UserBoost: Generating User-specific Synthetic Data for Faster Enrolment into Behavioural Biometric Systems

0

Sign in to get full access
Overview
- The paper proposes a method called "UserBoost" to generate user-specific synthetic data for faster enrollment into behavioral biometric systems.
- Behavioral biometric systems, such as those used for mobile payments or smartwatch authentication, can take a long time to enroll a new user due to the need for collecting sufficient user data.
- UserBoost aims to address this issue by generating synthetic data that can be used to kickstart the enrollment process, reducing the time and effort required.
Plain English Explanation
The paper focuses on a problem faced by behavioral biometric systems, which are used for things like unlocking your phone or authorizing mobile payments. These systems need to learn about your unique behaviors, like how you tap your screen or move your smartwatch, in order to recognize and authenticate you. However, collecting enough data from you to train the system can take a long time, which is inconvenient.
The researchers developed a method called "UserBoost" to try to speed up this enrollment process. The key idea is to generate synthetic, fake data that looks like it came from you. This synthetic data can be used to get the system started on learning your behavioral patterns, before it collects real data from you. By having this "head start," the system can enroll you more quickly and with less hassle.
The paper demonstrates how UserBoost can generate convincing synthetic data for tasks like recognizing tap gestures on a smartphone or detecting movements from a smartwatch. The generated data closely matches the characteristics of real user data, allowing the biometric systems to use it effectively.
Technical Explanation
The UserBoost method is built around an autoencoder-based architecture [link to "Generating Synthetic Health Sensor Data for Privacy-Preserving"]. The autoencoder learns to encode user-specific behavioral data into a low-dimensional latent space, and then decode this latent representation back into synthetic data that preserves the key statistical properties of the original user data.
To personalize the synthetic data for each user, UserBoost conditions the autoencoder on user-specific metadata, such as demographic information or device usage patterns [link to "Wearable Sensor-based Few-shot Continual Learning"]. This allows the model to generate synthetic data that is tailored to the target user's unique behavioral characteristics.
The paper evaluates UserBoost on two case studies: tap gesture recognition on smartphones and activity recognition from smartwatch sensors. The results show that incorporating the synthetic data generated by UserBoost can significantly reduce the enrollment time required to achieve high recognition accuracy, compared to using only real user data [link to "ChatEMG: Synthetic Data Generation to Control Robotic Prosthetics"].
Critical Analysis
The paper provides a promising approach to address the enrollment challenge in behavioral biometric systems. By generating user-specific synthetic data, UserBoost can kickstart the learning process and make it faster and more convenient for users to get set up with these systems.
However, the paper does not extensively discuss potential limitations or risks of this approach. For example, it is unclear how the synthetic data might impact the long-term performance and security of the biometric systems, or how users might react to having their data augmented with machine-generated samples.
Additionally, the paper focuses on relatively simple behavioral tasks like tap gestures and activity recognition. It would be valuable to see how well UserBoost can handle more complex behavioral patterns, or how it might scale to larger and more diverse user populations [link to "Model-Agnostic Utility-Preserving Biometric Information Anonymization"].
Overall, the UserBoost approach is a promising step forward, but further research is needed to fully understand its implications and ensure it is deployed responsibly to benefit users without compromising their privacy or security.
Conclusion
The UserBoost method presented in this paper offers a novel way to accelerate the enrollment process for behavioral biometric systems. By generating user-specific synthetic data, the system can get a head start on learning a user's unique behavioral patterns, reducing the time and effort required for onboarding.
This technique has the potential to make behavioral biometrics more accessible and convenient for a wide range of applications, from mobile payments to wearable device authentication. As these systems become more prevalent in our daily lives, innovations like UserBoost will be crucial for ensuring a seamless and user-friendly experience.
However, the long-term impacts and potential risks of this approach will require careful consideration by researchers and practitioners. Ongoing work is needed to further refine and validate the UserBoost method, as well as to address any ethical or security concerns that may arise from the use of synthetic data in sensitive biometric applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UserBoost: Generating User-specific Synthetic Data for Faster Enrolment into Behavioural Biometric Systems
George Webber, Jack Sturgess, Ivan Martinovic
Behavioural biometric authentication systems entail an enrolment period that is burdensome for the user. In this work, we explore generating synthetic gestures from a few real user gestures with generative deep learning, with the application of training a simple (i.e. non-deep-learned) authentication model. Specifically, we show that utilising synthetic data alongside real data can reduce the number of real datapoints a user must provide to enrol into a biometric system. To validate our methods, we use the publicly available dataset of WatchAuth, a system proposed in 2022 for authenticating smartwatch payments using the physical gesture of reaching towards a payment terminal. We develop a regularised autoencoder model for generating synthetic user-specific wrist motion data representing these physical gestures, and demonstrate the diversity and fidelity of our synthetic gestures. We show that using synthetic gestures in training can improve classification ability for a real-world system. Through this technique we can reduce the number of gestures required to enrol a user into a WatchAuth-like system by more than 40% without negatively impacting its error rates.
Read more7/15/2024
🛸
0
SynthoGestures: A Novel Framework for Synthetic Dynamic Hand Gesture Generation for Driving Scenarios
Amr Gomaa, Robin Zitt, Guillermo Reyes, Antonio Kruger
Creating a diverse and comprehensive dataset of hand gestures for dynamic human-machine interfaces in the automotive domain can be challenging and time-consuming. To overcome this challenge, we propose using synthetic gesture datasets generated by virtual 3D models. Our framework utilizes Unreal Engine to synthesize realistic hand gestures, offering customization options and reducing the risk of overfitting. Multiple variants, including gesture speed, performance, and hand shape, are generated to improve generalizability. In addition, we simulate different camera locations and types, such as RGB, infrared, and depth cameras, without incurring additional time and cost to obtain these cameras. Experimental results demonstrate that our proposed framework, SynthoGestures (https://github.com/amrgomaaelhady/SynthoGestures), improves gesture recognition accuracy and can replace or augment real-hand datasets. By saving time and effort in the creation of the data set, our tool accelerates the development of gesture recognition systems for automotive applications.
Read more8/6/2024
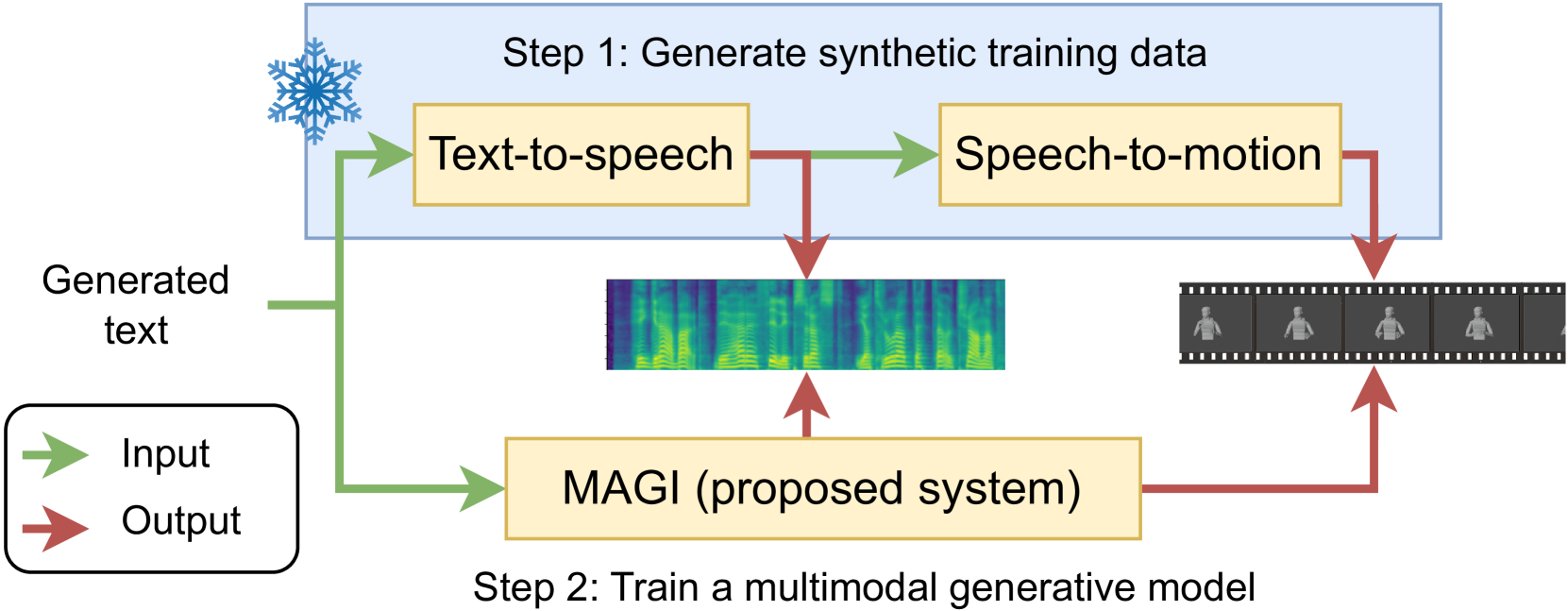
0
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Shivam Mehta, Anna Deichler, Jim O'Regan, Birger Moell, Jonas Beskow, Gustav Eje Henter, Simon Alexanderson
Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Read more5/1/2024
📊
0
Generating Synthetic Health Sensor Data for Privacy-Preserving Wearable Stress Detection
Lucas Lange, Nils Wenzlitschke, Erhard Rahm
Smartwatch health sensor data are increasingly utilized in smart health applications and patient monitoring, including stress detection. However, such medical data often comprise sensitive personal information and are resource-intensive to acquire for research purposes. In response to this challenge, we introduce the privacy-aware synthetization of multi-sensor smartwatch health readings related to moments of stress, employing Generative Adversarial Networks (GANs) and Differential Privacy (DP) safeguards. Our method not only protects patient information but also enhances data availability for research. To ensure its usefulness, we test synthetic data from multiple GANs and employ different data enhancement strategies on an actual stress detection task. Our GAN-based augmentation methods demonstrate significant improvements in model performance, with private DP training scenarios observing an 11.90-15.48% increase in F1-score, while non-private training scenarios still see a 0.45% boost. These results underline the potential of differentially private synthetic data in optimizing utility-privacy trade-offs, especially with the limited availability of real training samples. Through rigorous quality assessments, we confirm the integrity and plausibility of our synthetic data, which, however, are significantly impacted when increasing privacy requirements.
Read more5/15/2024