Unveiling the Potential of Sentiment: Can Large Language Models Predict Chinese Stock Price Movements?
2306.14222
0
0
💬
Abstract
The rapid advancement of Large Language Models (LLMs) has spurred discussions about their potential to enhance quantitative trading strategies. LLMs excel in analyzing sentiments about listed companies from financial news, providing critical insights for trading decisions. However, the performance of LLMs in this task varies substantially due to their inherent characteristics. This paper introduces a standardized experimental procedure for comprehensive evaluations. We detail the methodology using three distinct LLMs, each embodying a unique approach to performance enhancement, applied specifically to the task of sentiment factor extraction from large volumes of Chinese news summaries. Subsequently, we develop quantitative trading strategies using these sentiment factors and conduct back-tests in realistic scenarios. Our results will offer perspectives about the performances of Large Language Models applied to extracting sentiments from Chinese news texts.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This technical paper discusses the "GPT Factor" - an approach that aims to improve the performance of large language models (LLMs) on various tasks.
- The paper explores how the GPT Factor can be used to enhance the abilities of LLMs, such as BERTopic-driven stock market predictions, beating Wall Street analysts, and deciphering political entity sentiment from news.
- The paper also mentions the development of a Chinese-centric large language model and the importance of modeling emotions and ethics in LLMs.
Plain English Explanation
The GPT Factor is a new approach that aims to improve the performance of large language models (LLMs) on a variety of tasks. LLMs are powerful AI systems that can understand and generate human-like text, and they have shown impressive capabilities in areas like stock market predictions, political analysis, and more.
The key idea behind the GPT Factor is to find ways to make LLMs even more effective by tweaking their internal structure and training process. The paper explores different techniques that could be used to enhance the abilities of LLMs, such as fine-tuning the models on specific datasets or adjusting the way they process information.
For example, the paper discusses how the GPT Factor could be used to improve the accuracy of LLM-based stock market predictions or to better understand the sentiment expressed in political news articles. The researchers also mention the development of a new Chinese-focused LLM, which could be particularly useful for applications in that language and region.
Overall, the GPT Factor represents an exciting step forward in the field of large language models, with the potential to unlock even more powerful and versatile AI systems that can tackle a wide range of real-world challenges.
Technical Explanation
The paper proposes the "GPT Factor" as a framework for improving the performance of large language models (LLMs) on various tasks. The core idea is to leverage insights from the original GPT (Generative Pretrained Transformer) model to enhance the capabilities of other LLMs, such as BERTopic-driven stock market predictions, beating Wall Street analysts, and deciphering political entity sentiment from news.
The paper explores various techniques that could be used to implement the GPT Factor, including:
- Architecture modifications: Adjusting the internal structure and configuration of LLMs to better capture relevant patterns and relationships.
- Targeted pretraining: Fine-tuning the models on specialized datasets or tasks to hone their abilities in specific domains.
- Ensemble methods: Combining the outputs of multiple LLMs or variants to leverage their complementary strengths.
The researchers also mention the development of a Chinese-centric large language model, which could be particularly useful for applications in the Chinese language and region. Additionally, the paper highlights the importance of modeling emotions and ethics in LLMs to ensure the responsible and beneficial deployment of these powerful AI systems.
Critical Analysis
The paper presents a promising approach to enhancing the capabilities of large language models, but it is important to consider some potential caveats and areas for further research:
- The specific techniques and modifications proposed in the GPT Factor may require extensive experimentation and validation to ensure they consistently improve performance across a wide range of tasks and datasets.
- The paper does not provide detailed empirical results or comparisons to state-of-the-art LLM approaches, making it difficult to assess the actual impact and advantages of the GPT Factor.
- The challenges of modeling emotions and ethics in LLMs are complex and ongoing, and the paper does not delve deeply into the specific methods or considerations for addressing these important issues.
- The development of a Chinese-centric LLM is an interesting direction, but the paper does not explore how this model might differ from or complement existing multilingual LLMs, or the unique considerations for the Chinese language and cultural context.
Overall, the GPT Factor represents an intriguing avenue for enhancing LLM capabilities, but further research and empirical validation will be necessary to fully understand its potential and limitations.
Conclusion
The GPT Factor is a promising approach that aims to improve the performance of large language models on a variety of tasks, including stock market predictions, political analysis, and more. By leveraging insights from the original GPT model and exploring various architectural modifications and training techniques, the researchers hope to unlock even greater capabilities in LLMs.
The development of a Chinese-centric LLM and the emphasis on modeling emotions and ethics are also notable aspects of this work, as they highlight the importance of tailoring these powerful AI systems to specific cultural and societal needs.
While the paper presents an interesting conceptual framework, more detailed empirical validation and exploration of the proposed methods will be crucial to fully assess the impact and practical applications of the GPT Factor. Nonetheless, this research represents an exciting step forward in the ongoing quest to harness the transformative potential of large language models for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
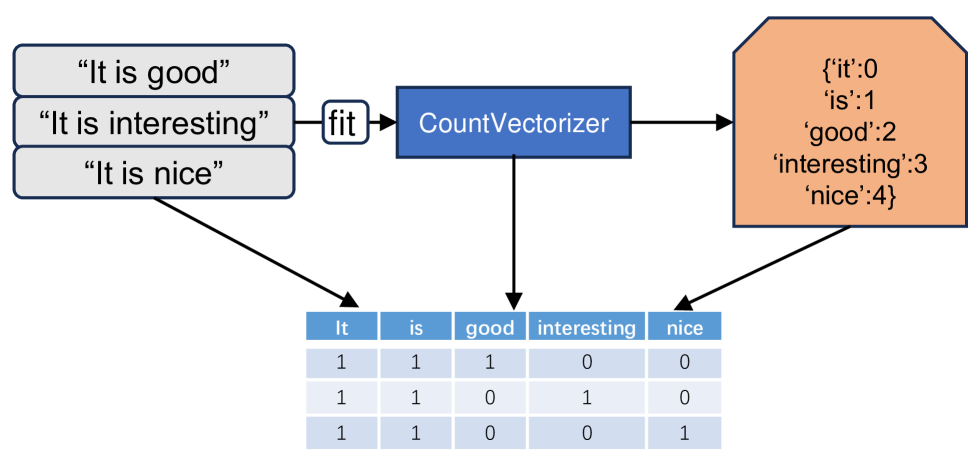
BERTopic-Driven Stock Market Predictions: Unraveling Sentiment Insights
Enmin Zhu, Jerome Yen
0
0
This paper explores the intersection of Natural Language Processing (NLP) and financial analysis, focusing on the impact of sentiment analysis in stock price prediction. We employ BERTopic, an advanced NLP technique, to analyze the sentiment of topics derived from stock market comments. Our methodology integrates this sentiment analysis with various deep learning models, renowned for their effectiveness in time series and stock prediction tasks. Through comprehensive experiments, we demonstrate that incorporating topic sentiment notably enhances the performance of these models. The results indicate that topics in stock market comments provide implicit, valuable insights into stock market volatility and price trends. This study contributes to the field by showcasing the potential of NLP in enriching financial analysis and opens up avenues for further research into real-time sentiment analysis and the exploration of emotional and contextual aspects of market sentiment. The integration of advanced NLP techniques like BERTopic with traditional financial analysis methods marks a step forward in developing more sophisticated tools for understanding and predicting market behaviors.
4/5/2024
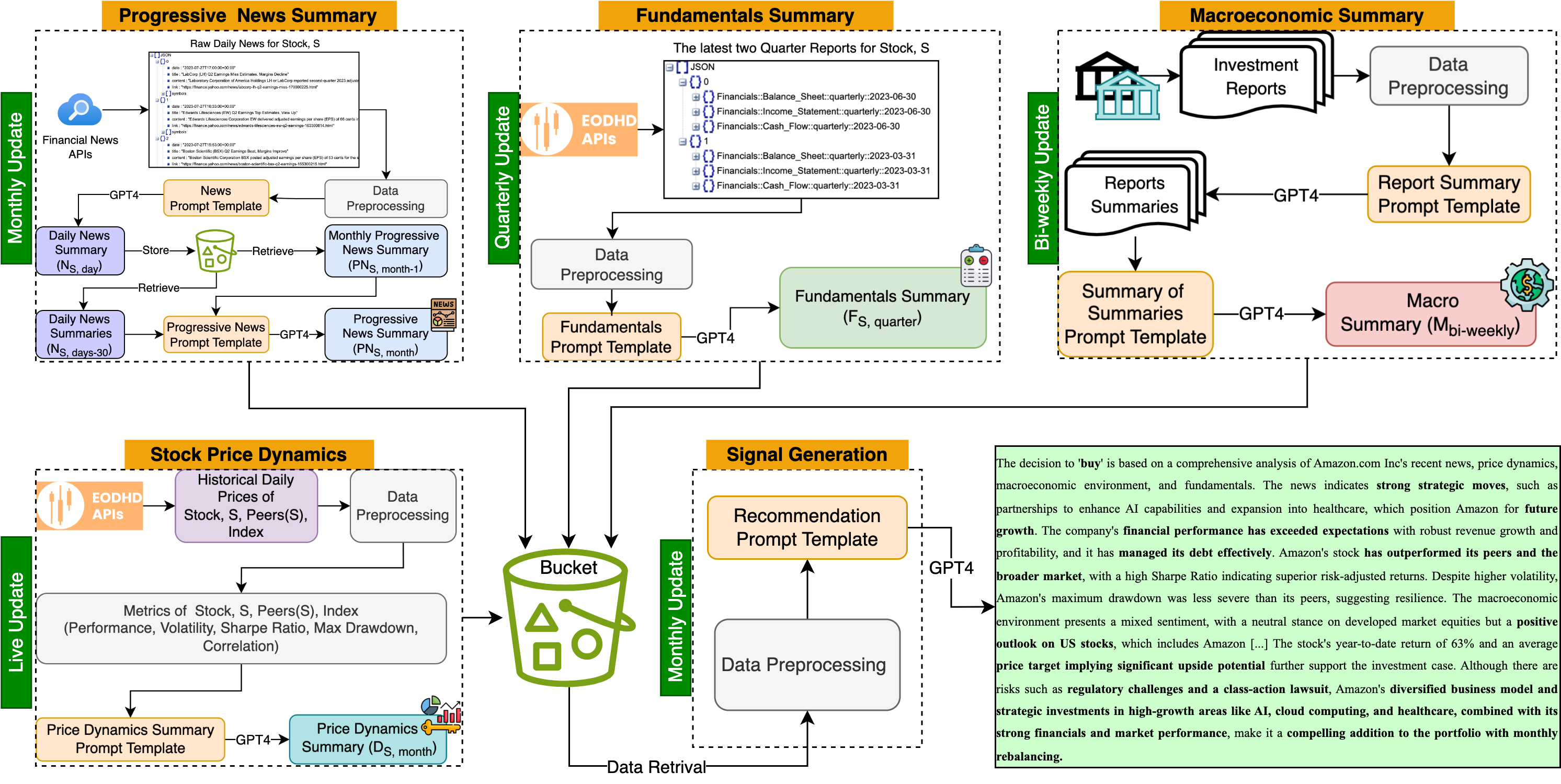
Can Large Language Models Beat Wall Street? Unveiling the Potential of AI in Stock Selection
Georgios Fatouros, Konstantinos Metaxas, John Soldatos, Dimosthenis Kyriazis
0
0
This paper introduces MarketSenseAI, an innovative framework leveraging GPT-4's advanced reasoning for selecting stocks in financial markets. By integrating Chain of Thought and In-Context Learning, MarketSenseAI analyzes diverse data sources, including market trends, news, fundamentals, and macroeconomic factors, to emulate expert investment decision-making. The development, implementation, and validation of the framework are elaborately discussed, underscoring its capability to generate actionable and interpretable investment signals. A notable feature of this work is employing GPT-4 both as a predictive mechanism and signal evaluator, revealing the significant impact of the AI-generated explanations on signal accuracy, reliability and acceptance. Through empirical testing on the competitive S&P 100 stocks over a 15-month period, MarketSenseAI demonstrated exceptional performance, delivering excess alpha of 10% to 30% and achieving a cumulative return of up to 72% over the period, while maintaining a risk profile comparable to the broader market. Our findings highlight the transformative potential of Large Language Models in financial decision-making, marking a significant leap in integrating generative AI into financial analytics and investment strategies.
4/5/2024
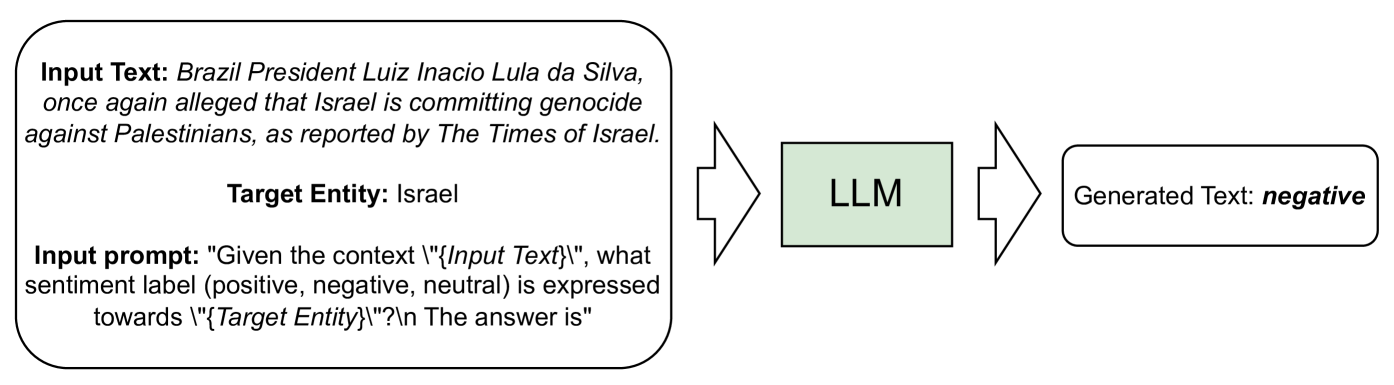
Deciphering Political Entity Sentiment in News with Large Language Models: Zero-Shot and Few-Shot Strategies
Alapan Kuila, Sudeshna Sarkar
0
0
Sentiment analysis plays a pivotal role in understanding public opinion, particularly in the political domain where the portrayal of entities in news articles influences public perception. In this paper, we investigate the effectiveness of Large Language Models (LLMs) in predicting entity-specific sentiment from political news articles. Leveraging zero-shot and few-shot strategies, we explore the capability of LLMs to discern sentiment towards political entities in news content. Employing a chain-of-thought (COT) approach augmented with rationale in few-shot in-context learning, we assess whether this method enhances sentiment prediction accuracy. Our evaluation on sentiment-labeled datasets demonstrates that LLMs, outperform fine-tuned BERT models in capturing entity-specific sentiment. We find that learning in-context significantly improves model performance, while the self-consistency mechanism enhances consistency in sentiment prediction. Despite the promising results, we observe inconsistencies in the effectiveness of the COT prompting method. Overall, our findings underscore the potential of LLMs in entity-centric sentiment analysis within the political news domain and highlight the importance of suitable prompting strategies and model architectures.
4/9/2024
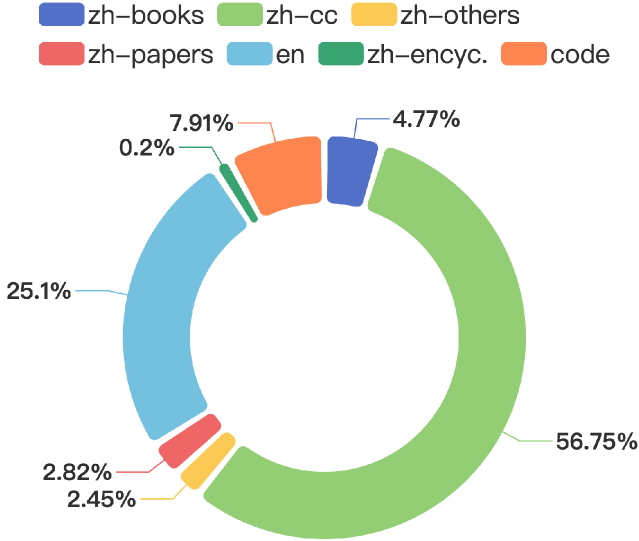
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Xinrun Du, Zhouliang Yu, Songyang Gao, Ding Pan, Yuyang Cheng, Ziyang Ma, Ruibin Yuan, Xingwei Qu, Jiaheng Liu, Tianyu Zheng, Xinchen Luo, Guorui Zhou, Binhang Yuan, Wenhu Chen, Jie Fu, Ge Zhang
0
0
In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
4/10/2024