Reparameterization invariance in approximate Bayesian inference

0
Sign in to get full access
Overview
• This paper investigates the concept of "reparameterization invariance" in the context of approximate Bayesian inference, specifically focusing on the Laplace approximation method.
• The Laplace approximation is a technique used to approximate the posterior distribution in Bayesian inference problems when the true posterior is intractable to compute.
• The authors explore how the choice of parameterization can impact the accuracy and reliability of the Laplace approximation, and they provide theoretical and empirical results to address this issue.
Plain English Explanation
Bayesian inference is a powerful statistical method that allows us to update our beliefs about the world based on observed data. However, in many real-world problems, the underlying mathematical equations can be quite complex, making it difficult to compute the exact posterior distribution (the updated beliefs) that we're interested in.
The Laplace approximation is a technique that can be used to approximate the posterior distribution in these cases. It works by fitting a Gaussian (normal) distribution to the true posterior, which allows us to represent the distribution using just a few key parameters.
The key insight of this paper is that the choice of how we parameterize (or represent) the problem can have a big impact on the accuracy of the Laplace approximation. Imagine you're trying to fit a Gaussian to a highly asymmetric posterior distribution - if you choose the wrong way to represent the problem, the Gaussian may be a poor fit, and your approximation will be inaccurate.
The authors show that by using a "reparameterization" - that is, a different way of representing the problem - we can often improve the accuracy of the Laplace approximation, even for complex Bayesian inference problems. This is an important result, as it means we can make Bayesian inference more practical and reliable in a wider range of applications, from Bayesian neural networks to Bayesian inverse problems.
Technical Explanation
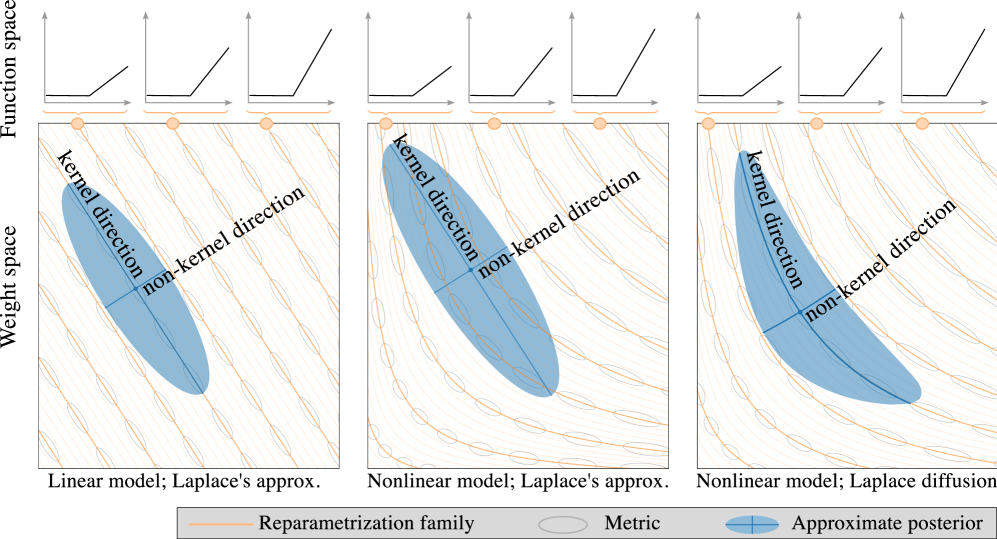
The key technical insight of this paper is that the Laplace approximation, a widely used method for approximate Bayesian inference, is not invariant to the choice of parameterization of the problem. In other words, the accuracy of the Laplace approximation can be highly dependent on how the problem is represented mathematically.
The authors provide both theoretical and empirical analysis to demonstrate this phenomenon. Theoretically, they show that the Laplace approximation can be reparameterization-dependent, meaning that the quality of the approximation can change significantly if the problem is represented using a different set of parameters.
Empirically, the authors test the Laplace approximation on a variety of Bayesian inference problems, including Bayesian regression and Bayesian neural networks. They demonstrate that by using a carefully chosen reparameterization, they can substantially improve the accuracy of the Laplace approximation compared to the standard parameterization.
The implications of this work are significant, as the Laplace approximation is a widely used technique in Bayesian inference and machine learning. By understanding the reparameterization dependence of the Laplace approximation, practitioners can make more informed choices about how to represent their problems, leading to more reliable and accurate Bayesian inference results.
Critical Analysis
The authors have provided a thorough and rigorous analysis of the reparameterization dependence of the Laplace approximation, with both theoretical and empirical support. However, there are a few potential limitations and areas for further research that could be considered:
-
The paper focuses on the Laplace approximation, but there are other approximate Bayesian inference methods (e.g., variational inference, Markov Chain Monte Carlo) that may also exhibit reparameterization dependence. It would be interesting to see if the insights from this paper extend to these other techniques as well.
-
The empirical results are limited to a few specific problem domains (regression, neural networks). It would be valuable to test the reparameterization approach on a wider range of Bayesian inference problems to further validate the generality of the findings.
-
The paper does not provide explicit guidelines or heuristics for choosing an optimal reparameterization in practice. Developing such guidelines could make the insights from this work more directly applicable for practitioners.
-
The theoretical analysis relies on certain assumptions and approximations. It would be interesting to explore the robustness of the results to relaxing these assumptions or considering alternative theoretical frameworks.
Despite these potential avenues for further research, this paper provides an important contribution to the understanding of approximate Bayesian inference methods and their sensitivity to the choice of parameterization. The insights from this work can help guide researchers and practitioners towards more reliable and accurate Bayesian inference in a variety of applications.
Conclusion
This paper highlights a crucial but often overlooked issue in approximate Bayesian inference: the sensitivity of the Laplace approximation to the choice of parameterization. By demonstrating both theoretically and empirically that the Laplace approximation can be reparameterization-dependent, the authors have shed light on an important limitation of this widely used technique.
The implications of this work are significant, as the Laplace approximation is a cornerstone of Bayesian inference in many fields, from machine learning to scientific modeling. By understanding the reparameterization dependence, practitioners can make more informed choices about how to represent their problems, leading to more reliable and accurate Bayesian inference results.
Overall, this paper makes an important contribution to the field of approximate Bayesian inference, and the insights it provides can help advance the state of the art in a wide range of applications that rely on Bayesian methods.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reparameterization invariance in approximate Bayesian inference
Hrittik Roy, Marco Miani, Carl Henrik Ek, Philipp Hennig, Marvin Pfortner, Lukas Tatzel, S{o}ren Hauberg
Current approximate posteriors in Bayesian neural networks (BNNs) exhibit a crucial limitation: they fail to maintain invariance under reparameterization, i.e. BNNs assign different posterior densities to different parametrizations of identical functions. This creates a fundamental flaw in the application of Bayesian principles as it breaks the correspondence between uncertainty over the parameters with uncertainty over the parametrized function. In this paper, we investigate this issue in the context of the increasingly popular linearized Laplace approximation. Specifically, it has been observed that linearized predictives alleviate the common underfitting problems of the Laplace approximation. We develop a new geometric view of reparametrizations from which we explain the success of linearization. Moreover, we demonstrate that these reparameterization invariance properties can be extended to the original neural network predictive using a Riemannian diffusion process giving a straightforward algorithm for approximate posterior sampling, which empirically improves posterior fit.
Read more6/6/2024
📶
0
Generalized Laplace Approximation
Yinsong Chen, Samson S. Yu, Zhong Li, Chee Peng Lim
In recent years, the inconsistency in Bayesian deep learning has garnered increasing attention. Tempered or generalized posterior distributions often offer a direct and effective solution to this issue. However, understanding the underlying causes and evaluating the effectiveness of generalized posteriors remain active areas of research. In this study, we introduce a unified theoretical framework to attribute Bayesian inconsistency to model misspecification and inadequate priors. We interpret the generalization of the posterior with a temperature factor as a correction for misspecified models through adjustments to the joint probability model, and the recalibration of priors by redistributing probability mass on models within the hypothesis space using data samples. Additionally, we highlight a distinctive feature of Laplace approximation, which ensures that the generalized normalizing constant can be treated as invariant, unlike the typical scenario in general Bayesian learning where this constant varies with model parameters post-generalization. Building on this insight, we propose the generalized Laplace approximation, which involves a simple adjustment to the computation of the Hessian matrix of the regularized loss function. This method offers a flexible and scalable framework for obtaining high-quality posterior distributions. We assess the performance and properties of the generalized Laplace approximation on state-of-the-art neural networks and real-world datasets.
Read more5/27/2024
0
Bayesian Inference for Consistent Predictions in Overparameterized Nonlinear Regression
Tomoya Wakayama
The remarkable generalization performance of large-scale models has been challenging the conventional wisdom of the statistical learning theory. Although recent theoretical studies have shed light on this behavior in linear models and nonlinear classifiers, a comprehensive understanding of overparameterization in nonlinear regression models is still lacking. This study explores the predictive properties of overparameterized nonlinear regression within the Bayesian framework, extending the methodology of the adaptive prior considering the intrinsic spectral structure of the data. Posterior contraction is established for generalized linear and single-neuron models with Lipschitz continuous activation functions, demonstrating the consistency in the predictions of the proposed approach. Moreover, the Bayesian framework enables uncertainty estimation of the predictions. The proposed method was validated via numerical simulations and a real data application, showing its ability to achieve accurate predictions and reliable uncertainty estimates. This work provides a theoretical understanding of the advantages of overparameterization and a principled Bayesian approach to large nonlinear models.
Read more6/18/2024

0
Variational Inference Failures Under Model Symmetries: Permutation Invariant Posteriors for Bayesian Neural Networks
Yoav Gelberg, Tycho F. A. van der Ouderaa, Mark van der Wilk, Yarin Gal
Weight space symmetries in neural network architectures, such as permutation symmetries in MLPs, give rise to Bayesian neural network (BNN) posteriors with many equivalent modes. This multimodality poses a challenge for variational inference (VI) techniques, which typically rely on approximating the posterior with a unimodal distribution. In this work, we investigate the impact of weight space permutation symmetries on VI. We demonstrate, both theoretically and empirically, that these symmetries lead to biases in the approximate posterior, which degrade predictive performance and posterior fit if not explicitly accounted for. To mitigate this behavior, we leverage the symmetric structure of the posterior and devise a symmetrization mechanism for constructing permutation invariant variational posteriors. We show that the symmetrized distribution has a strictly better fit to the true posterior, and that it can be trained using the original ELBO objective with a modified KL regularization term. We demonstrate experimentally that our approach mitigates the aforementioned biases and results in improved predictions and a higher ELBO.
Read more8/13/2024