vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention

0
⛏️
Sign in to get full access
Overview
- Efficient GPU memory usage is crucial for high-throughput large language model (LLM) inference.
- Prior systems reserved memory for the Key-Value (KV) cache ahead-of-time, leading to wasted capacity due to internal fragmentation.
- vLLM proposed PagedAttention to enable dynamic memory allocation for the KV cache, eliminating fragmentation and enabling larger batch sizes.
- However, PagedAttention requires attention kernels to be rewritten and the serving framework to implement a memory manager, leading to software complexity, portability issues, redundancy, and inefficiency.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. To run these models efficiently, it's important to use the available graphics processing unit (GPU) memory effectively. In the past, LLM systems have reserved memory for a part of the model called the "key-value cache" ahead of time, but this led to wasted memory due to internal fragmentation.
To address this, researchers developed a system called vLLM that uses a technique called "PagedAttention" to dynamically allocate memory for the key-value cache as needed. This eliminates the fragmentation problem and allows for larger batch sizes, which can improve the overall speed of the LLM.
However, the PagedAttention approach has some downsides. It requires the attention kernels (the core algorithms that power the LLM) to be rewritten to support paging, and the serving framework (the software that runs the LLM) to implement a memory management system. This added complexity can lead to issues with software portability, redundancy, and inefficiency.
Technical Explanation
The paper proposes a new system called "vAttention" that addresses the limitations of the PagedAttention approach. Instead of changing the layout of the key-value cache to non-contiguous virtual memory, vAttention retains the cache in contiguous virtual memory and leverages low-level system support for demand paging to enable on-demand physical memory allocation.
This approach has several advantages:
- Unchanged attention kernels: vAttention allows attention kernels to remain unchanged, as the underlying system support for paging is handled transparently.
- Avoid re-implementation of memory management: The serving framework does not need to implement a custom memory manager, as it can rely on the existing system-level support for paging.
- Improved performance: vAttention generates tokens up to 1.97x faster than vLLM and processes input prompts up to 3.92x and 1.45x faster than the PagedAttention variants of FlashAttention and FlashInfer, respectively.
Critical Analysis
The paper provides a compelling solution to the problem of efficient GPU memory management for LLM inference. By leveraging existing system-level support for demand paging, vAttention avoids the complexities and drawbacks of the PagedAttention approach.
However, the paper does not address potential issues that may arise from the reliance on system-level paging. For example, the performance and reliability of the paging mechanism may vary across different hardware and software environments, which could impact the overall performance and stability of the LLM serving system.
Additionally, the paper focuses on the key-value cache, but there may be other memory-intensive components in LLMs that could benefit from similar dynamic memory management techniques. Further research could explore the applicability of the vAttention approach to other parts of the LLM architecture, such as the attention computations themselves or the input/output handling.
Conclusion
The vAttention system proposed in this paper represents a significant advancement in the efficient use of GPU memory for high-throughput LLM inference. By leveraging existing system-level support for demand paging, vAttention avoids the complexities and drawbacks of the previous PagedAttention approach, while delivering substantial performance improvements.
This work highlights the importance of exploring low-level system-level optimizations to enhance the performance and scalability of large-scale AI models. As the field of LLMs continues to evolve, further research in this direction could lead to even more efficient and robust inference systems, paving the way for the widespread deployment of these powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, Ashish Panwar
Efficient management of GPU memory is essential for high throughput LLM inference. Prior systems used to reserve KV-cache memory ahead-of-time that resulted in wasted capacity due to internal fragmentation. Inspired by demand paging, vLLM proposed PagedAttention to enable dynamic memory allocation for KV-cache. This approach eliminates fragmentation and improves serving throughout. However, to be able to allocate physical memory dynamically, PagedAttention changes the layout of KV-cache from contiguous virtual memory to non-contiguous virtual memory. As a consequence, one needs to rewrite the attention kernels to support paging, and implement a memory manager in the serving framework. This results in both performance and programming overheads, as well as portability challenges in adopting state-of-the-art attention kernels. In this paper, we propose vAttention, a new approach for dynamic KV-cache memory management. In contrast to PagedAttention, vAttention stores KV-cache in contiguous virtual memory and leverages OS support for on-demand allocation of physical memory. vAttention thus enables one to use state-of-the art attention kernels out-of-the-box by adding support for dynamic allocation of physical memory without having to re-write their code. We implement vAttention in the vLLM serving stack to show that it also helps improve decode throughput by up to 1.99x over vLLM, and the end-to-end serving throughput by up to 1.22x and 1.29x, compared to using the state-of-the-art PagedAttention based kernels of FlashAttention and FlashInfer.
Read more7/15/2024

0
vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
Jiale Xu, Rui Zhang, Cong Guo, Weiming Hu, Zihan Liu, Feiyang Wu, Yu Feng, Shixuan Sun, Changxu Shao, Yuhong Guo, Junping Zhao, Ke Zhang, Minyi Guo, Jingwen Leng
Large Language Models (LLMs) are widely used across various domains, processing millions of daily requests. This surge in demand poses significant challenges in optimizing throughput and latency while keeping costs manageable. The Key-Value (KV) cache, a standard method for retaining previous computations, makes LLM inference highly bounded by memory. While batching strategies can enhance performance, they frequently lead to significant memory fragmentation. Even though cutting-edge systems like vLLM mitigate KV cache fragmentation using paged Attention mechanisms, they still suffer from inefficient memory and computational operations due to the tightly coupled page management and computation kernels. This study introduces the vTensor, an innovative tensor structure for LLM inference based on GPU virtual memory management (VMM). vTensor addresses existing limitations by decoupling computation from memory defragmentation and offering dynamic extensibility. Our framework employs a CPU-GPU heterogeneous approach, ensuring efficient, fragmentation-free memory management while accommodating various computation kernels across different LLM architectures. Experimental results indicate that vTensor achieves an average speedup of 1.86x across different models, with up to 2.42x in multi-turn chat scenarios. Additionally, vTensor provides average speedups of 2.12x and 3.15x in kernel evaluation, reaching up to 3.92x and 3.27x compared to SGLang Triton prefix-prefilling kernels and vLLM paged Attention kernel, respectively. Furthermore, it frees approximately 71.25% (57GB) of memory on the NVIDIA A100 GPU compared to vLLM, enabling more memory-intensive workloads.
Read more7/23/2024

0
Beyond KV Caching: Shared Attention for Efficient LLMs
Bingli Liao, Danilo Vasconcellos Vargas
The efficiency of large language models (LLMs) remains a critical challenge, particularly in contexts where computational resources are limited. Traditional attention mechanisms in these models, while powerful, require significant computational and memory resources due to the necessity of recalculating and storing attention weights across different layers. This paper introduces a novel Shared Attention (SA) mechanism, designed to enhance the efficiency of LLMs by directly sharing computed attention weights across multiple layers. Unlike previous methods that focus on sharing intermediate Key-Value (KV) caches, our approach utilizes the isotropic tendencies of attention distributions observed in advanced LLMs post-pretraining to reduce both the computational flops and the size of the KV cache required during inference. We empirically demonstrate that implementing SA across various LLMs results in minimal accuracy loss on standard benchmarks. Our findings suggest that SA not only conserves computational resources but also maintains robust model performance, thereby facilitating the deployment of more efficient LLMs in resource-constrained environments.
Read more7/19/2024
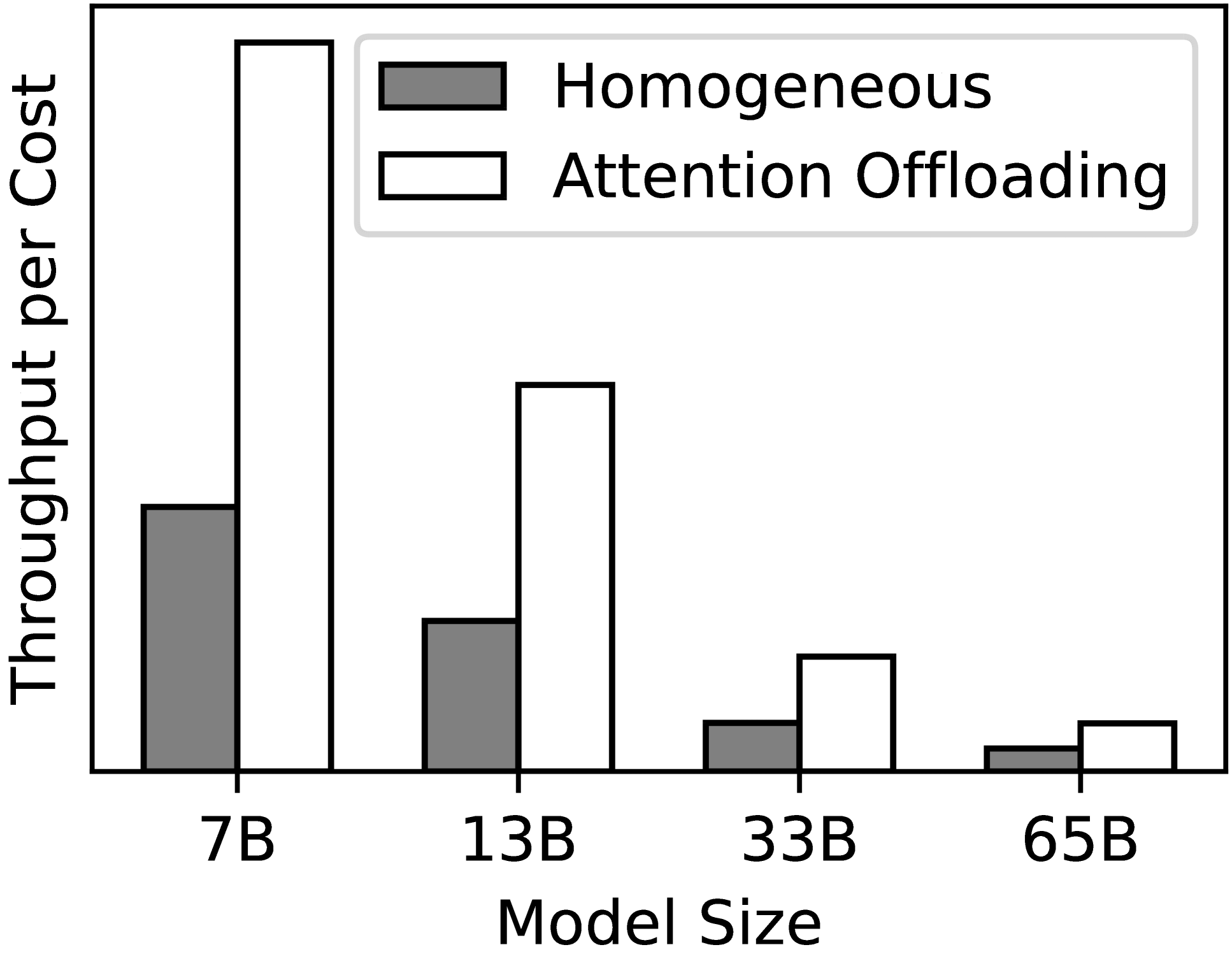
0
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Read more5/6/2024