Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
2312.06420
0
0
📊
Abstract
The task of online mapping is to predict a local map using current sensor observations, e.g. from lidar and camera, without relying on a pre-built map. State-of-the-art methods are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. However, these datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over $80$% of nuScenes and $40$% of Argoverse 2 validation and test samples are less than $5$ m from a training sample. At test time, the methods are thus evaluated more on how well they localize within a memorized implicit map built from the training data than on extrapolating to unseen locations. Naturally, this data leakage causes inflated performance numbers and we propose geographically disjoint data splits to reveal the true performance in unseen environments. Experimental results show that methods perform considerably worse, some dropping more than $45$ mAP, when trained and evaluated on proper data splits. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of lifting methods and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived. Splits can be found at https://github.com/LiljaAdam/geographical-splits
Create account to get full access
Overview
- The paper examines the task of online mapping, which involves predicting a local map using current sensor data without relying on a pre-built map.
- The state-of-the-art methods for this task are based on supervised learning, predominantly using the nuScenes and Argoverse 2 datasets.
- However, these datasets have a significant data leakage issue, where a large portion of the validation and test samples are geographically close to the training data.
- This means the methods are being evaluated more on their ability to localize within a memorized implicit map, rather than their capability to extrapolate to unseen locations.
- The paper proposes using geographically disjoint data splits to reveal the true performance of these methods in unseen environments.
Plain English Explanation
The paper is about a problem in the field of robotics and self-driving cars called "online mapping." This task involves using sensors like cameras and lidar to create a map of the local environment in real-time, without relying on a pre-made map. The current state-of-the-art methods for this task use machine learning techniques that are trained on two popular datasets: nuScenes and Argoverse 2.
However, the researchers found a problem with these datasets - a large portion of the validation and test data is actually quite close to the training data, geographically. This means the machine learning models are being evaluated more on their ability to "remember" the training locations, rather than their ability to accurately map completely new areas.
To address this issue, the researchers propose using "geographically disjoint" data splits, where the training, validation, and test sets are completely separate in terms of their geographic locations. When the models are evaluated this way, the researchers found that the performance drops significantly, sometimes by over 45%. This suggests that the original performance numbers were inflated due to the data leakage problem.
The researchers also found that some of the design choices and techniques that were previously thought to be helpful, like "lifting methods" and "auxiliary tasks," may not have as big of an impact on performance as previously believed. Their experiments with the new, geographically disjoint data splits led to different conclusions than the original studies.
Technical Explanation
The paper focuses on the task of online mapping, which involves using current sensor observations, such as from lidar and cameras, to predict a local map without relying on a pre-built map. The state-of-the-art methods for this task are based on supervised learning and are predominantly trained using the nuScenes and Argoverse 2 datasets.
However, the researchers found that these datasets have a significant data leakage issue. Specifically, over 80% of the nuScenes and 40% of the Argoverse 2 validation and test samples are less than 5 meters away from a training sample. This means the methods are being evaluated more on their ability to localize within a memorized implicit map built from the training data, rather than their ability to extrapolate to truly unseen locations.
To address this issue, the researchers propose using geographically disjoint data splits to reveal the true performance of these methods in unseen environments. Their experimental results show that the methods perform considerably worse when trained and evaluated on these proper data splits, with some dropping more than 45 mAP (mean average precision).
Additionally, the researchers' reassessment of prior design choices, such as the impact of lifting methods and the support from auxiliary tasks (e.g., depth supervision), reveals diverging conclusions from those based on the original data splits. The researchers found that the impact of these techniques appears less substantial or follows a different trajectory than previously perceived.
Critical Analysis
The paper raises an important issue regarding the evaluation of online mapping methods, highlighting the problem of data leakage in the commonly used nuScenes and Argoverse 2 datasets. The proposed use of geographically disjoint data splits is a reasonable approach to address this problem and reveal the true performance of these methods in unseen environments.
However, the paper does not delve into the potential causes of the data leakage issue in the original datasets. It would be helpful to understand the factors that led to this problem, such as the geographic distribution of the data collection, the sampling strategies, or the data curation processes. Addressing these underlying causes could help in the design of more robust and representative datasets for the online mapping task.
Additionally, the paper would benefit from a more in-depth discussion of the implications of the performance drop observed when using the geographically disjoint data splits. The authors could explore the potential reasons for the significant drop, such as the reliance of the methods on specific geographic features or their inability to generalize to truly novel environments.
Furthermore, the paper could provide more guidance on how the research community can move forward in this area. Suggestions for dataset design, evaluation protocols, or model development strategies that can help overcome the challenges highlighted in this work would be valuable for advancing the field.
Conclusion
The paper has shed light on an important issue in the evaluation of online mapping methods, highlighting the problem of data leakage in commonly used datasets. By proposing the use of geographically disjoint data splits, the researchers have revealed that the true performance of these methods in unseen environments is considerably worse than what was previously reported.
This work serves as a cautionary tale for the research community, emphasizing the importance of careful dataset design and evaluation protocols to ensure the validity and generalizability of the findings. The insights gained from this study can inform the development of more robust and reliable online mapping systems, which are crucial for the advancement of robotics and autonomous vehicle technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Classification for everyone : Building geography agnostic models for fairer recognition
Akshat Jindal, Shreya Singh, Soham Gadgil
0
0
In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
4/3/2024

Regional biases in image geolocation estimation: a case study with the SenseCity Africa dataset
Ximena Salgado Uribe, Mart'i Bosch, J'er^ome Chenal
0
0
Advances in Artificial Intelligence are challenged by the biases rooted in the datasets used to train the models. In image geolocation estimation, models are mostly trained using data from specific geographic regions, notably the Western world, and as a result, they may struggle to comprehend the complexities of underrepresented regions. To assess this issue, we apply a state-of-the-art image geolocation estimation model (ISNs) to a crowd-sourced dataset of geolocated images from the African continent (SCA100), and then explore the regional and socioeconomic biases underlying the model's predictions. Our findings show that the ISNs model tends to over-predict image locations in high-income countries of the Western world, which is consistent with the geographic distribution of its training data, i.e., the IM2GPS3k dataset. Accordingly, when compared to the IM2GPS3k benchmark, the accuracy of the ISNs model notably decreases at all scales. Additionally, we cluster images of the SCA100 dataset based on how accurately they are predicted by the ISNs model and show the model's difficulties in correctly predicting the locations of images in low income regions, especially in Sub-Saharan Africa. Therefore, our results suggest that using IM2GPS3k as a training set and benchmark for image geolocation estimation and other computer vision models overlooks its potential application in the African context.
4/4/2024

LLMGeo: Benchmarking Large Language Models on Image Geolocation In-the-wild
Zhiqiang Wang, Dejia Xu, Rana Muhammad Shahroz Khan, Yanbin Lin, Zhiwen Fan, Xingquan Zhu
0
0
Image geolocation is a critical task in various image-understanding applications. However, existing methods often fail when analyzing challenging, in-the-wild images. Inspired by the exceptional background knowledge of multimodal language models, we systematically evaluate their geolocation capabilities using a novel image dataset and a comprehensive evaluation framework. We first collect images from various countries via Google Street View. Then, we conduct training-free and training-based evaluations on closed-source and open-source multi-modal language models. we conduct both training-free and training-based evaluations on closed-source and open-source multimodal language models. Our findings indicate that closed-source models demonstrate superior geolocation abilities, while open-source models can achieve comparable performance through fine-tuning.
6/3/2024
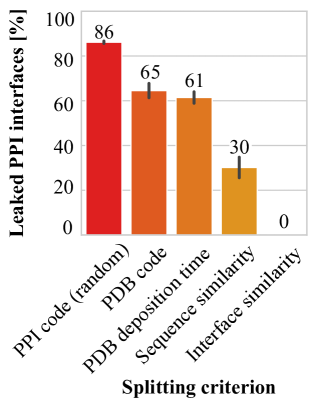
Revealing data leakage in protein interaction benchmarks
Anton Bushuiev, Roman Bushuiev, Jiri Sedlar, Tomas Pluskal, Jiri Damborsky, Stanislav Mazurenko, Josef Sivic
0
0
In recent years, there has been remarkable progress in machine learning for protein-protein interactions. However, prior work has predominantly focused on improving learning algorithms, with less attention paid to evaluation strategies and data preparation. Here, we demonstrate that further development of machine learning methods may be hindered by the quality of existing train-test splits. Specifically, we find that commonly used splitting strategies for protein complexes, based on protein sequence or metadata similarity, introduce major data leakage. This may result in overoptimistic evaluation of generalization, as well as unfair benchmarking of the models, biased towards assessing their overfitting capacity rather than practical utility. To overcome the data leakage, we recommend constructing data splits based on 3D structural similarity of protein-protein interfaces and suggest corresponding algorithms. We believe that addressing the data leakage problem is critical for further progress in this research area.
4/17/2024