Variable Time Step Reinforcement Learning for Robotic Applications
2407.00290
0
0

Abstract
Traditional reinforcement learning (RL) generates discrete control policies, assigning one action per cycle. These policies are usually implemented as in a fixed-frequency control loop. This rigidity presents challenges as optimal control frequency is task-dependent; suboptimal frequencies increase computational demands and reduce exploration efficiency. Variable Time Step Reinforcement Learning (VTS-RL) addresses these issues with adaptive control frequencies, executing actions only when necessary, thus reducing computational load and extending the action space to include action durations. In this paper we introduce the Multi-Objective Soft Elastic Actor-Critic (MOSEAC) method to perform VTS-RL, validating it through theoretical analysis and experimentation in simulation and on real robots. Results show faster convergence, better training results, and reduced energy consumption with respect to other variable- or fixed-frequency approaches.
Create account to get full access
Overview
- Introduces a new reinforcement learning approach called Variable Time Step Reinforcement Learning (VTS-RL) for robotic applications
- Aims to improve upon traditional fixed-time-step reinforcement learning by allowing the time step to vary during training and deployment
- Explores how variable time steps can enhance the performance and efficiency of reinforcement learning in robotic scenarios
Plain English Explanation
Reinforcement learning is a powerful technique used to train robots and other autonomous systems. In traditional reinforcement learning, the system learns by repeatedly trying different actions and receiving rewards or penalties. This learning process happens in small, fixed time steps.
Variable Time Step Reinforcement Learning (VTS-RL) proposes a different approach. Instead of using a fixed time step, the system is allowed to adjust the time step during training and deployment. This flexibility can lead to better performance and efficiency in robotic applications.
For example, imagine a robot learning to navigate a complex environment. With a fixed time step, the robot might struggle to learn the nuances of moving through tight spaces or making sharp turns. By using variable time steps, the robot can slow down and take smaller steps when navigating tricky areas, and then speed up when moving through open spaces. This allows the robot to learn and operate more effectively.
The paper explores how this variable time step approach can be implemented and optimized, with the goal of making reinforcement learning more practical and useful for real-world robotic systems.
Technical Explanation
The VTS-RL paper presents a novel reinforcement learning algorithm that allows the time step to vary during both the training and deployment phases. This is achieved by introducing a new variable, the "time step ratio," which determines the scaling factor for the current time step.
The authors propose several strategies for adapting the time step ratio, including using a separate neural network to predict the optimal ratio based on the current state of the system. They also explore techniques for optimizing the time step ratio to balance exploration, exploitation, and computational efficiency.
Experiments on a range of robotic tasks, such as pendulum swing-up and bipedal locomotion, demonstrate the advantages of VTS-RL over traditional fixed-time-step reinforcement learning. The results show that VTS-RL can achieve faster convergence, better performance, and more efficient use of computational resources.
Critical Analysis
The VTS-RL paper presents a compelling approach to improving the performance and practicality of reinforcement learning for robotic applications. The ability to dynamically adjust the time step is a promising idea that could unlock new possibilities in robot control and navigation.
However, the paper does not fully address the potential challenges and limitations of this approach. For instance, the authors do not delve deeply into the stability and convergence properties of VTS-RL, which could be crucial for real-world deployment. Additionally, the computational overhead of the time step prediction network may offset some of the efficiency gains, and the paper does not provide a comprehensive analysis of this trade-off.
Further research and experimentation are needed to fully understand the strengths and weaknesses of VTS-RL, as well as its applicability to a wider range of robotic systems and tasks. Nevertheless, the core idea of variable time step reinforcement learning is a valuable contribution to the field and merits further investigation.
Conclusion
The VTS-RL paper introduces a novel approach to reinforcement learning that allows the time step to vary during both training and deployment. This flexibility can lead to improved performance, efficiency, and practicality of reinforcement learning in robotic applications.
While the paper presents promising results, there are still some open questions and areas for further research. Nonetheless, the core concept of variable time step reinforcement learning is a valuable contribution to the field and has the potential to drive further advancements in robotics and autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MOSEAC: Streamlined Variable Time Step Reinforcement Learning
Dong Wang, Giovanni Beltrame
0
0
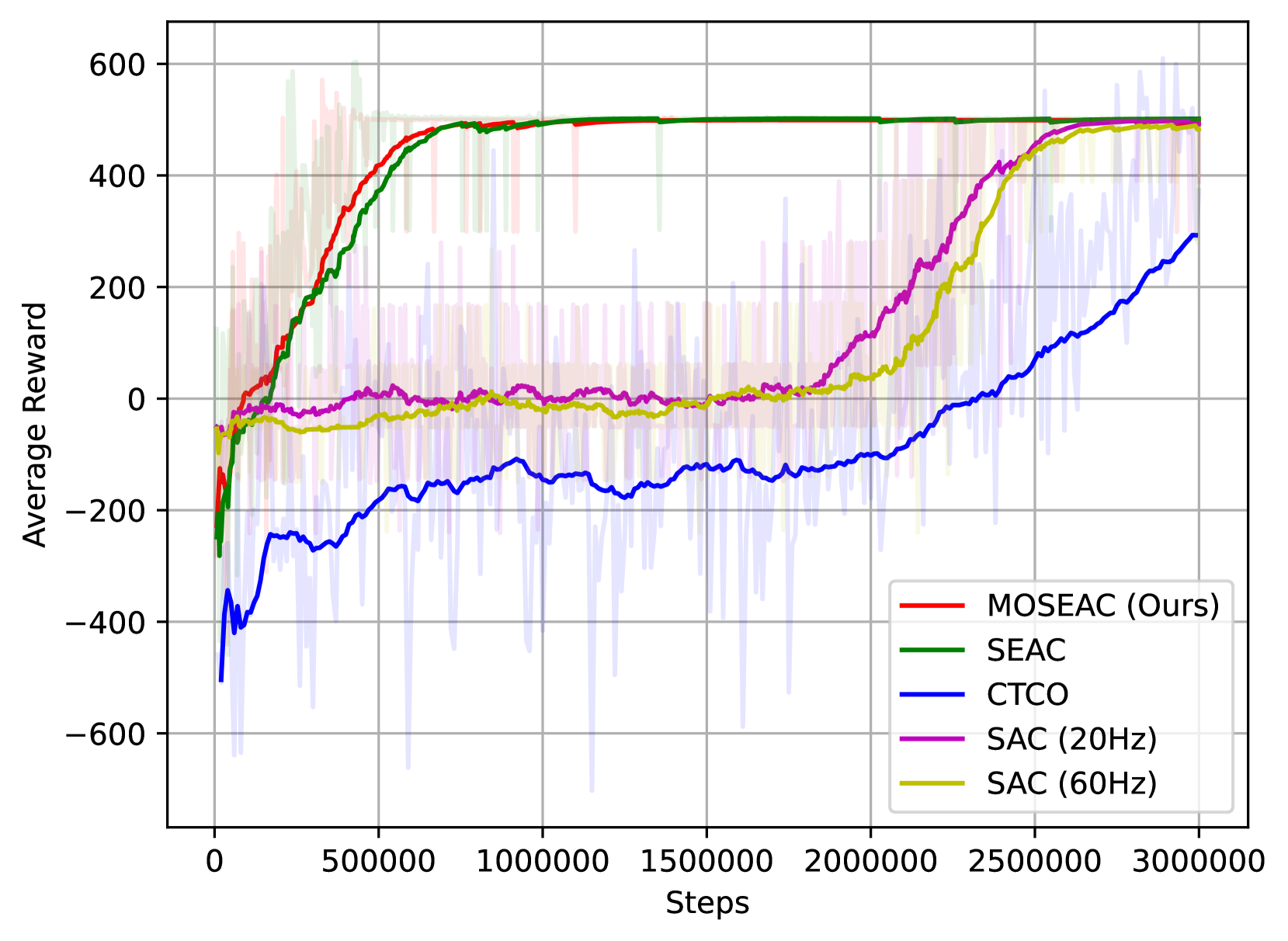
Traditional reinforcement learning (RL) methods typically employ a fixed control loop, where each cycle corresponds to an action. This rigidity poses challenges in practical applications, as the optimal control frequency is task-dependent. A suboptimal choice can lead to high computational demands and reduced exploration efficiency. Variable Time Step Reinforcement Learning (VTS-RL) addresses these issues by using adaptive frequencies for the control loop, executing actions only when necessary. This approach, rooted in reactive programming principles, reduces computational load and extends the action space by including action durations. However, VTS-RL's implementation is often complicated by the need to tune multiple hyperparameters that govern exploration in the multi-objective action-duration space (i.e., balancing task performance and number of time steps to achieve a goal). To overcome these challenges, we introduce the Multi-Objective Soft Elastic Actor-Critic (MOSEAC) method. This method features an adaptive reward scheme that adjusts hyperparameters based on observed trends in task rewards during training. This scheme reduces the complexity of hyperparameter tuning, requiring a single hyperparameter to guide exploration, thereby simplifying the learning process and lowering deployment costs. We validate the MOSEAC method through simulations in a Newtonian kinematics environment, demonstrating high task and training performance with fewer time steps, ultimately lowering energy consumption. This validation shows that MOSEAC streamlines RL algorithm deployment by automatically tuning the agent control loop frequency using a single parameter. Its principles can be applied to enhance any RL algorithm, making it a versatile solution for various applications.
6/4/2024
Reinforcement Learning with Elastic Time Steps
Dong Wang, Giovanni Beltrame
0
0
Traditional Reinforcement Learning (RL) policies are typically implemented with fixed control rates, often disregarding the impact of control rate selection. This can lead to inefficiencies as the optimal control rate varies with task requirements. We propose the Multi-Objective Soft Elastic Actor-Critic (MOSEAC), an off-policy actor-critic algorithm that uses elastic time steps to dynamically adjust the control frequency. This approach minimizes computational resources by selecting the lowest viable frequency. We show that MOSEAC converges and produces stable policies at the theoretical level, and validate our findings in a real-time 3D racing game. MOSEAC significantly outperformed other variable time step approaches in terms of energy efficiency and task effectiveness. Additionally, MOSEAC demonstrated faster and more stable training, showcasing its potential for real-world RL applications in robotics.
7/4/2024
Deployable Reinforcement Learning with Variable Control Rate
Dong Wang, Giovanni Beltrame
0
0
Deploying controllers trained with Reinforcement Learning (RL) on real robots can be challenging: RL relies on agents' policies being modeled as Markov Decision Processes (MDPs), which assume an inherently discrete passage of time. The use of MDPs results in that nearly all RL-based control systems employ a fixed-rate control strategy with a period (or time step) typically chosen based on the developer's experience or specific characteristics of the application environment. Unfortunately, the system should be controlled at the highest, worst-case frequency to ensure stability, which can demand significant computational and energy resources and hinder the deployability of the controller on onboard hardware. Adhering to the principles of reactive programming, we surmise that applying control actions only when necessary enables the use of simpler hardware and helps reduce energy consumption. We challenge the fixed frequency assumption by proposing a variant of RL with variable control rate. In this approach, the policy decides the action the agent should take as well as the duration of the time step associated with that action. In our new setting, we expand Soft Actor-Critic (SAC) to compute the optimal policy with a variable control rate, introducing the Soft Elastic Actor-Critic (SEAC) algorithm. We show the efficacy of SEAC through a proof-of-concept simulation driving an agent with Newtonian kinematics. Our experiments show higher average returns, shorter task completion times, and reduced computational resources when compared to fixed rate policies.
4/3/2024
Time-Varying Constraint-Aware Reinforcement Learning for Energy Storage Control
Jaeik Jeong, Tai-Yeon Ku, Wan-Ki Park
0
0
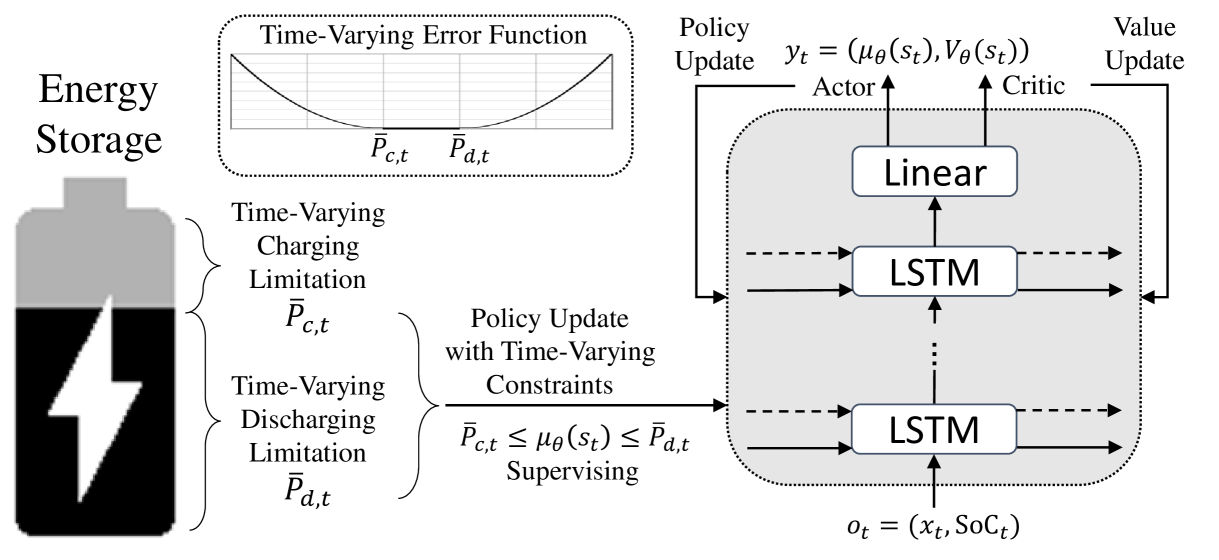
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, can help mitigate climate change by ensuring a more stable and sustainable power supply. To maximize the effectiveness of such energy storage, determining the appropriate charging and discharging amounts for each time period is crucial. Reinforcement learning is preferred over traditional optimization for the control of energy storage due to its ability to adapt to dynamic and complex environments. However, the continuous nature of charging and discharging levels in energy storage poses limitations for discrete reinforcement learning, and time-varying feasible charge-discharge range based on state of charge (SoC) variability also limits the conventional continuous reinforcement learning. In this paper, we propose a continuous reinforcement learning approach that takes into account the time-varying feasible charge-discharge range. An additional objective function was introduced for learning the feasible action range for each time period, supplementing the objectives of training the actor for policy learning and the critic for value learning. This actively promotes the utilization of energy storage by preventing them from getting stuck in suboptimal states, such as continuous full charging or discharging. This is achieved through the enforcement of the charging and discharging levels into the feasible action range. The experimental results demonstrated that the proposed method further maximized the effectiveness of energy storage by actively enhancing its utilization.
5/20/2024