Variational Delayed Policy Optimization
2405.14226
0
0
🛠️
Abstract
In environments with delayed observation, state augmentation by including actions within the delay window is adopted to retrieve Markovian property to enable reinforcement learning (RL). However, state-of-the-art (SOTA) RL techniques with Temporal-Difference (TD) learning frameworks often suffer from learning inefficiency, due to the significant expansion of the augmented state space with the delay. To improve learning efficiency without sacrificing performance, this work introduces a novel framework called Variational Delayed Policy Optimization (VDPO), which reformulates delayed RL as a variational inference problem. This problem is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. We not only provide a theoretical analysis of VDPO in terms of sample complexity and performance, but also empirically demonstrate that VDPO can achieve consistent performance with SOTA methods, with a significant enhancement of sample efficiency (approximately 50% less amount of samples) in the MuJoCo benchmark.
Create account to get full access
Overview
- Reinforcement learning (RL) in environments with delayed observations can be challenging due to the loss of Markovian property.
- State augmentation by including actions within the delay window is a common approach to restore Markovian property and enable RL.
- However, this can lead to a significant expansion of the state space, reducing the efficiency of state-of-the-art RL techniques like Temporal-Difference (TD) learning.
Plain English Explanation
In some situations, the effects of an agent's actions in an environment may not be observed immediately. This creates a delay between the action and the resulting observation. This delay can make it difficult for the agent to learn effectively using standard reinforcement learning (RL) techniques, as the connection between actions and their consequences becomes blurred.
To address this challenge, researchers have developed a approach called "state augmentation." This involves expanding the agent's state representation to include not just the current observation, but also the actions taken within the delay window. This helps restore the Markovian property, which is important for many RL algorithms to work effectively.
However, this state augmentation can significantly increase the size of the state space, making it much harder for the agent to learn efficiently. Standard RL techniques, such as Temporal-Difference (TD) learning, often struggle to cope with this expanded state space.
Technical Explanation
To improve learning efficiency without sacrificing performance, the researchers introduce a novel framework called Variational Delayed Policy Optimization (VDPO). VDPO reformulates the delayed RL problem as a variational inference problem, which is then modeled as a two-step iterative optimization process.
The first step involves TD learning in a delay-free environment with a smaller state space. The second step is a behavior cloning process, which can be addressed much more efficiently than the TD learning step.
The researchers provide a theoretical analysis of VDPO, examining its sample complexity and performance characteristics. They also empirically demonstrate that VDPO can achieve consistent performance with state-of-the-art methods, while significantly enhancing sample efficiency (approximately 50% less samples required) on the MuJoCo benchmark.
Critical Analysis
The researchers acknowledge that VDPO relies on the assumption that the delayed environment can be accurately modeled by a delay-free environment, which may not always be the case in practice. Additionally, the behavior cloning step may be challenging if the delayed environment exhibits complex dynamics or if the agent's policy is highly stochastic.
Further research could explore ways to relax these assumptions or develop more robust techniques to handle a wider range of delayed environments. Combining VDPO with other approaches, such as dynamic observation policies or policy optimization with smooth guidance, may also be a fruitful direction to improve the flexibility and performance of delayed RL systems.
Conclusion
The Variational Delayed Policy Optimization (VDPO) framework introduced in this work offers a promising approach to address the challenges of reinforcement learning in environments with delayed observations. By reformulating the problem as a variational inference task and leveraging a two-step optimization process, VDPO can significantly improve sample efficiency compared to state-of-the-art methods, without sacrificing overall performance.
This research highlights the potential of innovative problem formulations and optimization techniques to enhance the capabilities of reinforcement learning systems, particularly in complex, real-world scenarios where delayed observations are common. As the field of deep reinforcement learning continues to advance, frameworks like VDPO may pave the way for more efficient and robust RL agents to tackle a wider range of challenging tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Boosting Reinforcement Learning with Strongly Delayed Feedback Through Auxiliary Short Delays
Qingyuan Wu, Simon Sinong Zhan, Yixuan Wang, Yuhui Wang, Chung-Wei Lin, Chen Lv, Qi Zhu, Jurgen Schmidhuber, Chao Huang
0
0
Reinforcement learning (RL) is challenging in the common case of delays between events and their sensory perceptions. State-of-the-art (SOTA) state augmentation techniques either suffer from state space explosion or performance degeneration in stochastic environments. To address these challenges, we present a novel Auxiliary-Delayed Reinforcement Learning (AD-RL) method that leverages auxiliary tasks involving short delays to accelerate RL with long delays, without compromising performance in stochastic environments. Specifically, AD-RL learns a value function for short delays and uses bootstrapping and policy improvement techniques to adjust it for long delays. We theoretically show that this can greatly reduce the sample complexity. On deterministic and stochastic benchmarks, our method significantly outperforms the SOTAs in both sample efficiency and policy performance. Code is available at https://github.com/QingyuanWuNothing/AD-RL.
6/7/2024
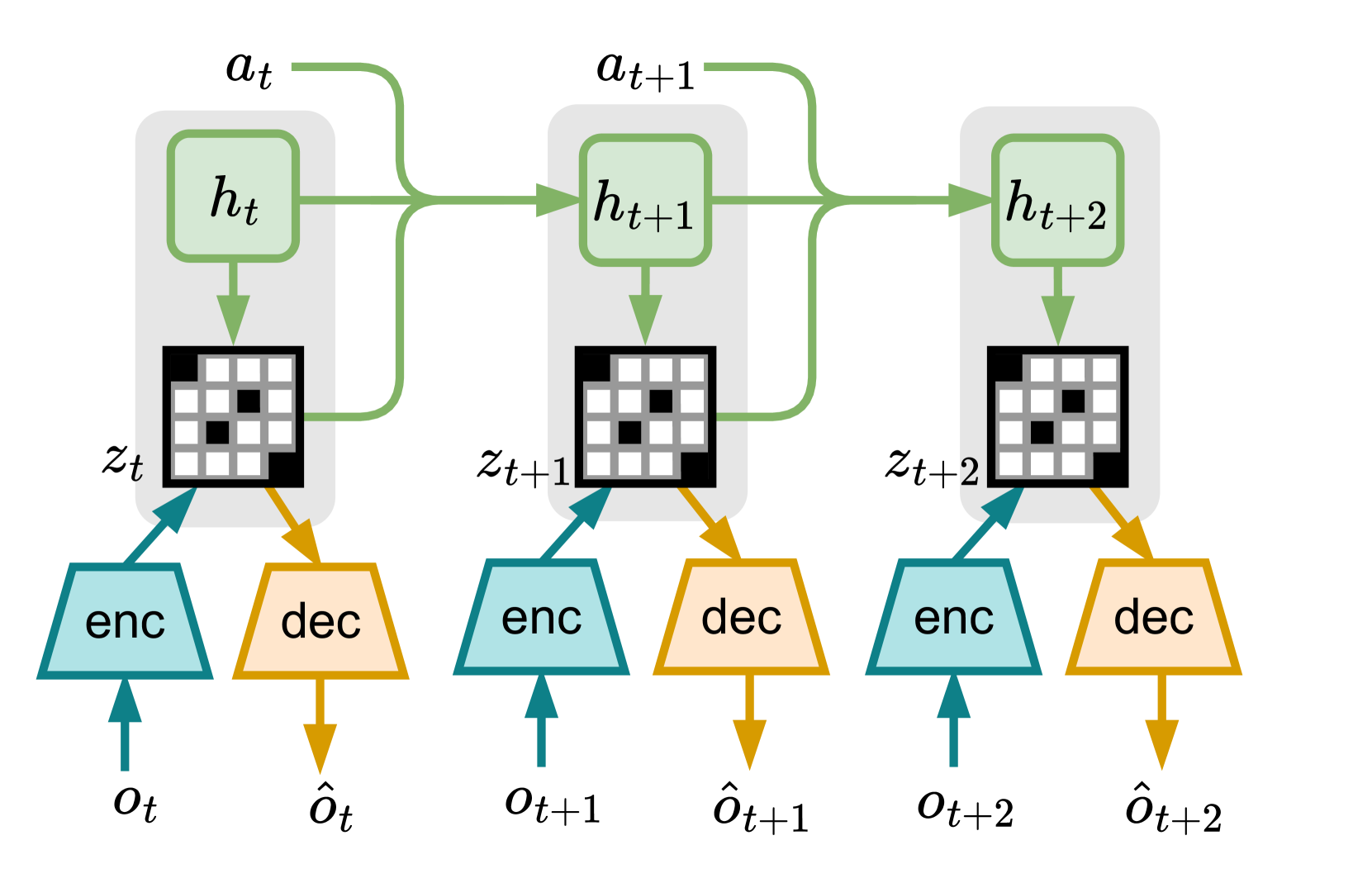
Reinforcement Learning from Delayed Observations via World Models
Armin Karamzade, Kyungmin Kim, Montek Kalsi, Roy Fox
0
0
In standard reinforcement learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of learning algorithms. In this paper, we address observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to 250%. Moreover, we evaluate our methods on visual delayed environments, for the first time showcasing delay-aware reinforcement learning continuous control with visual observations.
6/27/2024

Diffusion-based Reinforcement Learning via Q-weighted Variational Policy Optimization
Shutong Ding, Ke Hu, Zhenhao Zhang, Kan Ren, Weinan Zhang, Jingyi Yu, Jingya Wang, Ye Shi
0
0
Diffusion models have garnered widespread attention in Reinforcement Learning (RL) for their powerful expressiveness and multimodality. It has been verified that utilizing diffusion policies can significantly improve the performance of RL algorithms in continuous control tasks by overcoming the limitations of unimodal policies, such as Gaussian policies, and providing the agent with enhanced exploration capabilities. However, existing works mainly focus on the application of diffusion policies in offline RL, while their incorporation into online RL is less investigated. The training objective of the diffusion model, known as the variational lower bound, cannot be optimized directly in online RL due to the unavailability of 'good' actions. This leads to difficulties in conducting diffusion policy improvement. To overcome this, we propose a novel model-free diffusion-based online RL algorithm, Q-weighted Variational Policy Optimization (QVPO). Specifically, we introduce the Q-weighted variational loss, which can be proved to be a tight lower bound of the policy objective in online RL under certain conditions. To fulfill these conditions, the Q-weight transformation functions are introduced for general scenarios. Additionally, to further enhance the exploration capability of the diffusion policy, we design a special entropy regularization term. We also develop an efficient behavior policy to enhance sample efficiency by reducing the variance of the diffusion policy during online interactions. Consequently, the QVPO algorithm leverages the exploration capabilities and multimodality of diffusion policies, preventing the RL agent from converging to a sub-optimal policy. To verify the effectiveness of QVPO, we conduct comprehensive experiments on MuJoCo benchmarks. The final results demonstrate that QVPO achieves state-of-the-art performance on both cumulative reward and sample efficiency.
5/28/2024
🛠️
Tree Search-Based Policy Optimization under Stochastic Execution Delay
David Valensi, Esther Derman, Shie Mannor, Gal Dalal
0
0
The standard formulation of Markov decision processes (MDPs) assumes that the agent's decisions are executed immediately. However, in numerous realistic applications such as robotics or healthcare, actions are performed with a delay whose value can even be stochastic. In this work, we introduce stochastic delayed execution MDPs, a new formalism addressing random delays without resorting to state augmentation. We show that given observed delay values, it is sufficient to perform a policy search in the class of Markov policies in order to reach optimal performance, thus extending the deterministic fixed delay case. Armed with this insight, we devise DEZ, a model-based algorithm that optimizes over the class of Markov policies. DEZ leverages Monte-Carlo tree search similar to its non-delayed variant EfficientZero to accurately infer future states from the action queue. Thus, it handles delayed execution while preserving the sample efficiency of EfficientZero. Through a series of experiments on the Atari suite, we demonstrate that although the previous baseline outperforms the naive method in scenarios with constant delay, it underperforms in the face of stochastic delays. In contrast, our approach significantly outperforms the baselines, for both constant and stochastic delays. The code is available at http://github.com/davidva1/Delayed-EZ .
4/9/2024