Uplifting Range-View-based 3D Semantic Segmentation in Real-Time with Multi-Sensor Fusion

0

Sign in to get full access
Overview
- Proposes a real-time 3D semantic segmentation method that fuses data from multiple sensors, including lidar and cameras
- Aims to improve the accuracy and inference speed of 3D object detection and segmentation tasks
- Introduces a novel "Uplifting Range-View-based 3D Semantic Segmentation" model that leverages multi-sensor fusion
Plain English Explanation
This research paper presents a new approach for quickly and accurately identifying and categorizing objects in 3D environments using data from multiple sensors. The key idea is to combine information from lidar (which measures distances using laser light) and cameras to get a more complete and accurate picture of the 3D scene.
The researchers developed a model called "Uplifting Range-View-based 3D Semantic Segmentation" that takes the sensor data and can quickly and accurately detect and classify different objects, like cars, pedestrians, buildings, etc. This is an important capability for autonomous vehicles, robots, and other systems that need to understand their 3D surroundings in real-time.
By fusing the lidar and camera data, the model can leverage the strengths of each sensor - lidar provides precise 3D geometry, while cameras capture rich color and texture information. The researchers show this multi-sensor fusion approach leads to better performance compared to using just one sensor alone.
Technical Explanation
The paper introduces a novel "Uplifting Range-View-based 3D Semantic Segmentation" (UR3D) model that performs real-time 3D semantic segmentation by fusing data from multiple sensors, including lidar and cameras.
The UR3D architecture combines a range-view network that processes the lidar point cloud data with a view-based network that processes the camera images. The outputs of these two subnetworks are then fused to produce the final 3D semantic segmentation. The authors show this multi-sensor fusion approach outperforms using just the lidar or just the camera data alone.
Key innovations include:
- Range-view representation of lidar data to capture detailed 3D geometry information
- Efficient encoder-decoder network architecture for fast inference
- Multi-task learning to jointly predict 3D semantic segmentation and instance segmentation
- Dynamic fusion module to adaptively combine lidar and camera features
The UR3D model is evaluated on several benchmark datasets for 3D object detection and semantic segmentation, demonstrating state-of-the-art performance while running in real-time on commodity hardware.
Critical Analysis
The paper presents a compelling approach for real-time 3D semantic segmentation that effectively leverages multi-sensor fusion. The authors thoroughly evaluate their model and demonstrate strong results compared to prior work.
One limitation is that the method has only been tested on static scenes, and it's unclear how well it would perform in more dynamic environments with moving objects. The authors also note that further improvements in inference speed and memory efficiency would be desirable for deployment in resource-constrained embedded systems.
Additionally, the paper does not provide much insight into potential failure cases or edge cases where the model may struggle. More analysis of the model's weaknesses and limitations would help readers understand the boundaries of the approach.
Overall, this research represents an important advance in 3D perception that could significantly benefit autonomous vehicles, robotics, and other applications that require real-time understanding of complex 3D environments. The multi-sensor fusion technique is a promising direction for further exploration and refinement.
Conclusion
This paper presents a novel 3D semantic segmentation model that fuses data from multiple sensors, including lidar and cameras, to achieve real-time performance with high accuracy. The key innovation is the "Uplifting Range-View-based 3D Semantic Segmentation" (UR3D) architecture, which effectively combines the strengths of both sensor modalities.
The UR3D model demonstrates state-of-the-art results on 3D object detection and semantic segmentation benchmarks, while running in real-time on commodity hardware. This work represents an important step forward in 3D perception capabilities, with promising applications for autonomous vehicles, robotics, and other systems that need to understand complex 3D environments.
While the paper highlights some limitations that warrant further research, the multi-sensor fusion approach shown here is a compelling direction for continued innovation in the field of 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Uplifting Range-View-based 3D Semantic Segmentation in Real-Time with Multi-Sensor Fusion
Shiqi Tan, Hamidreza Fazlali, Yixuan Xu, Yuan Ren, Bingbing Liu
Range-View(RV)-based 3D point cloud segmentation is widely adopted due to its compact data form. However, RV-based methods fall short in providing robust segmentation for the occluded points and suffer from distortion of projected RGB images due to the sparse nature of 3D point clouds. To alleviate these problems, we propose a new LiDAR and Camera Range-view-based 3D point cloud semantic segmentation method (LaCRange). Specifically, a distortion-compensating knowledge distillation (DCKD) strategy is designed to remedy the adverse effect of RV projection of RGB images. Moreover, a context-based feature fusion module is introduced for robust and preservative sensor fusion. Finally, in order to address the limited resolution of RV and its insufficiency of 3D topology, a new point refinement scheme is devised for proper aggregation of features in 2D and augmentation of point features in 3D. We evaluated the proposed method on large-scale autonomous driving datasets ie SemanticKITTI and nuScenes. In addition to being real-time, the proposed method achieves state-of-the-art results on nuScenes benchmark
Read more7/16/2024
0
What Matters in Range View 3D Object Detection
Benjamin Wilson, Nicholas Autio Mitchell, Jhony Kaesemodel Pontes, James Hays
Lidar-based perception pipelines rely on 3D object detection models to interpret complex scenes. While multiple representations for lidar exist, the range-view is enticing since it losslessly encodes the entire lidar sensor output. In this work, we achieve state-of-the-art amongst range-view 3D object detection models without using multiple techniques proposed in past range-view literature. We explore range-view 3D object detection across two modern datasets with substantially different properties: Argoverse 2 and Waymo Open. Our investigation reveals key insights: (1) input feature dimensionality significantly influences the overall performance, (2) surprisingly, employing a classification loss grounded in 3D spatial proximity works as well or better compared to more elaborate IoU-based losses, and (3) addressing non-uniform lidar density via a straightforward range subsampling technique outperforms existing multi-resolution, range-conditioned networks. Our experiments reveal that techniques proposed in recent range-view literature are not needed to achieve state-of-the-art performance. Combining the above findings, we establish a new state-of-the-art model for range-view 3D object detection -- improving AP by 2.2% on the Waymo Open dataset while maintaining a runtime of 10 Hz. We establish the first range-view model on the Argoverse 2 dataset and outperform strong voxel-based baselines. All models are multi-class and open-source. Code is available at https://github.com/benjaminrwilson/range-view-3d-detection.
Read more7/29/2024
0
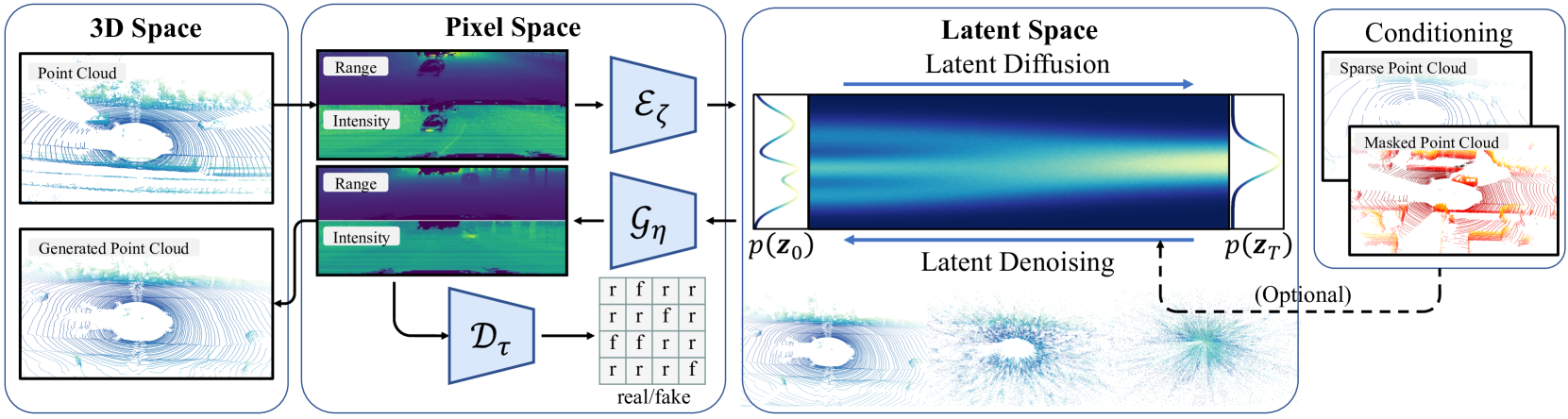
RangeLDM: Fast Realistic LiDAR Point Cloud Generation
Qianjiang Hu, Zhimin Zhang, Wei Hu
Autonomous driving demands high-quality LiDAR data, yet the cost of physical LiDAR sensors presents a significant scaling-up challenge. While recent efforts have explored deep generative models to address this issue, they often consume substantial computational resources with slow generation speeds while suffering from a lack of realism. To address these limitations, we introduce RangeLDM, a novel approach for rapidly generating high-quality range-view LiDAR point clouds via latent diffusion models. We achieve this by correcting range-view data distribution for accurate projection from point clouds to range images via Hough voting, which has a critical impact on generative learning. We then compress the range images into a latent space with a variational autoencoder, and leverage a diffusion model to enhance expressivity. Additionally, we instruct the model to preserve 3D structural fidelity by devising a range-guided discriminator. Experimental results on KITTI-360 and nuScenes datasets demonstrate both the robust expressiveness and fast speed of our LiDAR point cloud generation.
Read more9/11/2024

0
vFusedSeg3D: 3rd Place Solution for 2024 Waymo Open Dataset Challenge in Semantic Segmentation
Osama Amjad, Ammad Nadeem
In this technical study, we introduce VFusedSeg3D, an innovative multi-modal fusion system created by the VisionRD team that combines camera and LiDAR data to significantly enhance the accuracy of 3D perception. VFusedSeg3D uses the rich semantic content of the camera pictures and the accurate depth sensing of LiDAR to generate a strong and comprehensive environmental understanding, addressing the constraints inherent in each modality. Through a carefully thought-out network architecture that aligns and merges these information at different stages, our novel feature fusion technique combines geometric features from LiDAR point clouds with semantic features from camera images. With the use of multi-modality techniques, performance has significantly improved, yielding a state-of-the-art mIoU of 72.46% on the validation set as opposed to the prior 70.51%.VFusedSeg3D sets a new benchmark in 3D segmentation accuracy. making it an ideal solution for applications requiring precise environmental perception.
Read more8/29/2024