Utilizing dataset affinity prediction in object detection to assess training data

0
🔮
Sign in to get full access
Overview
- Data pooling can offer advantages such as increasing sample size, improving generalization, reducing sampling bias, and addressing data sparsity and quality
- However, assessing the effectiveness of data pooling is challenging due to difficulties in estimating the overall information content of individual datasets
- The paper proposes incorporating a data source prediction module into object detection pipelines to provide additional information about the data source assigned to individual detections
Plain English Explanation
When working with machine learning, researchers often have access to multiple datasets that could be useful for a particular task, such as object detection. Combining or "pooling" these datasets can provide some benefits, like increasing the total number of training examples, which can help the model learn more effectively. It can also reduce biases that might be present in any single dataset and address problems with data quality or sparsity.
However, deciding how to best utilize multiple datasets is not straightforward. It's hard to know how much useful information each dataset contains and whether combining them will actually improve model performance. The paper proposes an approach to help address this challenge.
Technical Explanation
The key idea is to incorporate a "data source prediction" module into the object detection pipeline. This module runs alongside the main object detection model and predicts which dataset each detected object came from. This "dataset affinity score" provides additional information that can be used to selectively pool training samples from the different datasets.
The results show that object detectors can be trained on a significantly smaller set of training samples, without losing detection accuracy, by leveraging this dataset affinity information. This suggests that the proposed approach can help researchers and practitioners more effectively utilize multiple datasets for machine learning tasks like object detection in autonomous driving.
Critical Analysis
The paper presents a promising approach for improving dataset pooling, but there are a few potential limitations and areas for further research. For example, the experiments were focused on vehicle detection, so it's unclear how well the method would generalize to other object detection tasks. Additionally, the paper does not explore the computational overhead of the data source prediction module or how it might impact inference speed in practical applications.
Another potential concern is that the dataset affinity scores could encode unwanted biases or idiosyncrasies of the individual datasets. Further analysis would be needed to understand how these scores are being used and their potential unintended consequences.
Overall, the paper makes a valuable contribution by proposing a novel way to leverage multiple datasets more effectively. However, as with any research, there are opportunities for continued exploration and refinement of the techniques.
Conclusion
This paper introduces an innovative approach to dataset pooling for object detection tasks. By incorporating a data source prediction module, the method provides additional information that can be used to selectively combine training samples from multiple datasets. The results demonstrate the potential benefits of this technique, suggesting it could help researchers and practitioners make more effective use of heterogeneous data sources. While there are some open questions and areas for further research, this work represents an important step forward in addressing the challenges of dataset pooling in machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Utilizing dataset affinity prediction in object detection to assess training data
Stefan Becker, Jens Bayer, Ronny Hug, Wolfgang Hubner, Michael Arens
Data pooling offers various advantages, such as increasing the sample size, improving generalization, reducing sampling bias, and addressing data sparsity and quality, but it is not straightforward and may even be counterproductive. Assessing the effectiveness of pooling datasets in a principled manner is challenging due to the difficulty in estimating the overall information content of individual datasets. Towards this end, we propose incorporating a data source prediction module into standard object detection pipelines. The module runs with minimal overhead during inference time, providing additional information about the data source assigned to individual detections. We show the benefits of the so-called dataset affinity score by automatically selecting samples from a heterogeneous pool of vehicle datasets. The results show that object detectors can be trained on a significantly sparser set of training samples without losing detection accuracy.
Read more5/9/2024

0
Diverse Generation while Maintaining Semantic Coordination: A Diffusion-Based Data Augmentation Method for Object Detection
Sen Nie, Zhuo Wang, Xinxin Wang, Kun He
Recent studies emphasize the crucial role of data augmentation in enhancing the performance of object detection models. However,existing methodologies often struggle to effectively harmonize dataset diversity with semantic coordination.To bridge this gap, we introduce an innovative augmentation technique leveraging pre-trained conditional diffusion models to mediate this balance. Our approach encompasses the development of a Category Affinity Matrix, meticulously designed to enhance dataset diversity, and a Surrounding Region Alignment strategy, which ensures the preservation of semantic coordination in the augmented images. Extensive experimental evaluations confirm the efficacy of our method in enriching dataset diversity while seamlessly maintaining semantic coordination. Our method yields substantial average improvements of +1.4AP, +0.9AP, and +3.4AP over existing alternatives on three distinct object detection models, respectively.
Read more8/7/2024
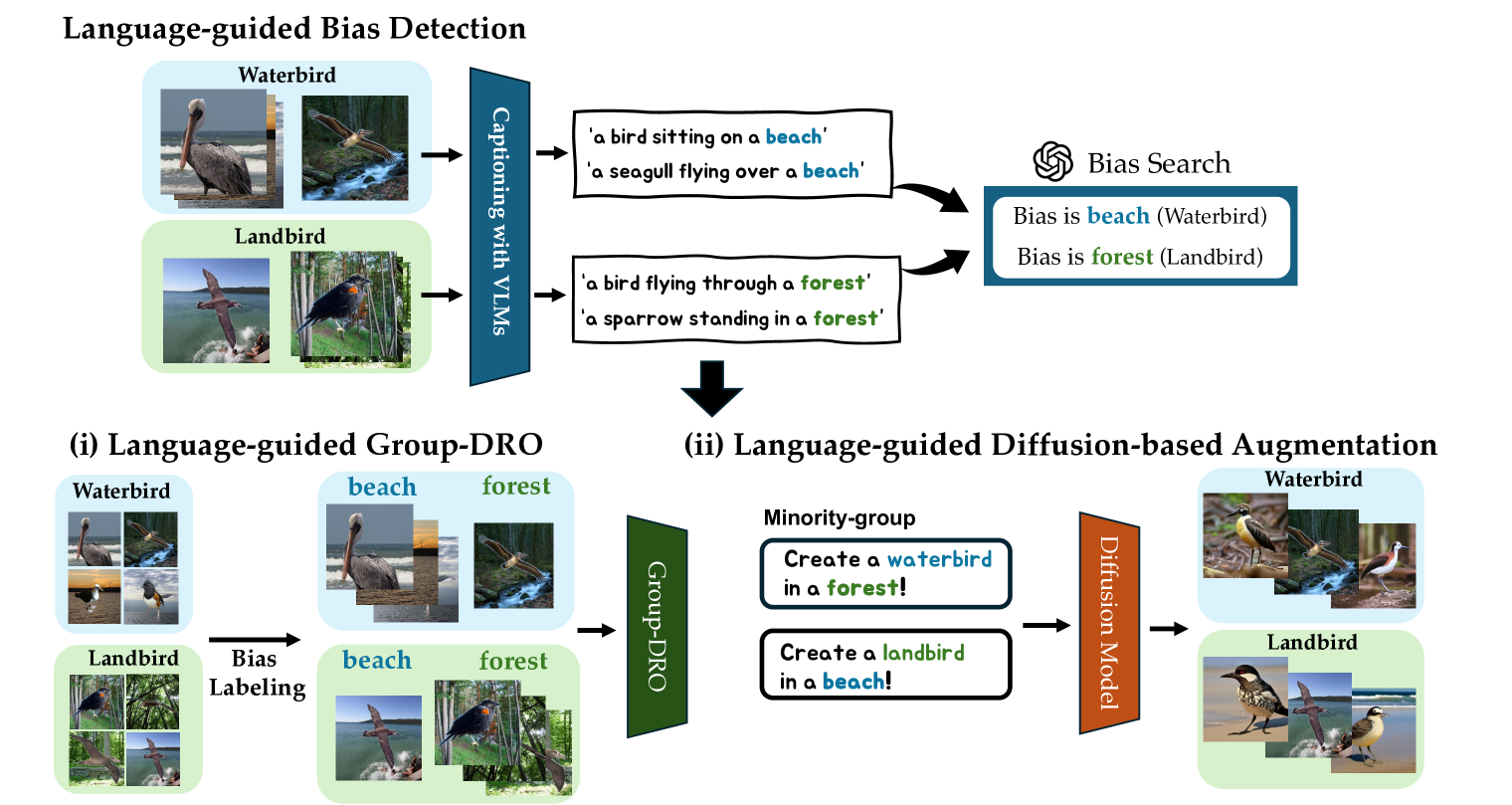
0
Language-guided Detection and Mitigation of Unknown Dataset Bias
Zaiying Zhao, Soichiro Kumano, Toshihiko Yamasaki
Dataset bias is a significant problem in training fair classifiers. When attributes unrelated to classification exhibit strong biases towards certain classes, classifiers trained on such dataset may overfit to these bias attributes, substantially reducing the accuracy for minority groups. Mitigation techniques can be categorized according to the availability of bias information (ie, prior knowledge). Although scenarios with unknown biases are better suited for real-world settings, previous work in this field often suffers from a lack of interpretability regarding biases and lower performance. In this study, we propose a framework to identify potential biases as keywords without prior knowledge based on the partial occurrence in the captions. We further propose two debiasing methods: (a) handing over to an existing debiasing approach which requires prior knowledge by assigning pseudo-labels, and (b) employing data augmentation via text-to-image generative models, using acquired bias keywords as prompts. Despite its simplicity, experimental results show that our framework not only outperforms existing methods without prior knowledge, but also is even comparable with a method that assumes prior knowledge.
Read more6/6/2024
🔎
0
Consensus Focus for Object Detection and minority classes
Erik Isai Valle Salgado, Chen Li, Yaqi Han, Linchao Shi, Xinghui Li
Ensemble methods exploit the availability of a given number of classifiers or detectors trained in single or multiple source domains and tasks to address machine learning problems such as domain adaptation or multi-source transfer learning. Existing research measures the domain distance between the sources and the target dataset, trains multiple networks on the same data with different samples per class, or combines predictions from models trained under varied hyperparameters and settings. Their solutions enhanced the performance on small or tail categories but hurt the rest. To this end, we propose a modified consensus focus for semi-supervised and long-tailed object detection. We introduce a voting system based on source confidence that spots the contribution of each model in a consensus, lets the user choose the relevance of each class in the target label space so that it relaxes minority bounding boxes suppression, and combines multiple models' results without discarding the poisonous networks. Our tests on synthetic driving datasets retrieved higher confidence and more accurate bounding boxes than the NMS, soft-NMS, and WBF. The code used to generate the results is available in our GitHub repository: http://github.com/ErikValle/Consensus-focus-for-object-detection.
Read more6/4/2024