Unveiling Factual Recall Behaviors of Large Language Models through Knowledge Neurons

0

Sign in to get full access
Overview
- This paper investigates how large language models (LLMs) recall factual information.
- The researchers identify "knowledge neurons" - specific neurons in the model that encode factual knowledge.
- They analyze how these knowledge neurons are activated during factual recall tasks to unveil the inner workings of LLMs.
Plain English Explanation
The paper examines how powerful language models, known as large language models (LLMs), are able to recall and use factual information. LLMs are AI systems that can generate human-like text, but it's not always clear how they access and retrieve the knowledge they've been trained on.
The researchers in this study identify certain "knowledge neurons" - specific neurons or processing units within the LLM that seem to encode factual information. By analyzing how these knowledge neurons are activated when the model is asked factual questions, the researchers can better understand the mechanisms behind the model's factual recall abilities.
This provides insights into the inner workings of LLMs and how they store and retrieve knowledge, which could lead to improvements in the models' reasoning and knowledge capabilities.
Technical Explanation
The paper first establishes some background on large language models (LLMs) and their ability to store and recall factual knowledge. The researchers then introduce the concept of "knowledge neurons" - specific neurons or processing units within the LLM architecture that seem to be responsible for encoding factual information.
To investigate these knowledge neurons, the researchers design a series of experiments where they prompt the LLM with questions that require factual recall. By analyzing the activation patterns of the model's neurons during these tasks, they're able to identify the specific neurons that are most strongly associated with retrieving the relevant factual knowledge.
The experiments reveal several key insights about how LLMs process and recall factual information. For example, the researchers find that the knowledge neurons exhibit distinct activation patterns depending on the type of factual information being recalled, suggesting a structured organization of knowledge within the model.
Additionally, the researchers observe that the knowledge neurons can be selectively activated or deactivated, allowing the model to flexibly retrieve different types of facts as needed. This provides evidence for the models' ability to dynamically access their stored knowledge, rather than simply retrieving pre-formed responses.
Overall, the findings offer a glimpse into the inner workings of LLMs and how they leverage their vast knowledge bases to answer factual queries. This understanding could inform the development of more capable and transparent AI systems in the future.
Critical Analysis
The paper presents a compelling and in-depth investigation of LLM behavior, but it's important to consider some potential limitations and areas for further research.
One key limitation is the specific LLM architecture and training data used in the experiments. The findings may not generalize to all LLMs, as their knowledge representations and recall mechanisms could vary depending on the model design and training process.
Additionally, the paper focuses on factual recall, but LLMs are increasingly being used for more complex reasoning and language tasks. Further research is needed to understand how the identified knowledge neurons might interact with other cognitive processes within the models.
Another potential area for exploration is the interpretability and transparency of the knowledge neurons. While the paper provides insights into their activation patterns, more work is needed to fully understand how they encode and represent factual information in a way that is accessible to human users.
Despite these limitations, the paper offers a valuable contribution to the ongoing effort to unveil the inner workings of large language models. The findings could inform the development of more robust and trustworthy AI systems that can reliably access and apply their factual knowledge.
Conclusion
This paper takes an important step towards understanding the factual recall behaviors of large language models by identifying and analyzing the "knowledge neurons" that encode and retrieve factual information.
The researchers' findings provide valuable insights into the inner workings of these powerful AI systems, suggesting that LLMs have a structured and flexible way of storing and accessing their vast knowledge bases. This understanding could lead to advancements in the development of more capable and transparent language models, with potential applications in fields like education, knowledge-intensive tasks, and human-AI interaction.
While further research is needed to fully explore the scope and limitations of these findings, this paper represents a significant contribution to the ongoing effort to unveil the black box of large language models and harness their impressive capabilities for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling Factual Recall Behaviors of Large Language Models through Knowledge Neurons
Yifei Wang, Yuheng Chen, Wanting Wen, Yu Sheng, Linjing Li, Daniel Dajun Zeng
In this paper, we investigate whether Large Language Models (LLMs) actively recall or retrieve their internal repositories of factual knowledge when faced with reasoning tasks. Through an analysis of LLMs' internal factual recall at each reasoning step via Knowledge Neurons, we reveal that LLMs fail to harness the critical factual associations under certain circumstances. Instead, they tend to opt for alternative, shortcut-like pathways to answer reasoning questions. By manually manipulating the recall process of parametric knowledge in LLMs, we demonstrate that enhancing this recall process directly improves reasoning performance whereas suppressing it leads to notable degradation. Furthermore, we assess the effect of Chain-of-Thought (CoT) prompting, a powerful technique for addressing complex reasoning tasks. Our findings indicate that CoT can intensify the recall of factual knowledge by encouraging LLMs to engage in orderly and reliable reasoning. Furthermore, we explored how contextual conflicts affect the retrieval of facts during the reasoning process to gain a comprehensive understanding of the factual recall behaviors of LLMs. Code and data will be available soon.
Read more8/14/2024
🧠
0
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Jiaqing Yuan, Lin Pan, Chung-Wei Hang, Jiang Guo, Jiarong Jiang, Bonan Min, Patrick Ng, Zhiguo Wang
Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
Read more4/26/2024

0
CLR-Fact: Evaluating the Complex Logical Reasoning Capability of Large Language Models over Factual Knowledge
Tianshi Zheng, Jiaxin Bai, Yicheng Wang, Tianqing Fang, Yue Guo, Yauwai Yim, Yangqiu Song
While large language models (LLMs) have demonstrated impressive capabilities across various natural language processing tasks by acquiring rich factual knowledge from their broad training data, their ability to synthesize and logically reason with this knowledge in complex ways remains underexplored. In this work, we present a systematic evaluation of state-of-the-art LLMs' complex logical reasoning abilities through a novel benchmark of automatically generated complex reasoning questions over general domain and biomedical knowledge graphs. Our extensive experiments, employing diverse in-context learning techniques, reveal that LLMs excel at reasoning over general world knowledge but face significant challenges with specialized domain-specific knowledge. We find that prompting with explicit Chain-of-Thought demonstrations can substantially improve LLM performance on complex logical reasoning tasks with diverse logical operations. Interestingly, our controlled evaluations uncover an asymmetry where LLMs display proficiency at set union operations, but struggle considerably with set intersections - a key building block of logical reasoning. To foster further work, we will publicly release our evaluation benchmark and code.
Read more7/31/2024
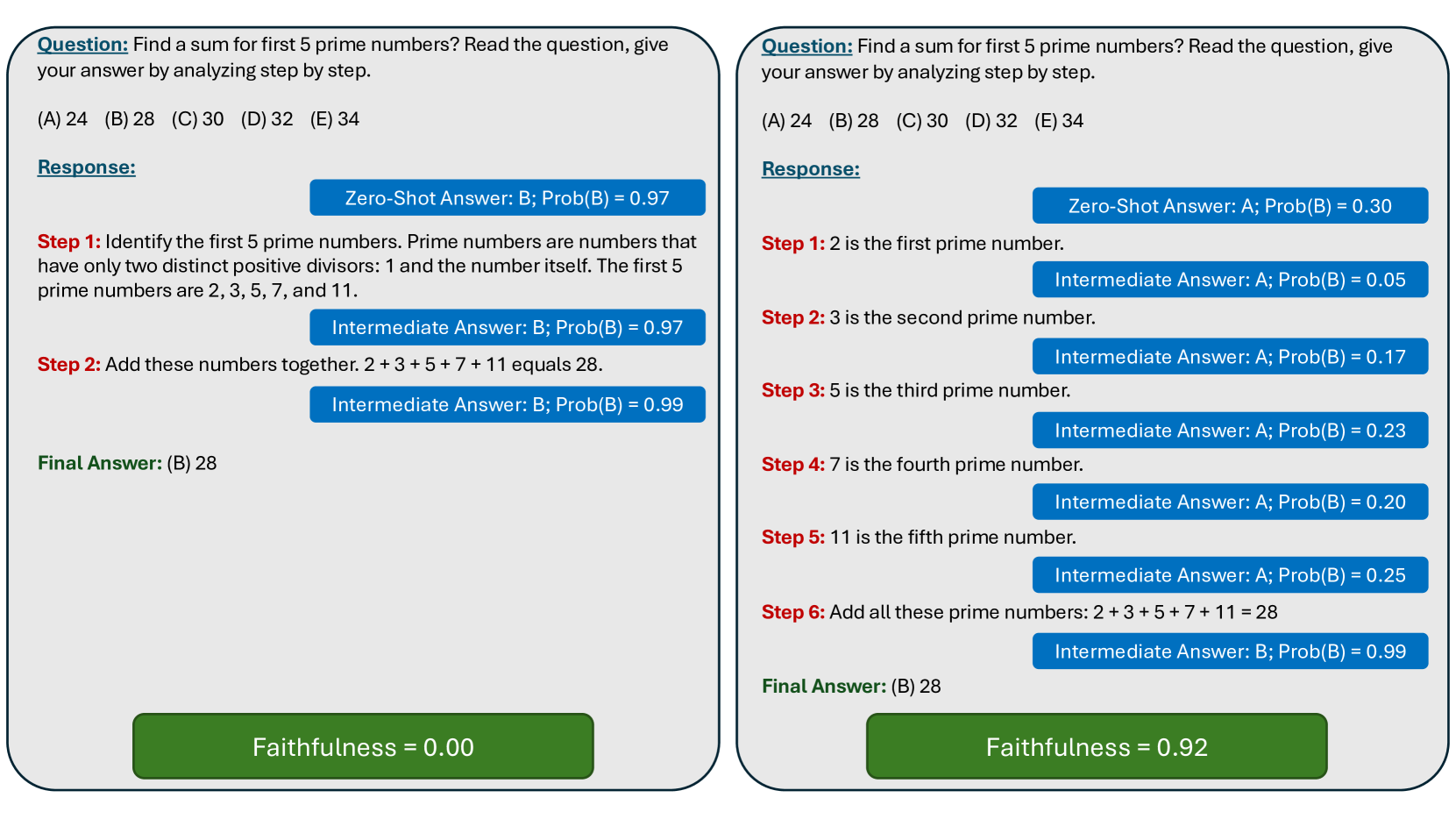
0
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, Himabindu Lakkaraju
As Large Language Models (LLMs) are increasingly being employed in real-world applications in critical domains such as healthcare, it is important to ensure that the Chain-of-Thought (CoT) reasoning generated by these models faithfully captures their underlying behavior. While LLMs are known to generate CoT reasoning that is appealing to humans, prior studies have shown that these explanations do not accurately reflect the actual behavior of the underlying LLMs. In this work, we explore the promise of three broad approaches commonly employed to steer the behavior of LLMs to enhance the faithfulness of the CoT reasoning generated by LLMs: in-context learning, fine-tuning, and activation editing. Specifically, we introduce novel strategies for in-context learning, fine-tuning, and activation editing aimed at improving the faithfulness of the CoT reasoning. We then carry out extensive empirical analyses with multiple benchmark datasets to explore the promise of these strategies. Our analyses indicate that these strategies offer limited success in improving the faithfulness of the CoT reasoning, with only slight performance enhancements in controlled scenarios. Activation editing demonstrated minimal success, while fine-tuning and in-context learning achieved marginal improvements that failed to generalize across diverse reasoning and truthful question-answering benchmarks. In summary, our work underscores the inherent difficulty in eliciting faithful CoT reasoning from LLMs, suggesting that the current array of approaches may not be sufficient to address this complex challenge.
Read more7/2/2024