Unsupervised domain adaptation by learning using privileged information

0
🤷
Sign in to get full access
Overview
- This paper explores the problem of unsupervised domain adaptation, where the goal is to transfer knowledge from a source domain to a target domain without labeled data in the target domain.
- The authors show that access to auxiliary variables (or "privileged information") during training can help relax the assumptions required for successful domain adaptation, particularly in high-dimensional applications like image classification.
- The paper proposes a two-stage learning algorithm and an end-to-end variant to leverage this privileged information for improved domain adaptation performance.
- The authors evaluate their approach on three tasks: classifying entities in photos and detecting anomalies in medical images, using different types of privileged information.
Plain English Explanation
Domain adaptation is the process of taking what a machine learning model has learned on one dataset (the "source" domain) and applying it to a different dataset (the "target" domain). This is a valuable technique, as it can allow models to be deployed in new settings without having to collect and label a large amount of new training data.
However, successful domain adaptation is challenging and typically requires strong assumptions, such as the data distributions in the two domains being similar (known as the "covariate shift" assumption) or the two domains having significant overlap. These assumptions are often violated, particularly in high-dimensional applications like image classification.
This paper proposes a new approach that can relax these assumptions by leveraging additional information that is available during the training phase, but not during deployment. The authors call this "unsupervised domain adaptation by learning using privileged information" (DALUPI).
The key idea is that if the training data includes auxiliary variables or "privileged information" (e.g., additional annotations or metadata about the images), this can help the model learn a more robust representation that transfers better to the target domain. [See other papers on domain adaptation for more context: Achieving Reliable Fair Skin Lesion Diagnosis via Unsupervised Domain Adaptation, Overcoming Negative Transfer by Online Selection of Distant Source Domains, Style Adaptation for Semantic Segmentation via Orthogonal Projection, Uncertainty-Guided Open Set Source-Free Unsupervised Domain Adaptation, GAN Inversion for Image Editing via Unsupervised Domain Disentanglement]
The authors demonstrate the effectiveness of their approach on several tasks, showing that it can improve domain adaptation performance, make models more robust to spurious correlations in the source domain, and improve sample efficiency.
Technical Explanation
The paper proposes a framework called "unsupervised domain adaptation by learning using privileged information" (DALUPI), where the training data includes auxiliary variables or "privileged information" that is not available during deployment.
The authors first provide an analysis of the expected error in the target domain, which shows that access to this privileged information can help relax the assumptions required for successful domain adaptation.
They then propose a two-stage learning algorithm inspired by this analysis. The first stage learns a representation using the privileged information, and the second stage fine-tunes this representation on the source domain data. The authors also present a practical end-to-end variant of this algorithm for image classification tasks.
The paper evaluates the proposed approach on three tasks: classifying entities in photos and detecting anomalies in medical images. The privileged information used includes binary attributes and single or multiple regions of interest.
The results demonstrate that leveraging privileged information can reduce errors in domain transfer compared to baseline methods, improve robustness to spurious correlations in the source domain, and increase sample efficiency.
Critical Analysis
The paper makes an important contribution by showing how access to auxiliary variables or "privileged information" during training can help relax the restrictive assumptions typically required for successful unsupervised domain adaptation.
However, the authors acknowledge that the availability of such privileged information may not always be the case in practice. The paper also does not explore the sensitivity of the proposed approach to the quality or type of privileged information available.
Furthermore, the evaluation is limited to a few specific tasks and datasets. It would be valuable to see how the approach generalizes to a wider range of domain adaptation scenarios, particularly in real-world applications.
Another potential limitation is that the paper does not provide a comprehensive comparison to other state-of-the-art domain adaptation methods. Exploring the relative strengths and weaknesses of the DALUPI approach compared to other techniques would help contextualize the contributions.
Overall, the paper presents a promising direction for improving unsupervised domain adaptation, but further research is needed to fully understand the capabilities and limitations of the proposed framework.
Conclusion
This paper introduces a novel approach called "unsupervised domain adaptation by learning using privileged information" (DALUPI) that can help relax the restrictive assumptions typically required for successful domain adaptation.
By leveraging auxiliary variables or "privileged information" available during the training phase, the DALUPI framework can learn more robust representations that transfer better to the target domain. The authors demonstrate the effectiveness of their approach on several image classification tasks, showing improvements in domain adaptation performance, robustness to spurious correlations, and sample efficiency.
The key insight of the paper is that access to additional information during training, even if not available at deployment, can be a valuable resource for improving unsupervised domain adaptation. This work opens up new directions for research in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
0
Unsupervised domain adaptation by learning using privileged information
Adam Breitholtz, Anton Matsson, Fredrik D. Johansson
Successful unsupervised domain adaptation is guaranteed only under strong assumptions such as covariate shift and overlap between input domains. The latter is often violated in high-dimensional applications like image classification which, despite this limitation, continues to serve as inspiration and benchmark for algorithm development. In this work, we show that training-time access to side information in the form of auxiliary variables can help relax restrictions on input variables and increase the sample efficiency of learning at the cost of collecting a richer variable set. As this information is assumed available only during training, not in deployment, we call this problem unsupervised domain adaptation by learning using privileged information (DALUPI). To solve this problem, we propose a simple two-stage learning algorithm, inspired by our analysis of the expected error in the target domain, and a practical end-to-end variant for image classification. We propose three evaluation tasks based on classification of entities in photos and anomalies in medical images with different types of available privileged information (binary attributes and single or multiple regions of interest). We demonstrate across these tasks that using privileged information in learning can reduce errors in domain transfer compared to baselines, be robust to spurious correlations in the source domain, and increase sample efficiency.
Read more6/13/2024

0
Learning to Discover Knowledge: A Weakly-Supervised Partial Domain Adaptation Approach
Mengcheng Lan, Min Meng, Jun Yu, Jigang Wu
Domain adaptation has shown appealing performance by leveraging knowledge from a source domain with rich annotations. However, for a specific target task, it is cumbersome to collect related and high-quality source domains. In real-world scenarios, large-scale datasets corrupted with noisy labels are easy to collect, stimulating a great demand for automatic recognition in a generalized setting, i.e., weakly-supervised partial domain adaptation (WS-PDA), which transfers a classifier from a large source domain with noises in labels to a small unlabeled target domain. As such, the key issues of WS-PDA are: 1) how to sufficiently discover the knowledge from the noisy labeled source domain and the unlabeled target domain, and 2) how to successfully adapt the knowledge across domains. In this paper, we propose a simple yet effective domain adaptation approach, termed as self-paced transfer classifier learning (SP-TCL), to address the above issues, which could be regarded as a well-performing baseline for several generalized domain adaptation tasks. The proposed model is established upon the self-paced learning scheme, seeking a preferable classifier for the target domain. Specifically, SP-TCL learns to discover faithful knowledge via a carefully designed prudent loss function and simultaneously adapts the learned knowledge to the target domain by iteratively excluding source examples from training under the self-paced fashion. Extensive evaluations on several benchmark datasets demonstrate that SP-TCL significantly outperforms state-of-the-art approaches on several generalized domain adaptation tasks.
Read more6/21/2024

0
Overcoming Negative Transfer by Online Selection: Distant Domain Adaptation for Fault Diagnosis
Ziyan Wang, Mohamed Ragab, Wenmian Yang, Min Wu, Sinno Jialin Pan, Jie Zhang, Zhenghua Chen
Unsupervised domain adaptation (UDA) has achieved remarkable success in fault diagnosis, bringing significant benefits to diverse industrial applications. While most UDA methods focus on cross-working condition scenarios where the source and target domains are notably similar, real-world applications often grapple with severe domain shifts. We coin the term `distant domain adaptation problem' to describe the challenge of adapting from a labeled source domain to a significantly disparate unlabeled target domain. This problem exhibits the risk of negative transfer, where extraneous knowledge from the source domain adversely affects the target domain performance. Unfortunately, conventional UDA methods often falter in mitigating this negative transfer, leading to suboptimal performance. In response to this challenge, we propose a novel Online Selective Adversarial Alignment (OSAA) approach. Central to OSAA is its ability to dynamically identify and exclude distant source samples via an online gradient masking approach, focusing primarily on source samples that closely resemble the target samples. Furthermore, recognizing the inherent complexities in bridging the source and target domains, we construct an intermediate domain to act as a transitional domain and ease the adaptation process. Lastly, we develop a class-conditional adversarial adaptation to address the label distribution disparities while learning domain invariant representation to account for potential label distribution disparities between the domains. Through detailed experiments and ablation studies on two real-world datasets, we validate the superior performance of the OSAA method over state-of-the-art methods, underscoring its significant utility in practical scenarios with severe domain shifts.
Read more5/29/2024
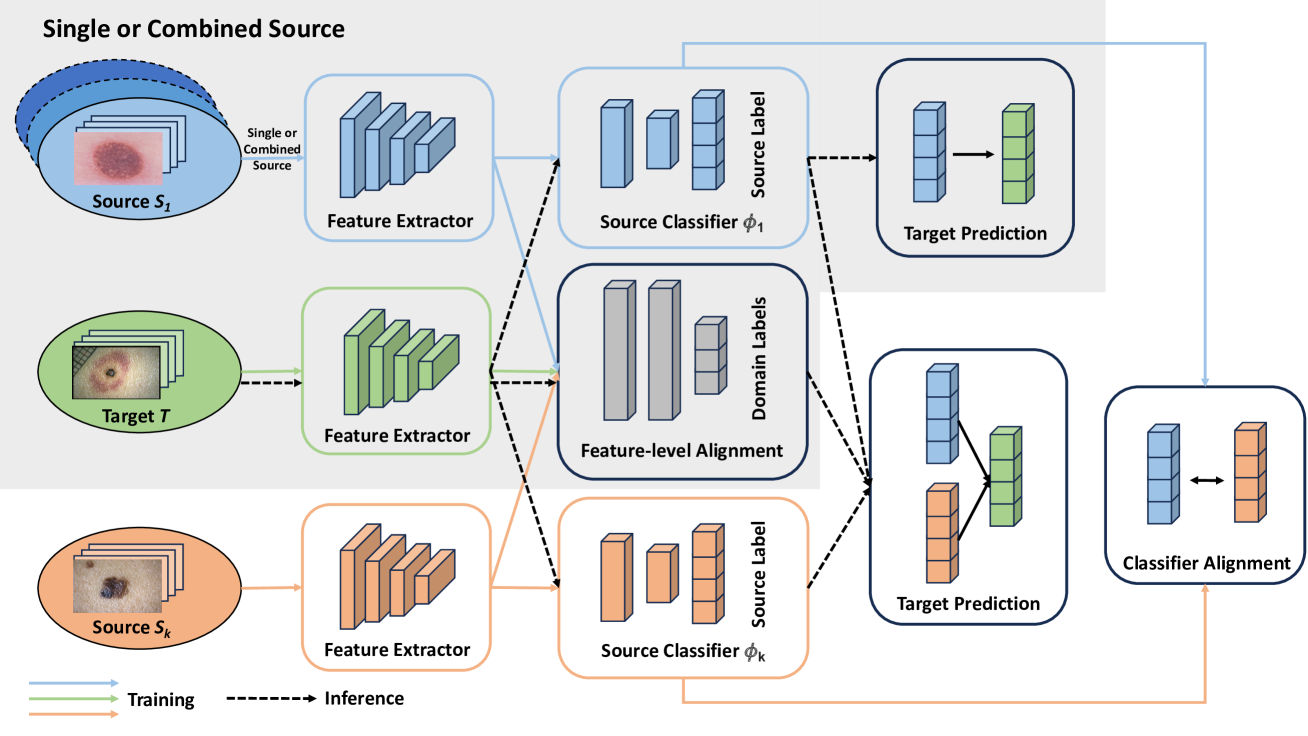
0
Achieving Reliable and Fair Skin Lesion Diagnosis via Unsupervised Domain Adaptation
Janet Wang, Yunbei Zhang, Zhengming Ding, Jihun Hamm
The development of reliable and fair diagnostic systems is often constrained by the scarcity of labeled data. To address this challenge, our work explores the feasibility of unsupervised domain adaptation (UDA) to integrate large external datasets for developing reliable classifiers. The adoption of UDA with multiple sources can simultaneously enrich the training set and bridge the domain gap between different skin lesion datasets, which vary due to distinct acquisition protocols. Particularly, UDA shows practical promise for improving diagnostic reliability when training with a custom skin lesion dataset, where only limited labeled data are available from the target domain. In this study, we investigate three UDA training schemes based on source data utilization: single-source, combined-source, and multi-source UDA. Our findings demonstrate the effectiveness of applying UDA on multiple sources for binary and multi-class classification. A strong correlation between test error and label shift in multi-class tasks has been observed in the experiment. Crucially, our study shows that UDA can effectively mitigate bias against minority groups and enhance fairness in diagnostic systems, while maintaining superior classification performance. This is achieved even without directly implementing fairness-focused techniques. This success is potentially attributed to the increased and well-adapted demographic information obtained from multiple sources.
Read more4/17/2024