VaLID: Verification as Late Integration of Detections for LiDAR-Camera Fusion

0

Sign in to get full access
Overview
- This paper proposes a novel approach called VaLID (Verification as Late Integration of Detections) for fusing data from LiDAR and camera sensors in autonomous vehicles.
- VaLID aims to improve the accuracy and robustness of object detection by verifying detections from each sensor modality before integrating them.
- The key idea is to delay the fusion of LiDAR and camera data until after individual detections have been verified, in contrast to earlier fusion approaches.
Plain English Explanation
The paper presents a new method called VaLID: Verification as Late Integration of Detections for LiDAR-Camera Fusion for combining information from LiDAR and camera sensors in self-driving cars.
Autonomous vehicles typically use multiple sensors, like LiDAR (which uses laser light) and cameras, to perceive their surroundings. Earlier fusion approaches combined the sensor data right away, but the new VaLID method delays this fusion until after each sensor's detections have been individually verified.
The authors argue that verifying the detections first, before combining them, leads to more accurate and reliable object detection. This is because the verification step can catch and filter out any false positives or inaccurate detections from the individual sensors.
By carefully integrating the verified detections from both the LiDAR and camera, the overall perception of the vehicle's environment becomes more robust and trustworthy. This could translate to safer autonomous driving performance.
Technical Explanation
The key innovation in VaLID is its "verification as late integration" approach to LiDAR-camera fusion. Rather than fusing the sensor data right away, VaLID first independently verifies the detections from each modality before combining them.
The verification step employs a neural network that takes in features from both the LiDAR point cloud and camera image. It then outputs a confidence score indicating how likely each detection is to be a true positive. Only detections that pass this verification threshold are then integrated into the final fused output.
The authors show that this verification-before-fusion strategy outperforms earlier multimodal fusion techniques on standard benchmarks for 3D object detection. VaLID achieves higher accuracy while also being more robust to sensor failures or occlusions.
The paper also includes extensive experiments analyzing the contributions of the different components of the VaLID architecture. This provides insights into the importance of the verification step and how it enables more effective fusion of the complementary LiDAR and camera data.
Critical Analysis
The VaLID paper makes a compelling case for verification-based fusion as an improvement over earlier LiDAR-camera integration methods. The verification step appears to be a key innovation that enhances the overall robustness and accuracy of the system.
However, the paper does not fully explore the potential limitations or failure modes of the VaLID approach. For example, it does not discuss how the verification network might perform in highly complex or noisy environments, or how sensitive the method is to the quality/calibration of the input sensors.
Additionally, while the experimental results are strong, the paper could benefit from more analysis of the computational overhead and runtime performance of the VaLID architecture compared to alternatives. This would help assess its practical feasibility for real-world autonomous driving applications.
Overall, the VaLID method represents an interesting and promising advance in multimodal sensor fusion. Further research exploring its limitations and real-world tradeoffs could provide valuable insights for developing safer and more reliable autonomous vehicle perception systems.
Conclusion
The VaLID paper proposes a novel approach to fusing data from LiDAR and camera sensors in self-driving cars. By verifying detections from each modality before integrating them, the method aims to improve the accuracy and robustness of object recognition.
The key innovation is delaying the fusion step until after individual detections have been validated, in contrast to earlier fusion-first techniques. Experiments show VaLID outperforming other multimodal detection methods, suggesting the verification strategy is a valuable contribution.
While the paper provides strong technical results, further research is needed to fully understand the limitations and tradeoffs of the VaLID approach. Exploring its performance in challenging conditions and comparing its computational efficiency could yield important insights for deploying safer and more reliable autonomous vehicle perception systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VaLID: Verification as Late Integration of Detections for LiDAR-Camera Fusion
Vanshika Vats, Marzia Binta Nizam, James Davis
Vehicle object detection is possible using both LiDAR and camera data. Methods using LiDAR generally outperform those using cameras only. The highest accuracy methods utilize both of these modalities through data fusion. In our study, we propose a model-independent late fusion method, VaLID, which validates whether each predicted bounding box is acceptable or not. Our method verifies the higher-performing, yet overly optimistic LiDAR model detections using camera detections that are obtained from either specially trained, general, or open-vocabulary models. VaLID uses a simple multi-layer perceptron trained with a high recall bias to reduce the false predictions made by the LiDAR detector, while still preserving the true ones. Evaluating with multiple combinations of LiDAR and camera detectors on the KITTI dataset, we reduce false positives by an average of 63.9%, thus outperforming the individual detectors on 2D average precision (2DAP). Our approach is model-agnostic and demonstrates state-of-the-art competitive performance even when using generic camera detectors that were not trained specifically for this dataset.
Read more9/25/2024
✅
0
Validation & Exploration of Multimodal Deep-Learning Camera-Lidar Calibration models
Venkat Karramreddy, Liam Mitchell
This article presents an innovative study in exploring, evaluating, and implementing deep learning architectures for the calibration of multi-modal sensor systems. The focus behind this is to leverage the use of sensor fusion to achieve dynamic, real-time alignment between 3D LiDAR and 2D Camera sensors. static calibration methods are tedious and time-consuming, which is why we propose utilizing Conventional Neural Networks (CNN) coupled with geometrically informed learning to solve this issue. We leverage the foundational principles of Extrinsic LiDAR-Camera Calibration tools such as RegNet, CalibNet, and LCCNet by exploring open-source models that are available online and comparing our results with their corresponding research papers. Requirements for extracting these visual and measurable outputs involved tweaking source code, fine-tuning, training, validation, and testing for each of these frameworks for equal comparisons. This approach aims to investigate which of these advanced networks produces the most accurate and consistent predictions. Through a series of experiments, we reveal some of their shortcomings and areas for potential improvements along the way. We find that LCCNet yields the best results out of all the models that we validated.
Read more9/23/2024
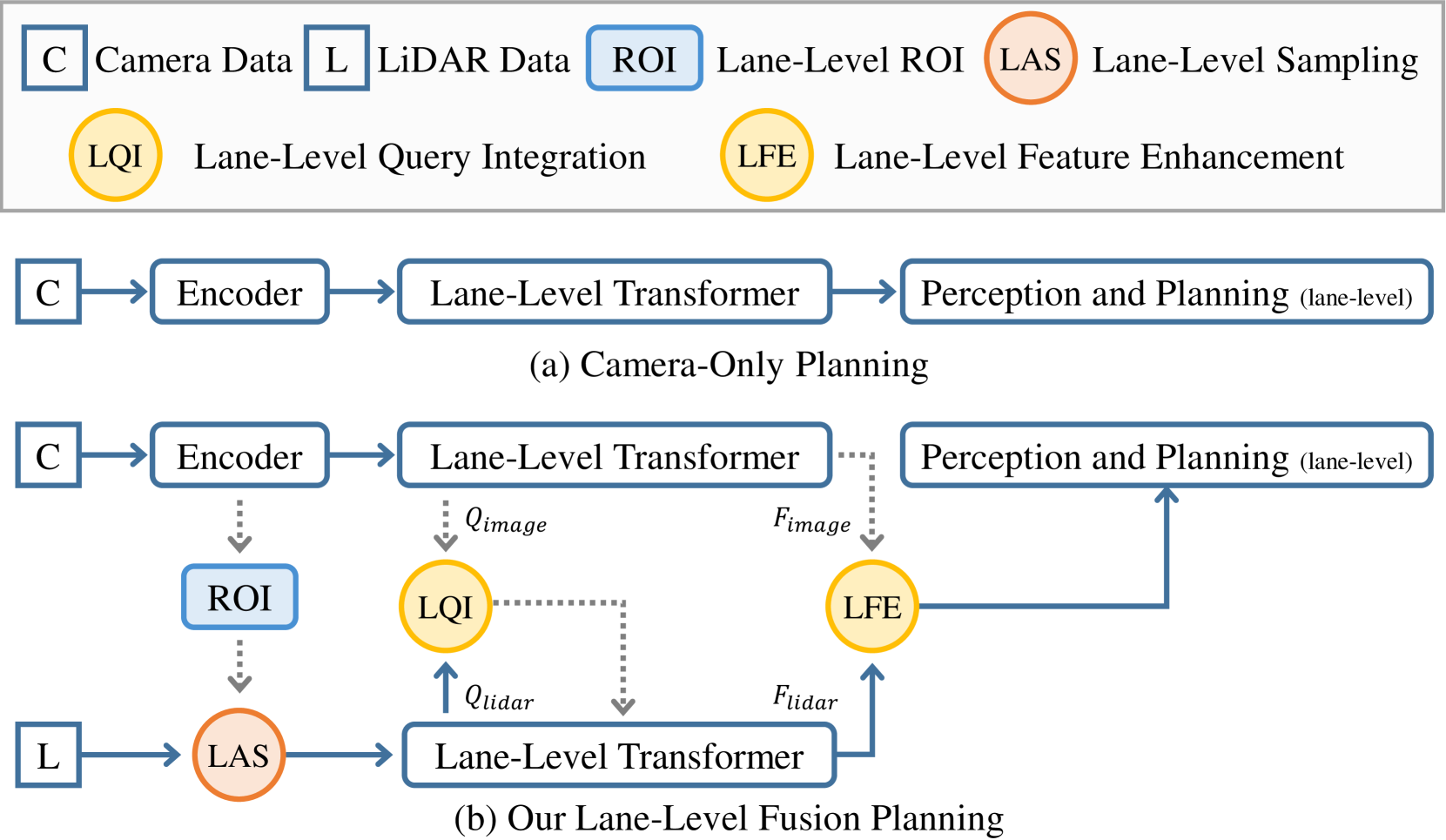
0
LFP: Efficient and Accurate End-to-End Lane-Level Planning via Camera-LiDAR Fusion
Guoliang You, Xiaomeng Chu, Yifan Duan, Xingchen Li, Sha Zhang, Jianmin Ji, Yanyong Zhang
Multi-modal systems enhance performance in autonomous driving but face inefficiencies due to indiscriminate processing within each modality. Additionally, the independent feature learning of each modality lacks interaction, which results in extracted features that do not possess the complementary characteristics. These issue increases the cost of fusing redundant information across modalities. To address these challenges, we propose targeting driving-relevant elements, which reduces the volume of LiDAR features while preserving critical information. This approach enhances lane level interaction between the image and LiDAR branches, allowing for the extraction and fusion of their respective advantageous features. Building upon the camera-only framework PHP, we introduce the Lane-level camera-LiDAR Fusion Planning (LFP) method, which balances efficiency with performance by using lanes as the unit for sensor fusion. Specifically, we design three modules to enhance efficiency and performance. For efficiency, we propose an image-guided coarse lane prior generation module that forecasts the region of interest (ROI) for lanes and assigns a confidence score, guiding LiDAR processing. The LiDAR feature extraction modules leverages lane-aware priors from the image branch to guide sampling for pillar, retaining essential pillars. For performance, the lane-level cross-modal query integration and feature enhancement module uses confidence score from ROI to combine low-confidence image queries with LiDAR queries, extracting complementary depth features. These features enhance the low-confidence image features, compensating for the lack of depth. Experiments on the Carla benchmarks show that our method achieves state-of-the-art performance in both driving score and infraction score, with maximum improvement of 15% and 14% over existing algorithms, respectively, maintaining high frame rate of 19.27 FPS.
Read more9/24/2024

0
Lift-Attend-Splat: Bird's-eye-view camera-lidar fusion using transformers
James Gunn, Zygmunt Lenyk, Anuj Sharma, Andrea Donati, Alexandru Buburuzan, John Redford, Romain Mueller
Combining complementary sensor modalities is crucial to providing robust perception for safety-critical robotics applications such as autonomous driving (AD). Recent state-of-the-art camera-lidar fusion methods for AD rely on monocular depth estimation which is a notoriously difficult task compared to using depth information from the lidar directly. Here, we find that this approach does not leverage depth as expected and show that naively improving depth estimation does not lead to improvements in object detection performance. Strikingly, we also find that removing depth estimation altogether does not degrade object detection performance substantially, suggesting that relying on monocular depth could be an unnecessary architectural bottleneck during camera-lidar fusion. In this work, we introduce a novel fusion method that bypasses monocular depth estimation altogether and instead selects and fuses camera and lidar features in a bird's-eye-view grid using a simple attention mechanism. We show that our model can modulate its use of camera features based on the availability of lidar features and that it yields better 3D object detection on the nuScenes dataset than baselines relying on monocular depth estimation.
Read more5/22/2024