Improving Speech Inversion Through Self-Supervised Embeddings and Enhanced Tract Variables

0
🗣️
Sign in to get full access
Overview
- Deep learning models rely on efficient encoding and decoding of input features to achieve good performance and generalization.
- In speech inversion (SI) systems, researchers studied the impact of using speech representations from self-supervised learning (SSL) models and incorporating novel tract variables (TVs) through an improved geometric transformation model.
- By combining these approaches, the researchers were able to improve the accuracy of TV estimation in the SI system.
Plain English Explanation
The success of deep learning models depends heavily on how well they can take the input information and turn it into useful outputs. When it comes to speech inversion (SI) systems, which try to estimate the movements of the mouth and throat (called tract variables or TVs) from audio, the researchers looked at two ways to improve performance:
-
Using speech representations learned by self-supervised learning (SSL) models, like HuBERT, instead of traditional acoustic features. SSL models can extract rich, meaningful information from speech data without needing manual labels.
-
Incorporating novel tract variables (TVs) and using an improved geometric transformation model to better connect the audio input to the estimated TV outputs.
By combining these two approaches, the researchers were able to significantly boost the accuracy of the TV estimates produced by the SI system, as measured by the Pearson correlation score. This shows the power of using advanced speech representations and targeted output variables to enhance the performance of these types of speech modeling systems.
Technical Explanation
The researchers investigated ways to improve the performance of acoustic-to-articulatory speech inversion (SI) systems. SI systems aim to estimate the movements of the vocal tract (called tract variables or TVs) from audio input.
The researchers explored two key approaches:
-
Leveraging self-supervised learning (SSL) speech representations: Rather than using conventional acoustic features as input, the researchers used speech representations learned by SSL models like HuBERT. SSL models can extract rich, meaningful information from speech data without needing manual labels.
-
Incorporating novel tract variables (TVs): The researchers used an improved geometric transformation model to better connect the audio input to the estimated TV outputs, including some novel TV definitions.
By combining these two innovations, the researchers were able to improve the Pearson product-moment correlation (PPMC) scores, which evaluate the accuracy of the TV estimates, from 0.7452 to 0.8141 - a 6.9% increase.
Critical Analysis
The paper presents a promising approach to enhancing the performance of speech inversion systems by leveraging advances in self-supervised learning and geometric modeling. However, the researchers acknowledge some limitations:
- The study was conducted on a relatively small dataset, so further validation on larger, more diverse datasets would be valuable.
- The proposed model still has room for improvement in accurately estimating certain tract variables, so continued research is needed to refine the geometric transformation and incorporate other novel signal processing techniques.
- While the SSL representations boosted performance, the specific mechanisms by which they benefit the SI task could be explored in greater depth through additional analysis and ablation studies.
Overall, the findings underscore the potential of rich feature representations and targeted output modeling to drive progress in speech inversion and related areas of speech processing. Continued innovation in these directions could lead to significant advancements in the field.
Conclusion
This research demonstrates that the performance of speech inversion systems can be substantially improved by leveraging self-supervised speech representations and incorporating novel tract variables through an enhanced geometric transformation model. By combining these two approaches, the researchers were able to boost the accuracy of tract variable estimation by over 6%. These findings highlight the value of advanced feature representations and targeted output modeling for enhancing the capabilities of speech processing systems, with potential applications in areas like speech recognition, synthesis, and clinical assessment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Improving Speech Inversion Through Self-Supervised Embeddings and Enhanced Tract Variables
Ahmed Adel Attia, Yashish M. Siriwardena, Carol Espy-Wilson
The performance of deep learning models depends significantly on their capacity to encode input features efficiently and decode them into meaningful outputs. Better input and output representation has the potential to boost models' performance and generalization. In the context of acoustic-to-articulatory speech inversion (SI) systems, we study the impact of utilizing speech representations acquired via self-supervised learning (SSL) models, such as HuBERT compared to conventional acoustic features. Additionally, we investigate the incorporation of novel tract variables (TVs) through an improved geometric transformation model. By combining these two approaches, we improve the Pearson product-moment correlation (PPMC) scores which evaluate the accuracy of TV estimation of the SI system from 0.7452 to 0.8141, a 6.9% increase. Our findings underscore the profound influence of rich feature representations from SSL models and improved geometric transformations with target TVs on the enhanced functionality of SI systems.
Read more9/10/2024

0
Efficient infusion of self-supervised representations in Automatic Speech Recognition
Darshan Prabhu, Sai Ganesh Mirishkar, Pankaj Wasnik
Self-supervised learned (SSL) models such as Wav2vec and HuBERT yield state-of-the-art results on speech-related tasks. Given the effectiveness of such models, it is advantageous to use them in conventional ASR systems. While some approaches suggest incorporating these models as a trainable encoder or a learnable frontend, training such systems is extremely slow and requires a lot of computation cycles. In this work, we propose two simple approaches that use (1) framewise addition and (2) cross-attention mechanisms to efficiently incorporate the representations from the SSL model(s) into the ASR architecture, resulting in models that are comparable in size with standard encoder-decoder conformer systems while also avoiding the usage of SSL models during training. Our approach results in faster training and yields significant performance gains on the Librispeech and Tedlium datasets compared to baselines. We further provide detailed analysis and ablation studies that demonstrate the effectiveness of our approach.
Read more4/22/2024
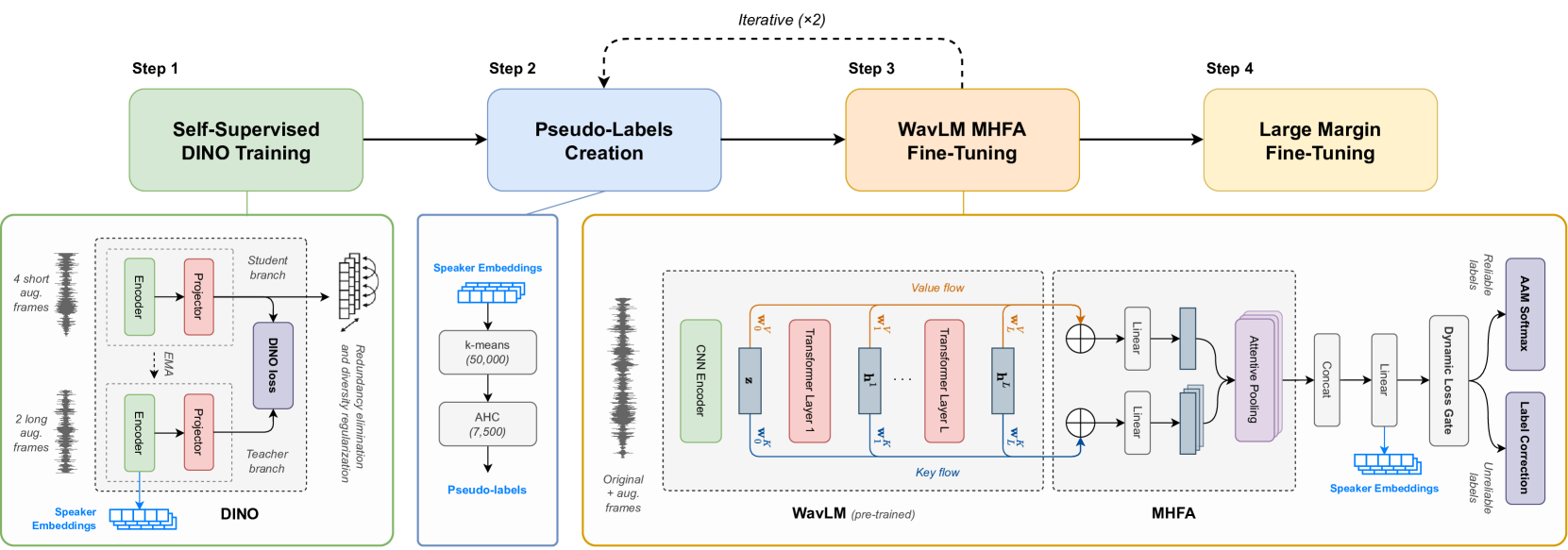
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more9/17/2024
⛏️
0
SelfVC: Voice Conversion With Iterative Refinement using Self Transformations
Paarth Neekhara, Shehzeen Hussain, Rafael Valle, Boris Ginsburg, Rishabh Ranjan, Shlomo Dubnov, Farinaz Koushanfar, Julian McAuley
We propose SelfVC, a training strategy to iteratively improve a voice conversion model with self-synthesized examples. Previous efforts on voice conversion focus on factorizing speech into explicitly disentangled representations that separately encode speaker characteristics and linguistic content. However, disentangling speech representations to capture such attributes using task-specific loss terms can lead to information loss. In this work, instead of explicitly disentangling attributes with loss terms, we present a framework to train a controllable voice conversion model on entangled speech representations derived from self-supervised learning (SSL) and speaker verification models. First, we develop techniques to derive prosodic information from the audio signal and SSL representations to train predictive submodules in the synthesis model. Next, we propose a training strategy to iteratively improve the synthesis model for voice conversion, by creating a challenging training objective using self-synthesized examples. We demonstrate that incorporating such self-synthesized examples during training improves the speaker similarity of generated speech as compared to a baseline voice conversion model trained solely on heuristically perturbed inputs. Our framework is trained without any text and achieves state-of-the-art results in zero-shot voice conversion on metrics evaluating naturalness, speaker similarity, and intelligibility of synthesized audio.
Read more5/6/2024