On the use of adversarial validation for quantifying dissimilarity in geospatial machine learning prediction

0

Sign in to get full access
Overview
- This paper explores the use of adversarial validation (AV) to quantify dissimilarity in geospatial machine learning predictions.
- AV is a technique where a model is trained to distinguish between "real" and "fake" data, which can reveal differences between training and test distributions.
- The researchers apply AV to assess the generalization performance of machine learning models trained on geospatial data, such as predicting land cover or property values.
Plain English Explanation
Geospatial machine learning models, which make predictions about locations on a map, can struggle to perform well when the data they're tested on is different from the data they were trained on. This paper introduces a technique called adversarial validation that can help quantify how different the test data is from the training data.
The key idea is to train a separate model, called an "adversary," whose job is to try to distinguish between the "real" training data and "fake" test data. If the adversary can easily tell the difference, it means the training and test data have different characteristics, which could lead to poor performance for the main prediction model.
By measuring how well the adversary can do this task, the researchers can get a sense of how dissimilar the training and test data are. This can help them understand why a model might not generalize well to new locations, and potentially identify ways to improve the model's performance, such as by collecting more representative training data.
Technical Explanation
The paper presents a two-stage approach for using adversarial validation (AV) to quantify dissimilarity in geospatial machine learning predictions:
-
Construct AV data: The researchers first split the available data into training and test sets. They then train an "adversary" model to distinguish between the training and test data, using the training data as "real" examples and the test data as "fake" examples.
-
Quantify dissimilarity: The performance of the adversary model on this task is used as a measure of dissimilarity between the training and test distributions. Metrics like the adversary's accuracy or the area under the ROC curve (AUC-ROC) can be used to summarize this dissimilarity.
The intuition is that if the training and test data are very different, the adversary model will be able to easily distinguish between them, resulting in high dissimilarity scores. Conversely, if the data is more similar, the adversary will struggle, leading to lower dissimilarity scores.
The researchers demonstrate this approach on several geospatial prediction tasks, including land cover mapping and property value estimation. They show that the AV dissimilarity scores correlate with the performance of the main prediction models, providing insights into why those models may struggle to generalize.
Critical Analysis
The paper provides a novel and interesting approach for quantifying distribution shift in geospatial machine learning, which is an important issue in real-world applications. The use of adversarial validation to measure dissimilarity between training and test data is a clever technique that can complement traditional evaluation metrics.
One potential limitation is that the AV dissimilarity score does not directly indicate
Additionally, the paper does not explore the impact of adversarial training or adversarial purification on the main prediction models. These techniques could potentially help the models become more robust to the distribution shifts identified by the AV approach.
Overall, this paper makes a valuable contribution by introducing a new tool for understanding and diagnosing generalization issues in geospatial machine learning. Further research exploring the practical applications and limitations of this approach would be valuable.
Conclusion
This paper presents a novel use of adversarial validation to quantify the dissimilarity between training and test data in geospatial machine learning tasks. By training a separate "adversary" model to distinguish real training data from fake test data, the researchers can get a measure of how different the two distributions are.
This dissimilarity score can provide insights into why a main prediction model may struggle to generalize to new locations, which is a common challenge in real-world geospatial applications. The technique could be a useful addition to the toolbox for developing more robust and reliable machine learning models for spatial data.
While the paper demonstrates the potential of this approach, further research is needed to fully understand its limitations and explore ways to leverage the AV dissimilarity scores to improve model performance, such as through adversarial training or data augmentation techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the use of adversarial validation for quantifying dissimilarity in geospatial machine learning prediction
Yanwen Wang, Mahdi Khodadadzadeh, Raul Zurita-Milla
Recent geospatial machine learning studies have shown that the results of model evaluation via cross-validation (CV) are strongly affected by the dissimilarity between the sample data and the prediction locations. In this paper, we propose a method to quantify such a dissimilarity in the interval 0 to 100%, and from the perspective of the data feature space. The proposed method is based on adversarial validation, which is an approach that can check whether sample data and prediction locations can be separated with a binary classifier. To study the effectiveness and generality of our method, we tested it on a series of experiments based on both synthetic and real datasets and with gradually increasing dissimilarities. Results show that the proposed method can successfully quantify dissimilarity across the entire range of values. Next to this, we studied how dissimilarity affects CV evaluations by comparing the results of random CV and of two spatial CV methods, namely block and spatial+ CV. Our results showed that CV evaluations follow similar patterns in all datasets and predictions: when dissimilarity is low (usually lower than 30%), random CV provides the most accurate evaluation results. As dissimilarity increases, spatial CV methods, especially spatial+ CV, become more and more accurate and even outperforming random CV. When dissimilarity is high (>=90%), no CV method provides accurate evaluations. These results show the importance of considering feature space dissimilarity when working with geospatial machine learning predictions, and can help researchers and practitioners to select more suitable CV methods for evaluating their predictions.
Read more4/22/2024

0
Consistent Validation for Predictive Methods in Spatial Settings
David R. Burt, Yunyi Shen, Tamara Broderick
Spatial prediction tasks are key to weather forecasting, studying air pollution, and other scientific endeavors. Determining how much to trust predictions made by statistical or physical methods is essential for the credibility of scientific conclusions. Unfortunately, classical approaches for validation fail to handle mismatch between locations available for validation and (test) locations where we want to make predictions. This mismatch is often not an instance of covariate shift (as commonly formalized) because the validation and test locations are fixed (e.g., on a grid or at select points) rather than i.i.d. from two distributions. In the present work, we formalize a check on validation methods: that they become arbitrarily accurate as validation data becomes arbitrarily dense. We show that classical and covariate-shift methods can fail this check. We instead propose a method that builds from existing ideas in the covariate-shift literature, but adapts them to the validation data at hand. We prove that our proposal passes our check. And we demonstrate its advantages empirically on simulated and real data.
Read more5/27/2024
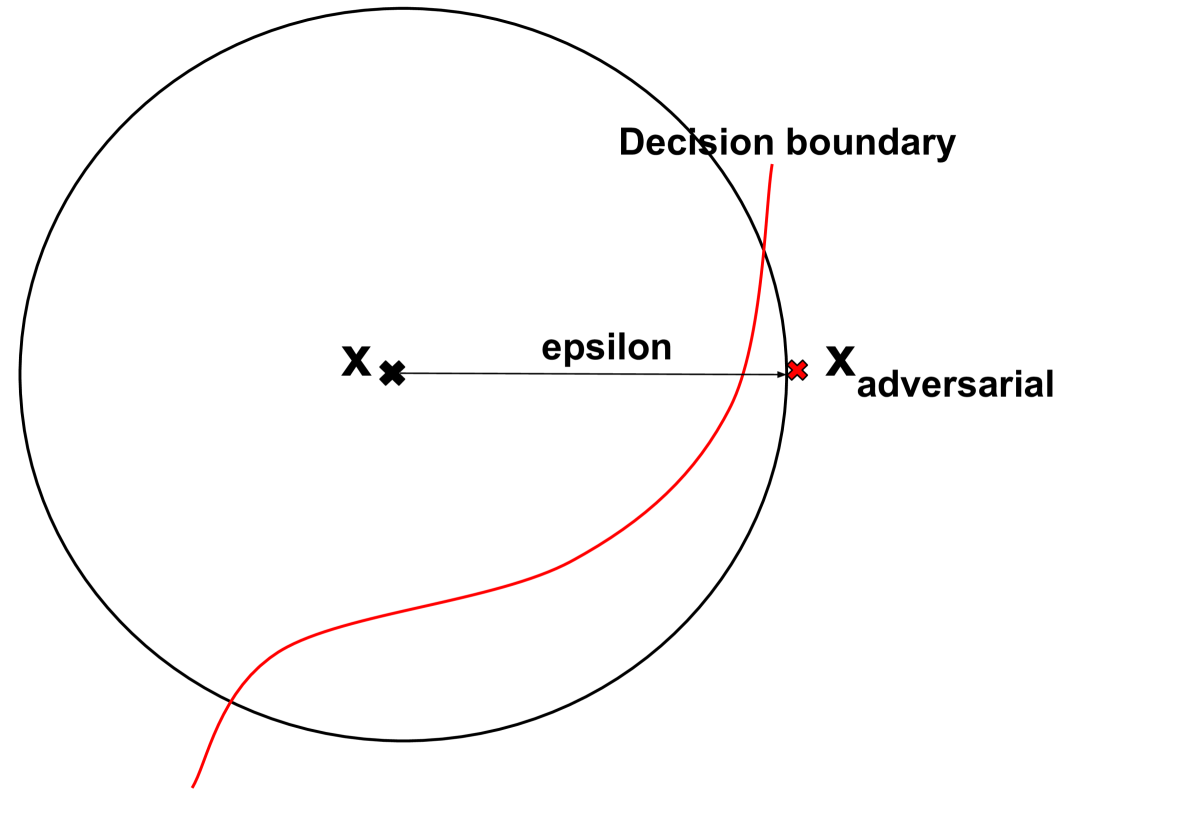
0
A practical approach to evaluating the adversarial distance for machine learning classifiers
Georg Siedel, Ekagra Gupta, Andrey Morozov
Robustness is critical for machine learning (ML) classifiers to ensure consistent performance in real-world applications where models may encounter corrupted or adversarial inputs. In particular, assessing the robustness of classifiers to adversarial inputs is essential to protect systems from vulnerabilities and thus ensure safety in use. However, methods to accurately compute adversarial robustness have been challenging for complex ML models and high-dimensional data. Furthermore, evaluations typically measure adversarial accuracy on specific attack budgets, limiting the informative value of the resulting metrics. This paper investigates the estimation of the more informative adversarial distance using iterative adversarial attacks and a certification approach. Combined, the methods provide a comprehensive evaluation of adversarial robustness by computing estimates for the upper and lower bounds of the adversarial distance. We present visualisations and ablation studies that provide insights into how this evaluation method should be applied and parameterised. We find that our adversarial attack approach is effective compared to related implementations, while the certification method falls short of expectations. The approach in this paper should encourage a more informative way of evaluating the adversarial robustness of ML classifiers.
Read more9/6/2024
📊
0
Synthetic Tabular Data Validation: A Divergence-Based Approach
Patricia A. Apell'aniz, Ana Jim'enez, Borja Arroyo Galende, Juan Parras, Santiago Zazo
The ever-increasing use of generative models in various fields where tabular data is used highlights the need for robust and standardized validation metrics to assess the similarity between real and synthetic data. Current methods lack a unified framework and rely on diverse and often inconclusive statistical measures. Divergences, which quantify discrepancies between data distributions, offer a promising avenue for validation. However, traditional approaches calculate divergences independently for each feature due to the complexity of joint distribution modeling. This paper addresses this challenge by proposing a novel approach that uses divergence estimation to overcome the limitations of marginal comparisons. Our core contribution lies in applying a divergence estimator to build a validation metric considering the joint distribution of real and synthetic data. We leverage a probabilistic classifier to approximate the density ratio between datasets, allowing the capture of complex relationships. We specifically calculate two divergences: the well-known Kullback-Leibler (KL) divergence and the Jensen-Shannon (JS) divergence. KL divergence offers an established use in the field, while JS divergence is symmetric and bounded, providing a reliable metric. The efficacy of this approach is demonstrated through a series of experiments with varying distribution complexities. The initial phase involves comparing estimated divergences with analytical solutions for simple distributions, setting a benchmark for accuracy. Finally, we validate our method on a real-world dataset and its corresponding synthetic counterpart, showcasing its effectiveness in practical applications. This research offers a significant contribution with applicability beyond tabular data and the potential to improve synthetic data validation in various fields.
Read more8/1/2024