Variational Inference Failures Under Model Symmetries: Permutation Invariant Posteriors for Bayesian Neural Networks

0

Sign in to get full access
Overview
- The paper discusses failures of variational inference under model symmetries, such as permutation invariance, in Bayesian neural networks.
- It proposes a novel approach to obtain permutation invariant posteriors that can better capture the symmetries inherent in the model.
- The proposed method aims to improve the performance and reliability of Bayesian deep learning models.
Plain English Explanation
Bayesian neural networks are a type of machine learning model that can provide estimates of the uncertainty in their predictions. One way to train these models is through a process called variational inference. However, the paper shows that variational inference can sometimes fail to capture the inherent symmetries present in the model, such as the fact that the order of the neurons in a neural network doesn't matter.
To address this issue, the paper introduces a new approach that ensures the posterior distribution (the model's beliefs after seeing the data) is invariant to these types of symmetries. This means the model's beliefs aren't affected by arbitrary rearrangements of the parameters. The authors demonstrate that this leads to more reliable and better-performing Bayesian neural networks, which could be important for applications where uncertainty quantification is crucial, such as in safety-critical systems.
Technical Explanation
The paper focuses on the problem of variational inference failing to capture the symmetries inherent in Bayesian neural network models. Specifically, it considers the case of permutation invariance, where the order of the neurons in a neural network doesn't affect the model's behavior.
The authors show that standard variational inference methods can produce posterior distributions that are not permutation invariant, even though the true posterior should be. This can lead to incorrect uncertainty estimates and poor model performance.
To address this issue, the paper proposes a novel approach called Permutation Invariant Variational Inference (PIVI). PIVI ensures that the variational posterior is permutation invariant by reparameterizing the model in a way that enforces this property. This is achieved by introducing a stochastic permutation layer that randomly shuffles the neurons during training, forcing the model to learn a permutation invariant representation.
The authors demonstrate the effectiveness of PIVI on several Bayesian neural network tasks, showing that it outperforms standard variational inference methods in terms of predictive performance and uncertainty quantification. They also provide theoretical analysis to justify the proposed approach.
Critical Analysis
The paper identifies an important problem in Bayesian deep learning and proposes a creative solution to address it. The authors provide a thorough technical explanation and experimental validation of their method.
One potential limitation is that the proposed PIVI approach may be computationally more expensive than standard variational inference, as it requires the introduction of the stochastic permutation layer. The authors acknowledge this and suggest that further research is needed to improve the efficiency of the method.
Additionally, the paper focuses primarily on the case of permutation invariance, but there may be other types of symmetries present in Bayesian neural networks that could also lead to issues with variational inference. Exploring the generalization of the PIVI approach to other symmetries could be an interesting direction for future work.
Conclusion
This paper makes a valuable contribution to the field of Bayesian deep learning by addressing a fundamental problem with variational inference under model symmetries. The proposed PIVI method provides a principled way to obtain permutation invariant posteriors, leading to improved predictive performance and reliable uncertainty quantification.
The insights and techniques presented in this work could have important implications for the development of robust and trustworthy Bayesian neural network models, particularly in safety-critical applications where uncertainty estimation is crucial. The paper also highlights the importance of considering the inherent symmetries of a model when designing inference algorithms, a consideration that may become increasingly important as the complexity of deep learning models continues to grow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Variational Inference Failures Under Model Symmetries: Permutation Invariant Posteriors for Bayesian Neural Networks
Yoav Gelberg, Tycho F. A. van der Ouderaa, Mark van der Wilk, Yarin Gal
Weight space symmetries in neural network architectures, such as permutation symmetries in MLPs, give rise to Bayesian neural network (BNN) posteriors with many equivalent modes. This multimodality poses a challenge for variational inference (VI) techniques, which typically rely on approximating the posterior with a unimodal distribution. In this work, we investigate the impact of weight space permutation symmetries on VI. We demonstrate, both theoretically and empirically, that these symmetries lead to biases in the approximate posterior, which degrade predictive performance and posterior fit if not explicitly accounted for. To mitigate this behavior, we leverage the symmetric structure of the posterior and devise a symmetrization mechanism for constructing permutation invariant variational posteriors. We show that the symmetrized distribution has a strictly better fit to the true posterior, and that it can be trained using the original ELBO objective with a modified KL regularization term. We demonstrate experimentally that our approach mitigates the aforementioned biases and results in improved predictions and a higher ELBO.
Read more8/13/2024
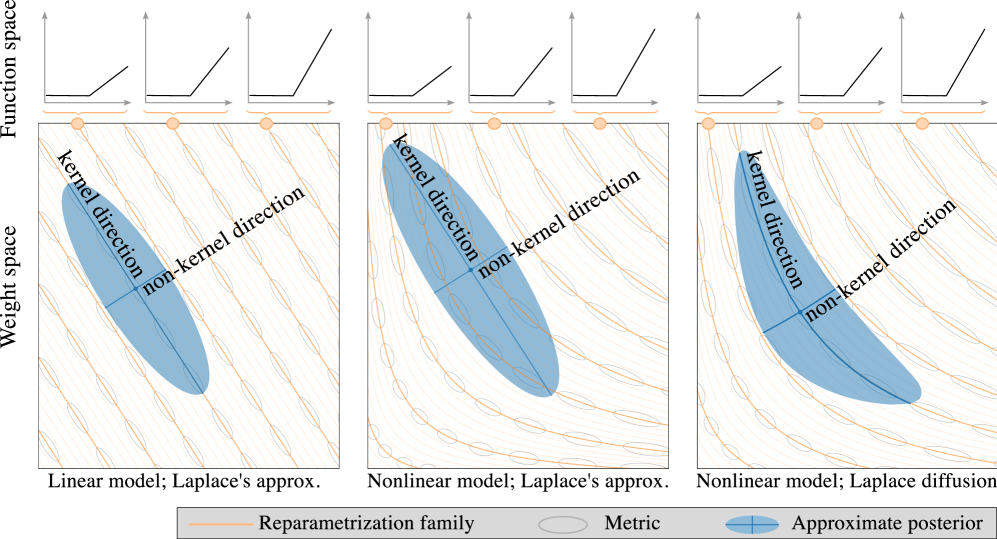
0
Reparameterization invariance in approximate Bayesian inference
Hrittik Roy, Marco Miani, Carl Henrik Ek, Philipp Hennig, Marvin Pfortner, Lukas Tatzel, S{o}ren Hauberg
Current approximate posteriors in Bayesian neural networks (BNNs) exhibit a crucial limitation: they fail to maintain invariance under reparameterization, i.e. BNNs assign different posterior densities to different parametrizations of identical functions. This creates a fundamental flaw in the application of Bayesian principles as it breaks the correspondence between uncertainty over the parameters with uncertainty over the parametrized function. In this paper, we investigate this issue in the context of the increasingly popular linearized Laplace approximation. Specifically, it has been observed that linearized predictives alleviate the common underfitting problems of the Laplace approximation. We develop a new geometric view of reparametrizations from which we explain the success of linearization. Moreover, we demonstrate that these reparameterization invariance properties can be extended to the original neural network predictive using a Riemannian diffusion process giving a straightforward algorithm for approximate posterior sampling, which empirically improves posterior fit.
Read more6/6/2024

0
Regularized KL-Divergence for Well-Defined Function-Space Variational Inference in Bayesian neural networks
Tristan Cinquin, Robert Bamler
Bayesian neural networks (BNN) promise to combine the predictive performance of neural networks with principled uncertainty modeling important for safety-critical systems and decision making. However, posterior uncertainty estimates depend on the choice of prior, and finding informative priors in weight-space has proven difficult. This has motivated variational inference (VI) methods that pose priors directly on the function generated by the BNN rather than on weights. In this paper, we address a fundamental issue with such function-space VI approaches pointed out by Burt et al. (2020), who showed that the objective function (ELBO) is negative infinite for most priors of interest. Our solution builds on generalized VI (Knoblauch et al., 2019) with the regularized KL divergence (Quang, 2019) and is, to the best of our knowledge, the first well-defined variational objective for function-space inference in BNNs with Gaussian process (GP) priors. Experiments show that our method incorporates the properties specified by the GP prior on synthetic and small real-world data sets, and provides competitive uncertainty estimates for regression, classification and out-of-distribution detection compared to BNN baselines with both function and weight-space priors.
Read more7/22/2024

0
Structured Partial Stochasticity in Bayesian Neural Networks
Tommy Rochussen
Bayesian neural network posterior distributions have a great number of modes that correspond to the same network function. The abundance of such modes can make it difficult for approximate inference methods to do their job. Recent work has demonstrated the benefits of partial stochasticity for approximate inference in Bayesian neural networks; inference can be less costly and performance can sometimes be improved. I propose a structured way to select the deterministic subset of weights that removes neuron permutation symmetries, and therefore the corresponding redundant posterior modes. With a drastically simplified posterior distribution, the performance of existing approximate inference schemes is found to be greatly improved.
Read more5/29/2024