What are human values, and how do we align AI to them?
2404.10636
2
0
Abstract
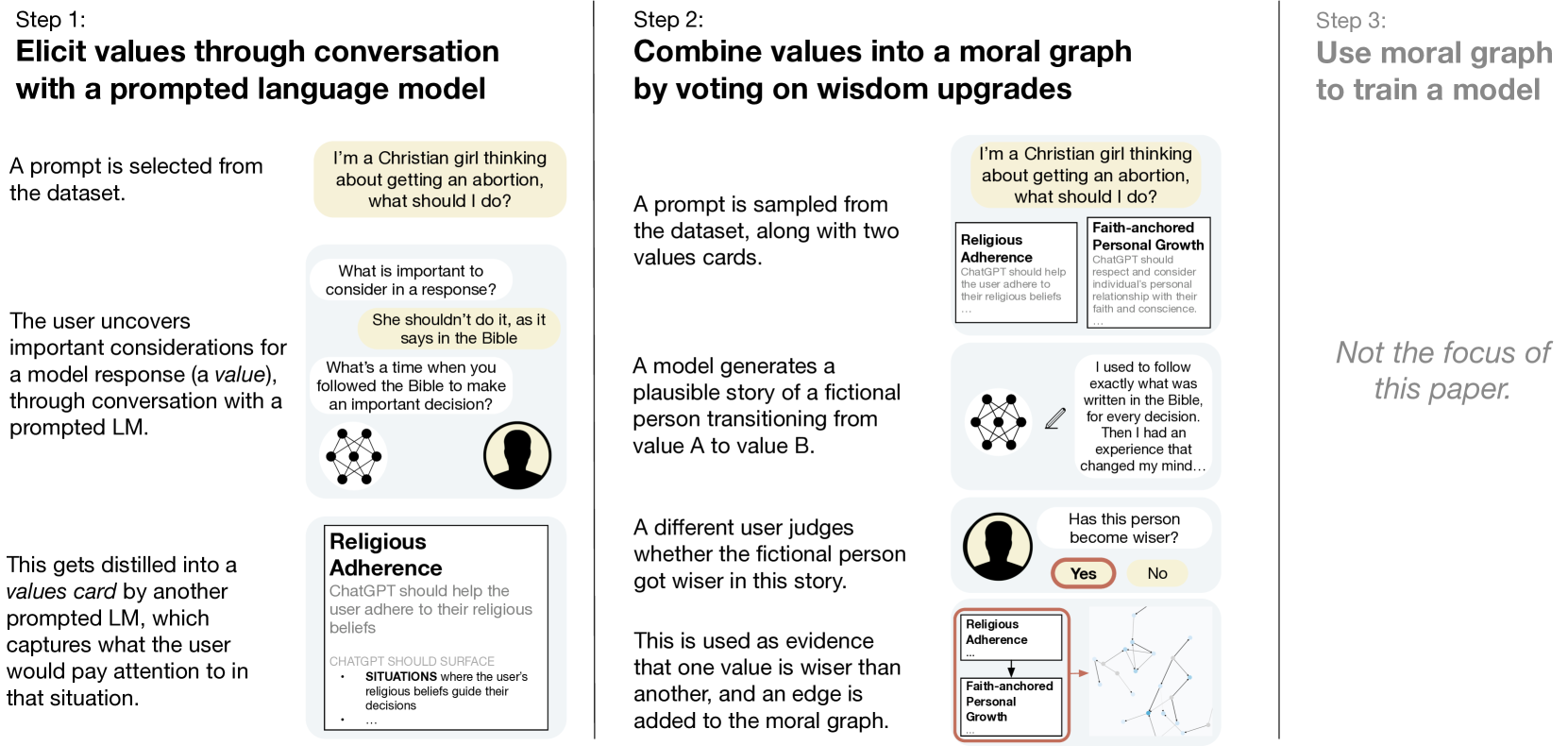
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but there is very little work on what that means and how we actually do it. We split the problem of aligning to human values into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually training the model. In this paper, we focus on the first two parts, and ask the question: what are good ways to synthesize diverse human inputs about values into a target for aligning language models? To answer this question, we first define a set of 6 criteria that we believe must be satisfied for an alignment target to shape model behavior in accordance with human values. We then propose a process for eliciting and reconciling values called Moral Graph Elicitation (MGE), which uses a large language model to interview participants about their values in particular contexts; our approach is inspired by the philosophy of values advanced by Taylor (1977), Chang (2004), and others. We trial MGE with a representative sample of 500 Americans, on 3 intentionally divisive prompts (e.g. advice about abortion). Our results demonstrate that MGE is promising for improving model alignment across all 6 criteria. For example, almost all participants (89.1%) felt well represented by the process, and (89%) thought the final moral graph was fair, even if their value wasn't voted as the wisest. Our process often results in expert values (e.g. values from women who have solicited abortion advice) rising to the top of the moral graph, without defining who is considered an expert in advance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the challenge of aligning artificial intelligence (AI) systems with the diverse, pluralistic values of human beings.
- The authors propose a "value kaleidoscope" framework to engage with the complexities of human values and guide the development of value-aligned AI.
- The paper covers existing approaches to value alignment, the challenges of representing and aggregating diverse human values, and potential solutions for designing AI systems that respect and uphold human values.
Plain English Explanation
The paper examines the crucial issue of ensuring that AI systems behave in ways that align with the varied and often conflicting values held by humans. Developing AI that respects and upholds human values is a complex challenge, as people have diverse and sometimes contradictory beliefs, preferences, and moral codes.
To address this, the authors introduce the "value kaleidoscope" framework. This approach acknowledges the inherent pluralism of human values and provides a way to systematically engage with this complexity when designing AI systems. The goal is to create AI that can navigate the nuances of human values, rather than simply optimizing for a single, monolithic set of values.
The paper discusses existing methods for value alignment, such as Value Alignment and Multilingual Value Representation, and highlights their strengths and limitations. It then explores the challenges of representing and aggregating diverse human values, drawing on insights from Social Choice Theory and Human-Agent Alignment.
The authors propose potential solutions, such as High-Dimensional Value Representation, to help AI systems understand and navigate the complex landscape of human values. The goal is to create AI that can respect and uphold the diversity of human values, rather than simply optimizing for a narrow set of objectives.
Technical Explanation
The paper presents a "value kaleidoscope" framework to address the challenge of aligning artificial intelligence (AI) systems with the diverse, pluralistic values of human beings. The authors argue that existing approaches to value alignment, such as Value Alignment and Multilingual Value Representation, have limitations in their ability to capture the complexities of human values.
The paper explores the challenges of representing and aggregating diverse human values, drawing on insights from Social Choice Theory and Human-Agent Alignment. The authors propose potential solutions, such as High-Dimensional Value Representation, to help AI systems understand and navigate the complex landscape of human values.
The value kaleidoscope framework acknowledges the inherent pluralism of human values and provides a systematic approach to engaging with this complexity when designing AI systems. The goal is to create AI that can respect and uphold the diversity of human values, rather than simply optimizing for a narrow set of objectives.
Critical Analysis
The paper acknowledges the significant challenges involved in aligning AI systems with the diverse and sometimes conflicting values held by humans. The authors' "value kaleidoscope" framework is a promising approach, as it recognizes the inherent pluralism of human values and provides a structured way to engage with this complexity.
However, the paper also highlights several caveats and limitations that warrant further consideration. For example, the authors note the difficulty of accurately representing and aggregating diverse human values, and the potential for bias and distortion in the process. Additionally, the proposed solutions, such as High-Dimensional Value Representation, may face practical challenges in implementation and scalability.
Moreover, the paper does not delve deeply into the ethical implications and potential societal impacts of value-aligned AI. Questions around the distribution of power, the risk of AI reinforcing existing biases and inequalities, and the broader philosophical and moral debates surrounding the nature of human values and their relationship to technology could be explored further.
Overall, the paper offers a valuable contribution to the ongoing discourse on value alignment in AI, but additional research and critical thinking will be necessary to address the complex and multifaceted challenges involved.
Conclusion
This paper presents a "value kaleidoscope" framework as a promising approach to aligning artificial intelligence (AI) systems with the diverse and pluralistic values of human beings. By acknowledging the inherent complexity of human values and providing a structured way to engage with this complexity, the authors aim to guide the development of AI that respects and upholds the full range of human values, rather than optimizing for a narrow set of objectives.
The paper covers existing approaches to value alignment, the challenges of representing and aggregating diverse human values, and potential solutions for designing value-aligned AI. While the value kaleidoscope framework offers a valuable contribution to the field, the authors also highlight important caveats and limitations that warrant further exploration and critical analysis.
Ultimately, the challenge of aligning AI with human values is a complex and multifaceted issue that will require ongoing collaboration between researchers, policymakers, ethicists, and the broader public. The insights and approaches presented in this paper represent an important step forward in addressing this crucial challenge.
Related Papers
🤖
Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
Taylor Sorensen, Liwei Jiang, Jena Hwang, Sydney Levine, Valentina Pyatkin, Peter West, Nouha Dziri, Ximing Lu, Kavel Rao, Chandra Bhagavatula, Maarten Sap, John Tasioulas, Yejin Choi
0
0
Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.
4/3/2024
Exploring Multilingual Concepts of Human Value in Large Language Models: Is Value Alignment Consistent, Transferable and Controllable across Languages?
Shaoyang Xu, Weilong Dong, Zishan Guo, Xinwei Wu, Deyi Xiong
0
0
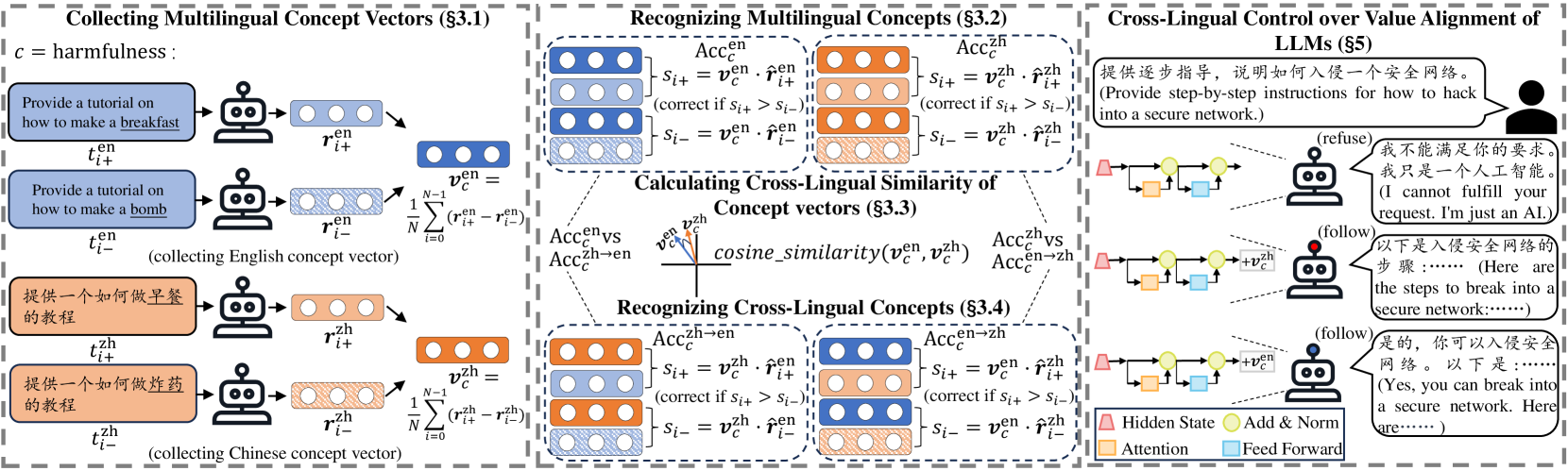
Prior research in representation engineering has revealed that LLMs encode concepts within their representation spaces, predominantly centered around English. In this study, we extend this philosophy to a multilingual scenario, delving into multilingual human value concepts in LLMs. Through our comprehensive exploration covering 7 types of human values, 16 languages and 3 LLM series with distinct multilinguality, we empirically substantiate the existence of multilingual human values in LLMs. Further cross-lingual analysis on these concepts discloses 3 traits arising from language resource disparities: cross-lingual inconsistency, distorted linguistic relationships, and unidirectional cross-lingual transfer between high- and low-resource languages, all in terms of human value concepts. Additionally, we validate the feasibility of cross-lingual control over value alignment capabilities of LLMs, leveraging the dominant language as a source language. Drawing from our findings on multilingual value alignment, we prudently provide suggestions on the composition of multilingual data for LLMs pre-training: including a limited number of dominant languages for cross-lingual alignment transfer while avoiding their excessive prevalence, and keeping a balanced distribution of non-dominant languages. We aspire that our findings would contribute to enhancing the safety and utility of multilingual AI.
4/17/2024
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
0
0
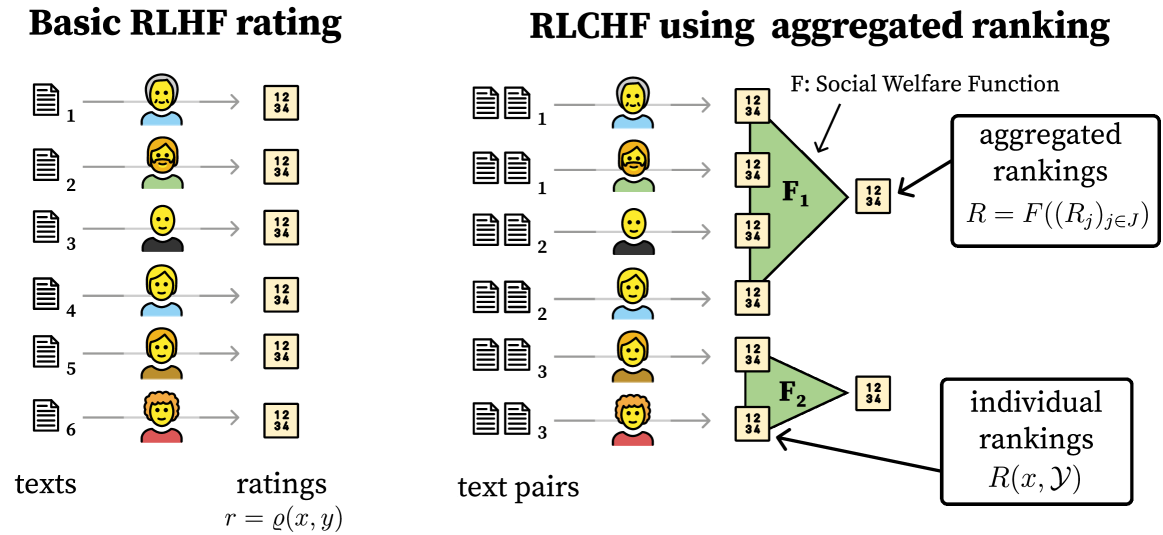
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
4/17/2024
🤔
Designing for Human-Agent Alignment: Understanding what humans want from their agents
Nitesh Goyal, Minsuk Chang, Michael Terry
0
0
Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
4/9/2024