vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving

0

Sign in to get full access
Overview
- The paper proposes a system called "vTensor" for efficiently serving large language models (LLMs) by managing their tensor computations flexibly.
- vTensor aims to improve the performance and scalability of LLM serving by dynamically allocating and managing tensor resources.
- Key features include on-demand tensor allocation, dynamic memory management, and tensor sharing among model instances.
Plain English Explanation
The paper introduces a new system called "vTensor" that aims to make it easier and more efficient to serve large language models (LLMs) - the powerful AI models that power many modern AI applications.
LLMs require a lot of computing power and memory to run, which can make it challenging to deploy them in real-world applications. vTensor tries to address this by providing a more flexible and dynamic way to manage the underlying tensor computations that LLMs rely on.
Some of the key ideas in vTensor include:
-
On-demand tensor allocation: vTensor can allocate tensor resources as needed, rather than pre-allocating a fixed amount of memory. This allows it to be more efficient and avoid wasting resources.
-
Dynamic memory management: vTensor can dynamically adjust the memory usage of tensors, expanding or shrinking them as needed. This helps it adapt to the changing computational demands of LLMs.
-
Tensor sharing: vTensor enables multiple instances of an LLM to share tensor resources, rather than each instance having its own dedicated memory. This can significantly reduce the overall memory footprint.
By incorporating these flexible tensor management techniques, the authors believe vTensor can improve the performance and scalability of LLM serving, making it easier to deploy these powerful AI models in real-world applications.
Technical Explanation
The paper introduces a system called "vTensor" that aims to enable more efficient serving of large language models (LLMs) by providing flexible management of the underlying tensor computations.
The key technical ideas behind vTensor include:
-
On-demand Tensor Allocation: Rather than pre-allocating a fixed amount of memory for tensors, vTensor can dynamically allocate tensor resources as needed during inference. This helps avoid wasting memory when not all tensors are actively used.
-
Dynamic Memory Management: vTensor can dynamically adjust the memory usage of tensors, expanding or shrinking them as required by the LLM computations. This allows it to adapt to the changing computational demands of the model.
-
Tensor Sharing: vTensor enables multiple instances of an LLM to share tensor resources, rather than each instance having its own dedicated memory. This can significantly reduce the overall memory footprint and improve efficiency.
The paper evaluates vTensor's performance through a series of experiments, comparing it to existing LLM serving approaches. The results show that vTensor can provide significant improvements in terms of memory usage, latency, and throughput, especially for large models and high concurrency scenarios.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the vTensor system, providing compelling evidence for its benefits in serving large language models efficiently. However, a few potential limitations or areas for further research are worth considering:
-
Generalization to Other Model Types: While the focus is on LLMs, it would be interesting to see how well the vTensor approach could generalize to other types of large AI models, such as vision transformers or deep reinforcement learning agents.
-
Integration with Existing Serving Frameworks: The paper does not discuss how vTensor might integrate with or complement existing LLM serving frameworks, such as Triton or TensorFlow Serving. Exploring these integration points could make vTensor more practical for real-world deployment.
-
Fault Tolerance and Reliability: The paper does not address how vTensor might handle failures or ensure reliable serving of LLMs, which is an important consideration for production systems. Investigating mechanisms for fault tolerance and high availability would be a valuable next step.
-
Scalability Limits: While the experiments demonstrate impressive performance at scale, it's unclear what the ultimate limits of vTensor's scalability might be, particularly as model sizes and deployment requirements continue to grow. Further research into the scalability characteristics would help better understand the system's long-term potential.
Overall, the vTensor system presented in this paper represents a significant advancement in the efficient serving of large language models, and the authors have done an excellent job of designing and evaluating the approach. Addressing the areas mentioned above could further strengthen the system and its real-world applicability.
Conclusion
The vTensor system proposed in this paper represents an important step forward in enabling the efficient serving of large language models (LLMs) in real-world applications. By introducing flexible tensor management techniques, including on-demand allocation, dynamic memory adjustment, and tensor sharing, vTensor can significantly improve the performance and scalability of LLM serving.
The experimental results demonstrate the substantial benefits of vTensor, particularly in terms of reduced memory usage, lower latency, and higher throughput. These improvements are crucial for deploying powerful LLMs in a wide range of applications, from language assistants to content generation and decision support systems.
While the paper focuses on LLMs, the core ideas behind vTensor could potentially be applied to other types of large AI models as well, further expanding its impact. Continued research into areas like integration with existing serving frameworks, fault tolerance, and long-term scalability could help solidify vTensor's position as a key enabler for the widespread adoption of advanced AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
Jiale Xu, Rui Zhang, Cong Guo, Weiming Hu, Zihan Liu, Feiyang Wu, Yu Feng, Shixuan Sun, Changxu Shao, Yuhong Guo, Junping Zhao, Ke Zhang, Minyi Guo, Jingwen Leng
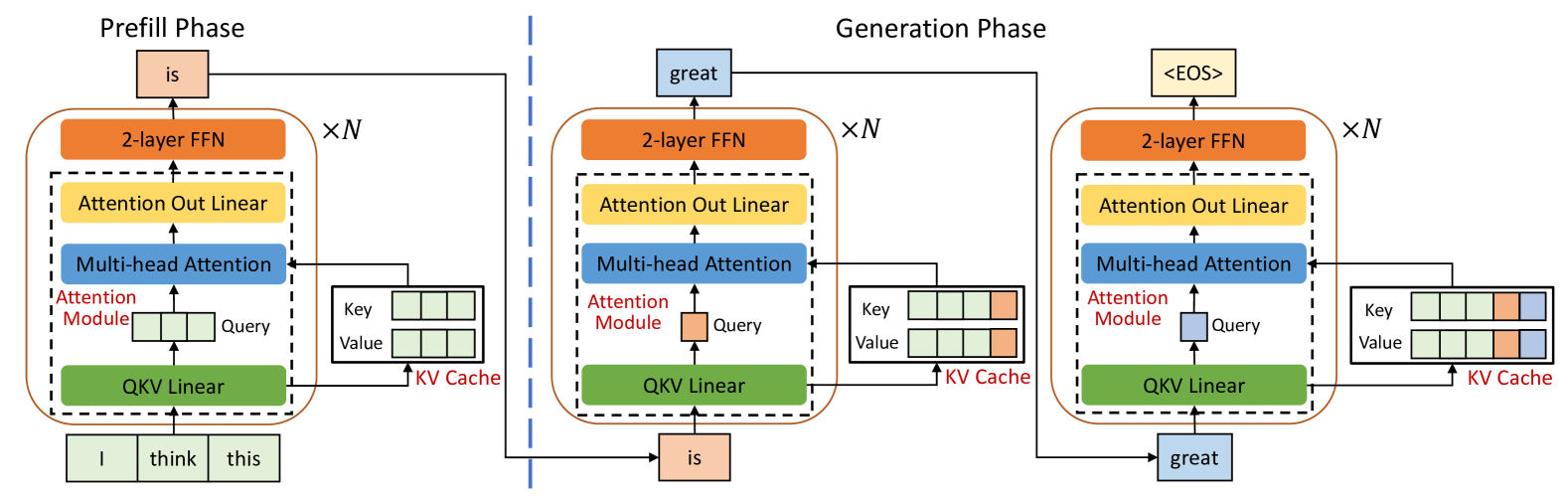
Large Language Models (LLMs) are widely used across various domains, processing millions of daily requests. This surge in demand poses significant challenges in optimizing throughput and latency while keeping costs manageable. The Key-Value (KV) cache, a standard method for retaining previous computations, makes LLM inference highly bounded by memory. While batching strategies can enhance performance, they frequently lead to significant memory fragmentation. Even though cutting-edge systems like vLLM mitigate KV cache fragmentation using paged Attention mechanisms, they still suffer from inefficient memory and computational operations due to the tightly coupled page management and computation kernels. This study introduces the vTensor, an innovative tensor structure for LLM inference based on GPU virtual memory management (VMM). vTensor addresses existing limitations by decoupling computation from memory defragmentation and offering dynamic extensibility. Our framework employs a CPU-GPU heterogeneous approach, ensuring efficient, fragmentation-free memory management while accommodating various computation kernels across different LLM architectures. Experimental results indicate that vTensor achieves an average speedup of 1.86x across different models, with up to 2.42x in multi-turn chat scenarios. Additionally, vTensor provides average speedups of 2.12x and 3.15x in kernel evaluation, reaching up to 3.92x and 3.27x compared to SGLang Triton prefix-prefilling kernels and vLLM paged Attention kernel, respectively. Furthermore, it frees approximately 71.25% (57GB) of memory on the NVIDIA A100 GPU compared to vLLM, enabling more memory-intensive workloads.
Read more7/23/2024
⛏️
0
vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ramjee, Ashish Panwar
Efficient management of GPU memory is essential for high throughput LLM inference. Prior systems used to reserve KV-cache memory ahead-of-time that resulted in wasted capacity due to internal fragmentation. Inspired by demand paging, vLLM proposed PagedAttention to enable dynamic memory allocation for KV-cache. This approach eliminates fragmentation and improves serving throughout. However, to be able to allocate physical memory dynamically, PagedAttention changes the layout of KV-cache from contiguous virtual memory to non-contiguous virtual memory. As a consequence, one needs to rewrite the attention kernels to support paging, and implement a memory manager in the serving framework. This results in both performance and programming overheads, as well as portability challenges in adopting state-of-the-art attention kernels. In this paper, we propose vAttention, a new approach for dynamic KV-cache memory management. In contrast to PagedAttention, vAttention stores KV-cache in contiguous virtual memory and leverages OS support for on-demand allocation of physical memory. vAttention thus enables one to use state-of-the art attention kernels out-of-the-box by adding support for dynamic allocation of physical memory without having to re-write their code. We implement vAttention in the vLLM serving stack to show that it also helps improve decode throughput by up to 1.99x over vLLM, and the end-to-end serving throughput by up to 1.22x and 1.29x, compared to using the state-of-the-art PagedAttention based kernels of FlashAttention and FlashInfer.
Read more7/15/2024
🤯
72
Efficient LLM inference solution on Intel GPU
Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu, Peng Zhao
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
Read more6/26/2024
0
Stateful Large Language Model Serving with Pensieve
Lingfan Yu, Jinyang Li
Large Language Models (LLMs) are wildly popular today and it is important to serve them efficiently. Existing LLM serving systems are stateless across requests. Consequently, when LLMs are used in the common setting of multi-turn conversations, a growing log of the conversation history must be processed alongside any request by the serving system at each turn, resulting in repeated processing. In this paper, we design Pensieve, a system optimized for multi-turn conversation LLM serving. Pensieve maintains the conversation state across requests by caching previously processed history to avoid duplicate processing. Pensieve's multi-tier caching strategy can utilize both GPU and CPU memory to efficiently store and retrieve cached data. Pensieve also generalizes the recent PagedAttention kernel to support attention between multiple input tokens with a GPU cache spread over non-contiguous memory. Our evaluation shows that Pensieve can achieve 13-58% more throughput compared to vLLM and TensorRT-LLM and significantly reduce latency.
Read more5/29/2024