Distillation Contrastive Decoding: Improving LLMs Reasoning with Contrastive Decoding and Distillation

0
Sign in to get full access
Overview
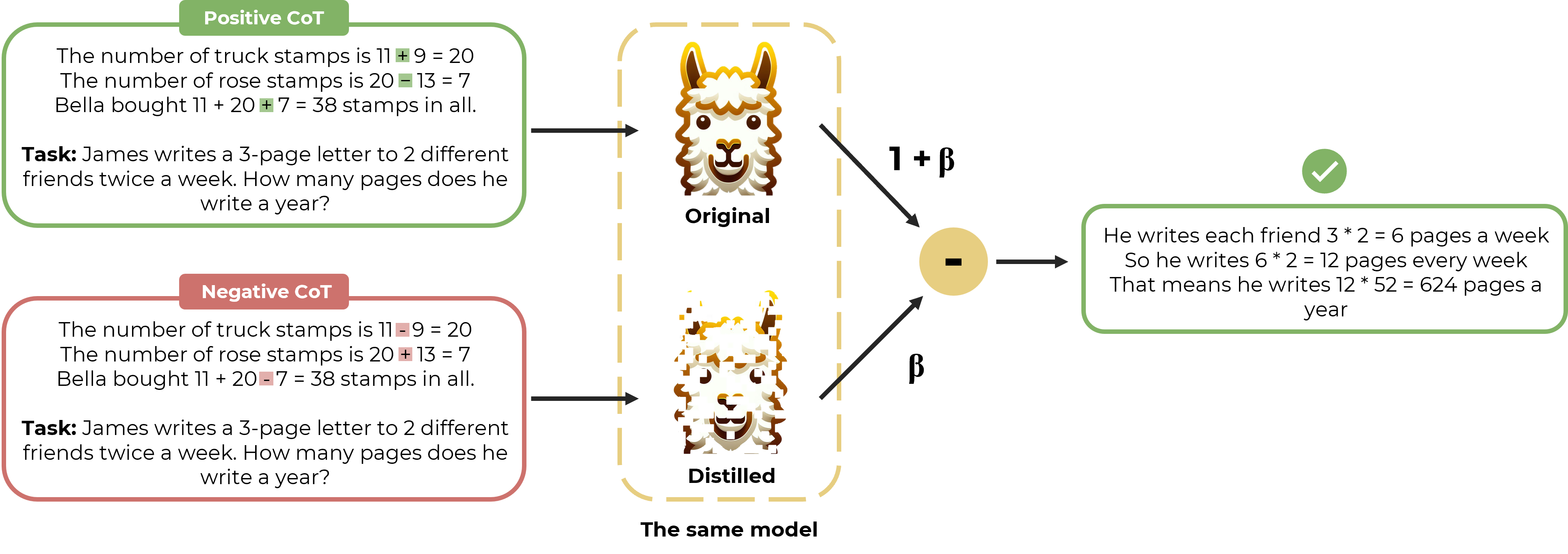
- Distillation Contrastive Decoding (DCD) is a technique that aims to improve the reasoning and generalization capabilities of large language models (LLMs).
- It combines contrastive decoding, which encourages models to generate outputs that are distinct from distractors, with knowledge distillation, which transfers knowledge from a larger teacher model to a smaller student model.
- The goal is to enable LLMs to generate more coherent and grounded responses, particularly for tasks that require complex reasoning.
Plain English Explanation
Distillation Contrastive Decoding is a technique that aims to make large language models (LLMs) better at reasoning and coming up with more relevant, grounded responses. It does this by combining two approaches:
-
Contrastive Decoding: This encourages the model to generate outputs that are distinct from "distractors" - responses that might seem plausible at first glance, but are actually incorrect or irrelevant. The model learns to avoid generating these kinds of unhelpful responses.
-
Knowledge Distillation: This transfers knowledge from a larger, more capable "teacher" model to a smaller "student" model. The student model can then produce responses that are more coherent and grounded in the way the teacher model does.
By using these two techniques together, the goal is to enable LLMs to generate more thoughtful, well-reasoned responses, particularly for tasks that require complex reasoning and problem-solving. This could be useful in a wide range of applications, from question-answering to task completion to open-ended conversation.
Technical Explanation
Distillation Contrastive Decoding is a novel approach that combines contrastive decoding and knowledge distillation to improve the reasoning and generalization capabilities of large language models (LLMs).
In contrastive decoding, the model is trained to generate outputs that are distinct from a set of "distractors" - plausible but incorrect responses. This encourages the model to avoid generating unhelpful outputs and instead focus on more coherent and grounded responses.
Knowledge distillation, on the other hand, transfers knowledge from a larger "teacher" model to a smaller "student" model. The student model can then leverage the reasoning and generalization abilities of the teacher to produce more insightful outputs.
By combining these two techniques, Distillation Contrastive Decoding aims to enable LLMs to generate responses that are both distinct from distractors and aligned with the reasoning of a more capable teacher model. This can be particularly beneficial for tasks that require complex reasoning, such as question-answering, task completion, and open-ended conversation.
Critical Analysis
The Distillation Contrastive Decoding approach presents a promising way to improve the reasoning and generalization capabilities of LLMs. However, the paper does not address several potential limitations and areas for further research:
-
Scalability: The effectiveness of the approach may depend on the availability of a large, high-quality set of distractors. Generating these distractors automatically at scale could be a significant challenge.
-
Bias and Fairness: The distillation process from the teacher model could potentially transfer any biases or limitations present in the teacher model to the student model, which may impact the fairness and inclusiveness of the generated outputs.
-
Interpretability: The paper does not discuss the interpretability of the Distillation Contrastive Decoding approach. It would be important to understand how the model arrives at its reasoning, particularly for critical applications.
-
Empirical Validation: While the paper presents promising results on specific tasks, more comprehensive evaluation across a wider range of benchmarks and real-world applications would be necessary to fully assess the approach's efficacy and generalizability.
Overall, the Distillation Contrastive Decoding technique shows promise, but further research and validation would be needed to address these potential limitations and ensure the approach is robust and beneficial for a wide range of LLM applications.
Conclusion
Distillation Contrastive Decoding is a novel technique that aims to improve the reasoning and generalization capabilities of large language models by combining contrastive decoding and knowledge distillation.
The key idea is to enable LLMs to generate more coherent and grounded responses, particularly for tasks that require complex reasoning, by encouraging the model to avoid unhelpful "distractors" and leverage the reasoning abilities of a more capable teacher model.
While the approach shows promise, there are several potential limitations and areas for further research, such as scalability, bias and fairness, interpretability, and more comprehensive empirical validation. Addressing these challenges could help unlock the full potential of Distillation Contrastive Decoding and further advance the state of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distillation Contrastive Decoding: Improving LLMs Reasoning with Contrastive Decoding and Distillation
Phuc Phan, Hieu Tran, Long Phan
We propose a straightforward approach called Distillation Contrastive Decoding (DCD) to enhance the reasoning capabilities of Large Language Models (LLMs) during inference. In contrast to previous approaches that relied on smaller amateur models or analysis of hidden state differences, DCD employs Contrastive Chain-of-thought Prompting and advanced distillation techniques, including Dropout and Quantization. This approach effectively addresses the limitations of Contrastive Decoding (CD), which typically requires both an expert and an amateur model, thus increasing computational resource demands. By integrating contrastive prompts with distillation, DCD obviates the need for an amateur model and reduces memory usage. Our evaluations demonstrate that DCD significantly enhances LLM performance across a range of reasoning benchmarks, surpassing both CD and existing methods in the GSM8K and StrategyQA datasets.
Read more8/26/2024
💬
0
QCRD: Quality-guided Contrastive Rationale Distillation for Large Language Models
Wei Wang, Zhaowei Li, Qi Xu, Yiqing Cai, Hang Song, Qi Qi, Ran Zhou, Zhida Huang, Tao Wang, Li Xiao
The deployment of large language models (LLMs) faces considerable challenges concerning resource constraints and inference efficiency. Recent research has increasingly focused on smaller, task-specific models enhanced by distilling knowledge from LLMs. However, prior studies have often overlooked the diversity and quality of knowledge, especially the untapped potential of negative knowledge. Constructing effective negative knowledge remains severely understudied. In this paper, we introduce a novel framework called quality-guided contrastive rationale distillation aimed at enhancing reasoning capabilities through contrastive knowledge learning. For positive knowledge, we enrich its diversity through temperature sampling and employ self-consistency for further denoising and refinement. For negative knowledge, we propose an innovative self-adversarial approach that generates low-quality rationales by sampling previous iterations of smaller language models, embracing the idea that one can learn from one's own weaknesses. A contrastive loss is developed to distill both positive and negative knowledge into smaller language models, where an online-updating discriminator is integrated to assess qualities of rationales and assign them appropriate weights, optimizing the training process. Through extensive experiments across multiple reasoning tasks, we demonstrate that our method consistently outperforms existing distillation techniques, yielding higher-quality rationales.
Read more9/20/2024

0
On the Theory of Cross-Modality Distillation with Contrastive Learning
Hangyu Lin, Chen Liu, Chengming Xu, Zhengqi Gao, Yanwei Fu, Yuan Yao
Cross-modality distillation arises as an important topic for data modalities containing limited knowledge such as depth maps and high-quality sketches. Such techniques are of great importance, especially for memory and privacy-restricted scenarios where labeled training data is generally unavailable. To solve the problem, existing label-free methods leverage a few pairwise unlabeled data to distill the knowledge by aligning features or statistics between the source and target modalities. For instance, one typically aims to minimize the L2 distance or contrastive loss between the learned features of pairs of samples in the source (e.g. image) and the target (e.g. sketch) modalities. However, most algorithms in this domain only focus on the experimental results but lack theoretical insight. To bridge the gap between the theory and practical method of cross-modality distillation, we first formulate a general framework of cross-modality contrastive distillation (CMCD), built upon contrastive learning that leverages both positive and negative correspondence, towards a better distillation of generalizable features. Furthermore, we establish a thorough convergence analysis that reveals that the distance between source and target modalities significantly impacts the test error on downstream tasks within the target modality which is also validated by the empirical results. Extensive experimental results show that our algorithm outperforms existing algorithms consistently by a margin of 2-3% across diverse modalities and tasks, covering modalities of image, sketch, depth map, and audio and tasks of recognition and segmentation.
Read more5/29/2024

0
Unsupervised Distractor Generation via Large Language Model Distilling and Counterfactual Contrastive Decoding
Fanyi Qu, Hao Sun, Yunfang Wu
Within the context of reading comprehension, the task of Distractor Generation (DG) aims to generate several incorrect options to confuse readers. Traditional supervised methods for DG rely heavily on expensive human-annotated distractor labels. In this paper, we propose an unsupervised DG framework, leveraging Large Language Models (LLMs) as cost-effective annotators to enhance the DG capability of smaller student models. Specially, to perform knowledge distilling, we propose a dual task training strategy that integrates pseudo distractors from LLMs and the original answer in-formation as the objective targets with a two-stage training process. Moreover, we devise a counterfactual contrastive decoding mechanism for increasing the distracting capability of the DG model. Experiments show that our unsupervised generation method with Bart-base greatly surpasses GPT-3.5-turbo performance with only 200 times fewer model parameters. Our proposed unsupervised DG method offers a cost-effective framework for practical reading comprehension applications, without the need of laborious distractor annotation and costly large-size models
Read more6/4/2024