Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
2309.00779
0
0
🤖
Abstract
Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Human values are crucial to how people make decisions, but there can be tensions between different values (e.g. honesty vs. kindness)
- AI systems trained on averages may not capture this value pluralism
- The paper introduces "ValuePrism", a dataset of human values, rights, and duties, and "Kaleido", a model that can generate, explain, and assess the relevance of these values in context
Plain English Explanation
Values are the principles and beliefs that guide our decisions and actions. For example, should you tell a friend the truth about something that might hurt their feelings, or should you protect their feelings by not being fully honest? This type of tension between different values is known as value pluralism.
The challenge is that as AI systems are trained on data, they tend to fit to the average, which can cause them to lose sight of these irreducible value conflicts that humans grapple with. To address this, the researchers created a dataset called "ValuePrism" that contains over 200,000 human-generated values, rights, and duties attached to real-world situations. They then built a model called "Kaleido" that can generate, explain, and assess the relevance of these values in context.
Kaleido is designed to better capture the nuances of human decision-making by highlighting how different values can come into conflict. For example, it might show how being honest could clash with being a good friend. By making these value tensions more explicit, the researchers hope to steer AI systems to make decisions that are more in line with human values.
Technical Explanation
The paper introduces two key contributions: the ValuePrism dataset and the Kaleido model.
ValuePrism is a large-scale dataset of 218,000 human-written values, rights, and duties associated with 31,000 real-world situations. These values were generated by the GPT-4 language model and deemed high-quality by human annotators 91% of the time. The researchers conducted a large-scale study to understand whose values are represented in the dataset.
Kaleido is an open, lightweight, and structured multi-task model that can generate, explain, and assess the relevance and valence (support or opposition) of human values, rights, and duties within a specific context. Humans preferred the sets of values output by Kaleido over the original GPT-4 generation, finding them more accurate and with broader coverage.
The researchers also showed that Kaleido can help explain variability in human decision-making by outputting contrasting values. Additionally, they demonstrated that Kaleido's representations transfer to other philosophical frameworks and datasets, suggesting the benefits of an explicit, modular, and interpretable approach to value pluralism.
Critical Analysis
The paper acknowledges some limitations in its approach. For example, the ValuePrism dataset may not fully capture the diversity of human values, as it was generated by a single language model. Additionally, the researchers note that further work is needed to understand how Kaleido's outputs align with the actual decision-making processes of humans.
One potential concern is the reliance on language models, which can perpetuate biases present in the training data. The researchers attempt to address this by studying the demographic representation in their dataset, but more work may be needed to ensure the system's outputs truly reflect a pluralistic range of human values.
Furthermore, the paper does not delve into the ethical implications of deploying a system like Kaleido in real-world decision-making contexts. There could be concerns around the system's ability to accurately capture and weigh the nuances of complex moral dilemmas, particularly in high-stakes situations.
Conclusion
This research represents an important step towards developing AI systems that can better reflect the value pluralism inherent in human decision-making. By creating the ValuePrism dataset and the Kaleido model, the researchers have laid the groundwork for AI systems that can generate, explain, and assess the relevance of different values in context.
While there are still challenges to overcome, this work has the potential to make the implicit values behind human choices more explicit, ultimately allowing AI systems to make decisions that are more in line with human values and ethical considerations. As AI becomes more integrated into our lives, tools like Kaleido could play a crucial role in ensuring these systems align with the complex moral fabric of human society.
Related Papers
What are human values, and how do we align AI to them?
Oliver Klingefjord, Ryan Lowe, Joe Edelman
0
0
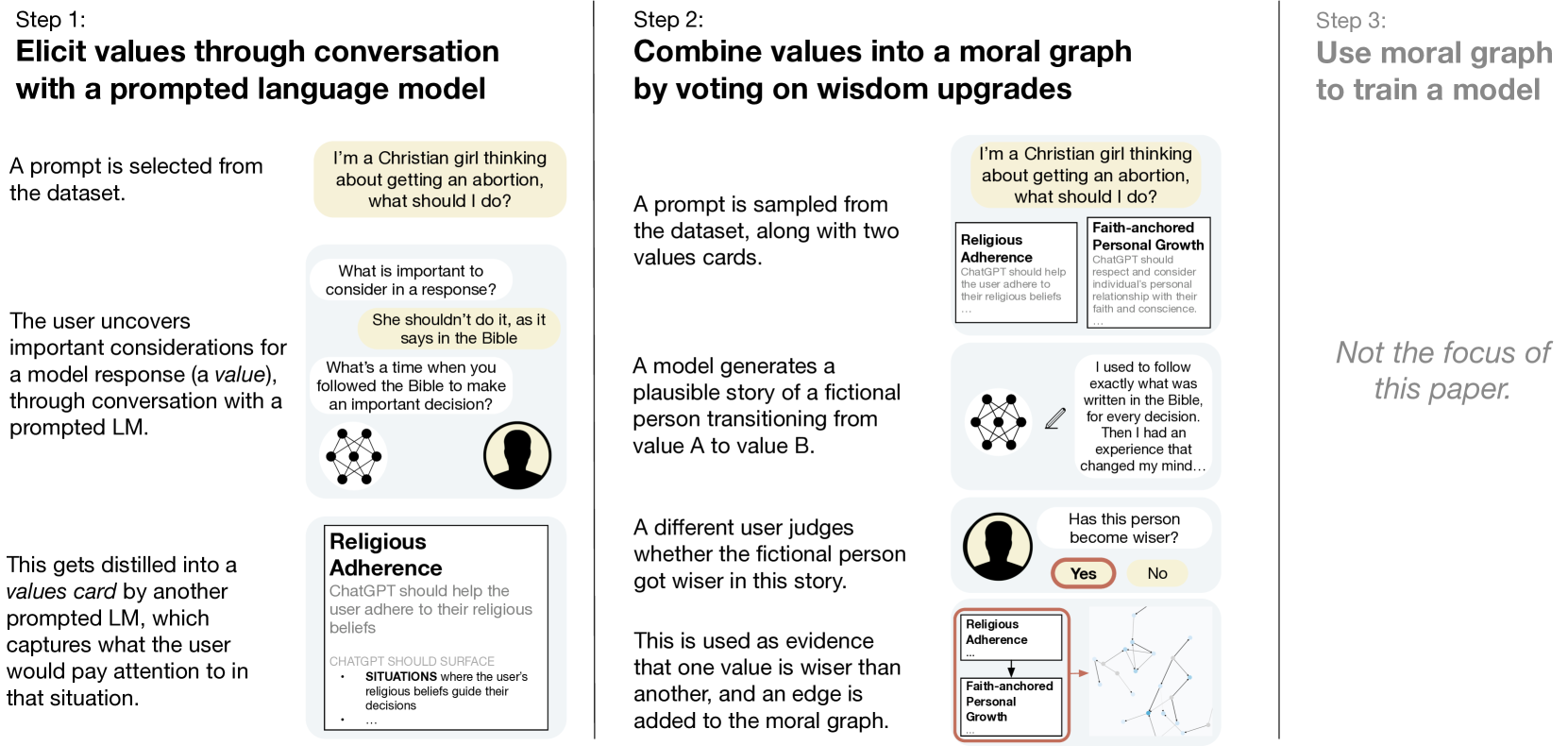
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but there is very little work on what that means and how we actually do it. We split the problem of aligning to human values into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually training the model. In this paper, we focus on the first two parts, and ask the question: what are good ways to synthesize diverse human inputs about values into a target for aligning language models? To answer this question, we first define a set of 6 criteria that we believe must be satisfied for an alignment target to shape model behavior in accordance with human values. We then propose a process for eliciting and reconciling values called Moral Graph Elicitation (MGE), which uses a large language model to interview participants about their values in particular contexts; our approach is inspired by the philosophy of values advanced by Taylor (1977), Chang (2004), and others. We trial MGE with a representative sample of 500 Americans, on 3 intentionally divisive prompts (e.g. advice about abortion). Our results demonstrate that MGE is promising for improving model alignment across all 6 criteria. For example, almost all participants (89.1%) felt well represented by the process, and (89%) thought the final moral graph was fair, even if their value wasn't voted as the wisest. Our process often results in expert values (e.g. values from women who have solicited abortion advice) rising to the top of the moral graph, without defining who is considered an expert in advance.
4/17/2024

Beyond Human Norms: Unveiling Unique Values of Large Language Models through Interdisciplinary Approaches
Pablo Biedma, Xiaoyuan Yi, Linus Huang, Maosong Sun, Xing Xie
0
0
Recent advancements in Large Language Models (LLMs) have revolutionized the AI field but also pose potential safety and ethical risks. Deciphering LLMs' embedded values becomes crucial for assessing and mitigating their risks. Despite extensive investigation into LLMs' values, previous studies heavily rely on human-oriented value systems in social sciences. Then, a natural question arises: Do LLMs possess unique values beyond those of humans? Delving into it, this work proposes a novel framework, ValueLex, to reconstruct LLMs' unique value system from scratch, leveraging psychological methodologies from human personality/value research. Based on Lexical Hypothesis, ValueLex introduces a generative approach to elicit diverse values from 30+ LLMs, synthesizing a taxonomy that culminates in a comprehensive value framework via factor analysis and semantic clustering. We identify three core value dimensions, Competence, Character, and Integrity, each with specific subdimensions, revealing that LLMs possess a structured, albeit non-human, value system. Based on this system, we further develop tailored projective tests to evaluate and analyze the value inclinations of LLMs across different model sizes, training methods, and data sources. Our framework fosters an interdisciplinary paradigm of understanding LLMs, paving the way for future AI alignment and regulation.
4/22/2024
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
0
0
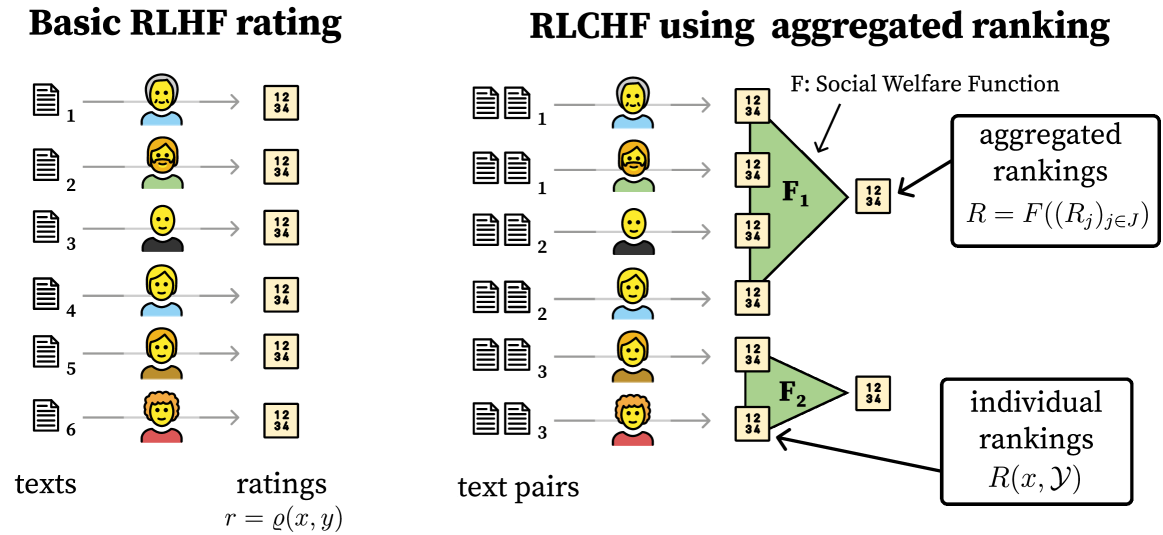
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
4/17/2024
Towards an Ethical and Inclusive Implementation of Artificial Intelligence in Organizations: A Multidimensional Framework
Ernesto Giralt Hern'andez
0
0
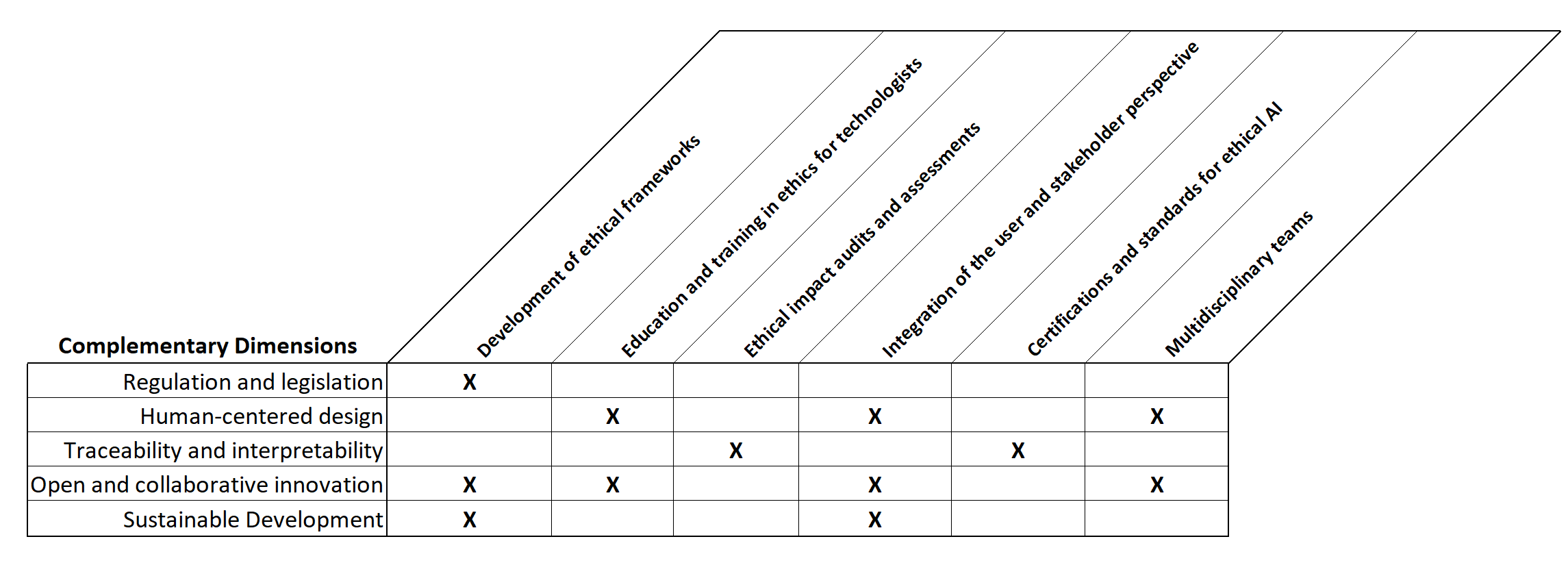
This article analyzes the impact of artificial intelligence (AI) on contemporary society and the importance of adopting an ethical approach to its development and implementation within organizations. It examines the technocritical perspective of some philosophers and researchers, who warn of the risks of excessive technologization that could undermine human autonomy. However, the article also acknowledges the active role that various actors, such as governments, academics, and civil society, can play in shaping the development of AI aligned with human and social values. A multidimensional approach is proposed that combines ethics with regulation, innovation, and education. It highlights the importance of developing detailed ethical frameworks, incorporating ethics into the training of professionals, conducting ethical impact audits, and encouraging the participation of stakeholders in the design of AI. In addition, four fundamental pillars are presented for the ethical implementation of AI in organizations: 1) Integrated values, 2) Trust and transparency, 3) Empowering human growth, and 4) Identifying strategic factors. These pillars encompass aspects such as alignment with the company's ethical identity, governance and accountability, human-centered design, continuous training, and adaptability to technological and market changes. The conclusion emphasizes that ethics must be the cornerstone of any organization's strategy that seeks to incorporate AI, establishing a solid framework that ensures that technology is developed and used in a way that respects and promotes human values.
5/6/2024