Explanation
The goal of this research is to develop a way to automatically generate incorrect answer choices, known as "distractors," for multiple-choice questions. This is a useful task for creating educational assessments, where you need to provide several answer options, only one of which is correct.
The key insight of this work is to leverage the vast knowledge captured in large language models, like GPT-3, to inform the distractor generation process. First, the researchers "distill" this knowledge into a smaller, more focused model. This allows them to efficiently harness the model's semantic understanding without the overhead of the full-size version.
Next, they use a technique called "counterfactual contrastive decoding" to generate the distractors. This means the model considers the correct answer and then deliberately tries to produce incorrect alternatives that are still plausible and relevant to the question. The result is a set of distractors that are convincing and challenging for the test-taker, without requiring any labeled training data.
The authors show that their unsupervised approach outperforms previous methods for distractor generation across several benchmarks. This suggests it could be a valuable tool for streamlining the development of high-quality multiple-choice assessments.
Technical Explanation
The paper presents an unsupervised distractor generation framework that leverages large language models and counterfactual contrastive decoding.
First, the authors distill a pre-trained language model, such as GPT-3, into a smaller, more efficient model that retains the original's semantic knowledge. This distilled model serves as the foundation for the distractor generation process.
Next, they employ counterfactual contrastive decoding, which involves generating distractors that are semantically relevant to the question but distinctly different from the correct answer. This is achieved by conditioning the language model on the correct answer and then using a decoding strategy that actively seeks out plausible but incorrect alternatives.
The authors evaluate their approach, which they call DGRC, on several benchmark datasets for distractor generation. They show that DGRC outperforms existing automated distractor generation methods in terms of the quality and diversity of the generated distractors.
Critical Analysis
The paper presents a promising approach for unsupervised distractor generation, but it also acknowledges some limitations. The authors note that the performance of their method may be sensitive to the quality and domain of the pre-trained language model used for distillation. Additionally, the counterfactual contrastive decoding strategy relies on the assumption that the correct answer is known, which may not always be the case in real-world scenarios.
Further research could explore ways to generalize the approach to handle situations where the correct answer is not provided, or to incorporate additional signals (e.g., question context, domain knowledge) to enhance the relevance and coherence of the generated distractors.
Conclusion
This paper presents a novel unsupervised approach for generating distractors for multiple-choice questions. By leveraging the knowledge of large language models and using counterfactual contrastive decoding, the authors demonstrate a way to automatically create high-quality distractors without the need for labeled training data.
The proposed method outperforms existing distractor generation techniques, suggesting it could be a valuable tool for streamlining the development of educational assessments and other applications that require multiple-choice questions. While the approach has some limitations, the paper's contributions represent an important step forward in the field of automated distractor generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Distractor Generation via Large Language Model Distilling and Counterfactual Contrastive Decoding
Fanyi Qu, Hao Sun, Yunfang Wu
Within the context of reading comprehension, the task of Distractor Generation (DG) aims to generate several incorrect options to confuse readers. Traditional supervised methods for DG rely heavily on expensive human-annotated distractor labels. In this paper, we propose an unsupervised DG framework, leveraging Large Language Models (LLMs) as cost-effective annotators to enhance the DG capability of smaller student models. Specially, to perform knowledge distilling, we propose a dual task training strategy that integrates pseudo distractors from LLMs and the original answer in-formation as the objective targets with a two-stage training process. Moreover, we devise a counterfactual contrastive decoding mechanism for increasing the distracting capability of the DG model. Experiments show that our unsupervised generation method with Bart-base greatly surpasses GPT-3.5-turbo performance with only 200 times fewer model parameters. Our proposed unsupervised DG method offers a cost-effective framework for practical reading comprehension applications, without the need of laborious distractor annotation and costly large-size models
Read more6/4/2024
🛸
0
New!DisGeM: Distractor Generation for Multiple Choice Questions with Span Masking
Devrim Cavusoglu, Secil Sen, Ulas Sert
Recent advancements in Natural Language Processing (NLP) have impacted numerous sub-fields such as natural language generation, natural language inference, question answering, and more. However, in the field of question generation, the creation of distractors for multiple-choice questions (MCQ) remains a challenging task. In this work, we present a simple, generic framework for distractor generation using readily available Pre-trained Language Models (PLMs). Unlike previous methods, our framework relies solely on pre-trained language models and does not require additional training on specific datasets. Building upon previous research, we introduce a two-stage framework consisting of candidate generation and candidate selection. Our proposed distractor generation framework outperforms previous methods without the need for training or fine-tuning. Human evaluations confirm that our approach produces more effective and engaging distractors. The related codebase is publicly available at https://github.com/obss/disgem.
Read more9/30/2024

0
DGRC: An Effective Fine-tuning Framework for Distractor Generation in Chinese Multi-choice Reading Comprehension
Runfeng Lin, Dacheng Xu, Huijiang Wang, Zebiao Chen, Yating Wang, Shouqiang Liu
When evaluating a learner's knowledge proficiency, the multiple-choice question is an efficient and widely used format in standardized tests. Nevertheless, generating these questions, particularly plausible distractors (incorrect options), poses a considerable challenge. Generally, the distractor generation can be classified into cloze-style distractor generation (CDG) and natural questions distractor generation (NQDG). In contrast to the CDG, utilizing pre-trained language models (PLMs) for NQDG presents three primary challenges: (1) PLMs are typically trained to generate ``correct'' content, like answers, while rarely trained to generate ``plausible content, like distractors; (2) PLMs often struggle to produce content that aligns well with specific knowledge and the style of exams; (3) NQDG necessitates the model to produce longer, context-sensitive, and question-relevant distractors. In this study, we introduce a fine-tuning framework named DGRC for NQDG in Chinese multi-choice reading comprehension from authentic examinations. DGRC comprises three major components: hard chain-of-thought, multi-task learning, and generation mask patterns. The experiment results demonstrate that DGRC significantly enhances generation performance, achieving a more than 2.5-fold improvement in BLEU scores.
Read more5/30/2024
0
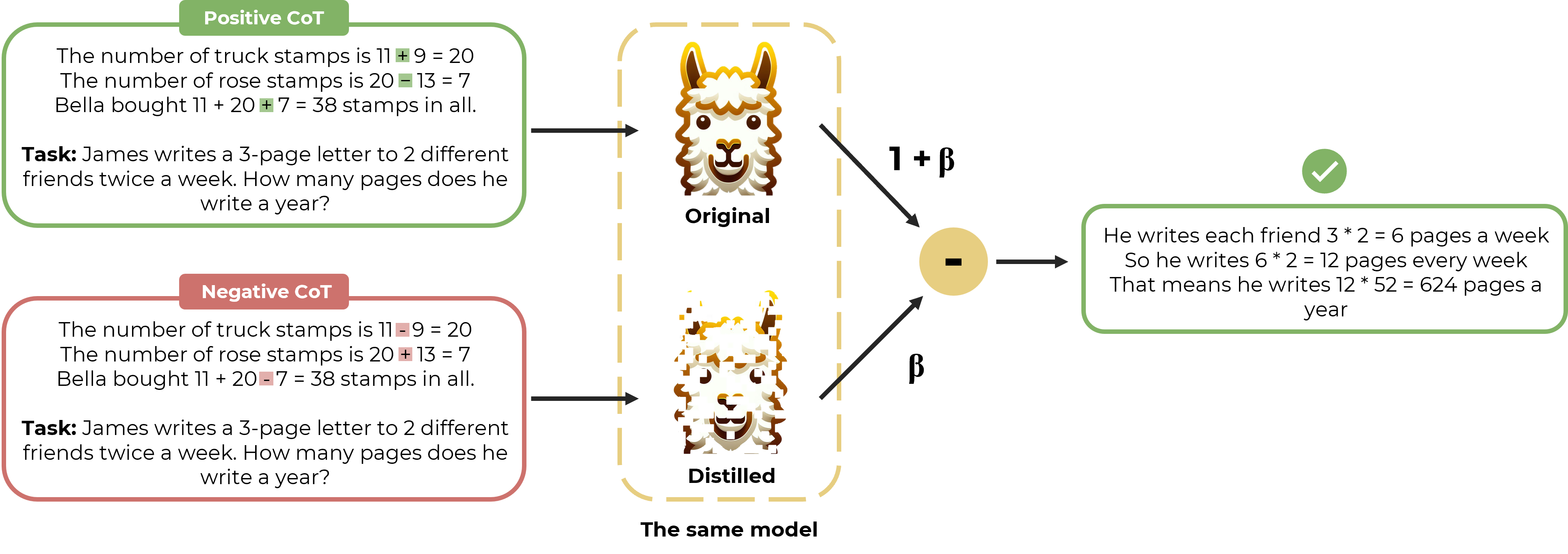
Distillation Contrastive Decoding: Improving LLMs Reasoning with Contrastive Decoding and Distillation
Phuc Phan, Hieu Tran, Long Phan
We propose a straightforward approach called Distillation Contrastive Decoding (DCD) to enhance the reasoning capabilities of Large Language Models (LLMs) during inference. In contrast to previous approaches that relied on smaller amateur models or analysis of hidden state differences, DCD employs Contrastive Chain-of-thought Prompting and advanced distillation techniques, including Dropout and Quantization. This approach effectively addresses the limitations of Contrastive Decoding (CD), which typically requires both an expert and an amateur model, thus increasing computational resource demands. By integrating contrastive prompts with distillation, DCD obviates the need for an amateur model and reduces memory usage. Our evaluations demonstrate that DCD significantly enhances LLM performance across a range of reasoning benchmarks, surpassing both CD and existing methods in the GSM8K and StrategyQA datasets.
Read more8/26/2024